Hadoop技术学习后心得
Hadoop技术学习心得与总结
在完成Hadoop技术相关课程的学习后,我不仅系统掌握了大数据处理的核心框架知识,更在实践操作中深化了对“分布式存储与计算”思想的理解。从最初对“大数据”概念的模糊认知,到能够独立搭建Hadoop集群、编写MapReduce程序处理实际数据,这段学习经历让我切实感受到了技术落地的魅力。学习Hadoop技术的过程中,专业课程提供了系统的理论知识和实践机会。通过课程学习,对分布式计算、大数据存储与处理有了更深入的理解。Hadoop的核心组件如HDFS、MapReduce、YARN等,从概念到实现逐步掌握。实际项目开发中,Hadoop的高容错性和扩展性为处理海量数据提供了可靠支持。
实践环节中,通过搭建Hadoop集群环境,配置参数优化性能,编写MapReduce程序解决实际问题,积累了宝贵的经验。例如,使用Hadoop处理日志分析任务时,通过分区和合并策略显著提升了效率。代码实现过程中,对数据分片、任务调度等底层机制有了更直观的认识。
MapReduce是Hadoop的分布式计算框架,它将复杂的计算任务拆解为“Map(映射)”和“Reduce(归约)”两个阶段,实现并行计算。Map阶段负责将输入数据切片后进行局部处理(如过滤、提取关键信息),输出中间键值对;Reduce阶段负责汇总Map阶段的中间结果,对相同键的数据进行聚合计算(如求和、计数)。
通过学习MapReduce,我理解了分布式计算的核心思想:将任务分配到多个节点并行执行,再汇总结果,从而大幅提升计算效率。同时也认识到其局限性,比如实时性差、不适合迭代计算,这也为后续学习Spark等框架埋下了伏笔。
集群搭建:细节决定成败
搭建Hadoop集群的核心是配置文件的优化,尤其是以下几个关键配置文件:
-
core-site.xml:配置HDFS的默认文件系统和NameNode地址;
-
hdfs-site.xml:配置数据块副本数量、DataNode数据存储路径;
-
mapred-site.xml:配置MapReduce的框架类型(指定为YARN);
-
yarn-site.xml:配置YARN的ResourceManager地址和节点管理相关参数。
初期搭建时,我曾因SSH免密登录配置失败、JDK环境变量未正确设置、配置文件路径写错等问题导致集群启动失败。通过查看日志文件(Hadoop的日志目录下的hadoop-xxx-namenode-xxx.log)排查问题,逐渐掌握了集群搭建的关键技巧。比如,在完全分布式集群中,必须保证各节点的时钟同步,否则DataNode无法正常注册到NameNode。
项目分析与代码示例
以下是一个简单的MapReduce程序示例,用于统计文本中单词的出现频率:
提取函数 将重复或独立功能的代码块提取为单独的函数。例如成
def calculate_area(width, height):
return width * height
area = calculate_area(10, 5)
定期总结项目经验,分析性能优化点,例如通过调整mapred.reduce.tasks参数优化Reduce任务数量,显著提升了作业执行效率。
使用类封装 将相关数据和操作封装到类中:
class Rectangle:
def __init__(self, width, height):
self.width = width
self.height = height
def area(self):
return self.width * self.height
rect = Rectangle(10, 5)
print(rect.area())
模块化 将代码拆分到不同文件中:
# geometry.py
def area(width, height):
return width * height
# main.py
from geometry import area
print(area(10, 5))
Mapper类:数据拆分与局部处理核心
Mapper类的核心作用是接收输入数据,按业务逻辑进行拆分、过滤和提取,输出中间键值对。本案例中,就是从日志行中提取IP地址,并为每个IP标记计数1(后续Reduce阶段汇总)。
import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * Mapper输入:key是行偏移量(LongWritable),value是一行日志数据(Text) * Mapper输出:key是IP地址(Text),value是计数1(LongWritable) * 泛型说明:<输入key类型, 输入value类型, 输出key类型, 输出value类型> */ public class LogCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> { // 定义输出的value为1,采用final static修饰避免循环中重复创建对象,提升性能 private final static LongWritable one = new LongWritable(1); // 定义存储IP地址的Text对象,提前创建复用 private Text ipText = new Text(); /** * map方法:Map阶段核心处理方法,每一行输入数据都会触发一次map方法调用 * @param key 输入key:行偏移量(表示当前行在文件中的位置,本案例无需使用) * @param value 输入value:当前行的日志数据 * @param context 上下文对象:用于传递数据(将map输出的键值对写入后续流程) * @throws IOException 输入输出异常 * @throws InterruptedException 线程中断异常 */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1. 将Text类型的日志行转换为String类型,方便后续拆分 String line = value.toString(); // 2. 按空格拆分日志行(假设日志格式为:IP 时间 访问路径 状态码 ...) String[] fields = line.split(" "); // 3. 数据校验:避免日志格式不规范导致数组越界异常 if (fields.length > 0) { // 4. 提取数组第一个元素,即IP地址 String ip = fields[0]; // 5. 将提取的IP地址设置到Text对象中(Hadoop推荐使用自有数据类型,适配分布式序列化) ipText.set(ip); // 6. 通过上下文对象输出键值对:<IP地址, 1> context.write(ipText, one); } } }
Reducer类:数据汇 总与结果计算核心
总与结果计算核心
Reducer类的核心作用是接收Mapper阶段输出的中间键值对,将相同key(本案例中是相同IP)对应的value进行聚合计算(本案例是累加计数),最终输出最终结果。
import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * Reducer输入:key是IP地址(Text),value是该IP对应的所有1的集合(Iterable<LongWritable>) * Reducer输出:key是IP地址(Text),value是该IP的总访问次数(LongWritable) * 泛型说明:<输入key类型, 输入value类型, 输出key类型, 输出value类型> */ public class LogCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> { /** * reduce方法:Reduce阶段核心处理方法,每一个不同的key都会触发一次reduce方法调用 * @param key 输入key:IP地址 * @param values 输入value:该IP对应的所有计数1的集合(Iterable表示可迭代,存储多个LongWritable对象) * @param context 上下文对象:用于输出最终的键值对结果 * @throws IOException 输入输出异常 * @throws InterruptedException 线程中断异常 */ @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { // 1. 定义累加变量sum,初始化为0,用于存储当前IP的总访问次数 long sum = 0; // 2. 遍历当前IP对应的所有计数1,进行累加 for (LongWritable value : values) { // 将LongWritable类型转换为long类型,获取计数1并累加 sum += value.get(); } // 3. 通过上下文对象输出最终结果:<IP地址, 总访问次数> context.write(key, new LongWritable(sum)); } }
Driver类:程序入口与任务配置核心
Driver类是整个MapReduce程序的入口,核心作用是配置整个MapReduce任务的相关参数,指定Mapper和Reducer类、输入输出数据类型、输入输出路径等,最终提交任务并监控执行状态。
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class LogCountDriver { public static void main(String[] args) throws Exception { // 1. 获取Hadoop配置信息对象(Configuration):加载hadoop集群的配置文件(如core-site.xml等) Configuration conf = new Configuration(); // 2. 创建Job对象:代表一个MapReduce任务,参数1为配置信息,参数2为任务名称(自定义,用于区分任务) Job job = Job.getInstance(conf, "log_ip_count"); // 3. 设置Driver类的路径(至关重要!集群环境中需要通过该路径找到Driver类,否则任务执行失败) job.setJarByClass(LogCountDriver.class); // 4. 设置当前任务的Mapper类和Reducer类 job.setMapperClass(LogCountMapper.class); job.setReducerClass(LogCountReducer.class); // 5. 设置Mapper阶段输出的key和value的数据类型(需与Mapper类的泛型输出一致) job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); // 6. 设置最终输出的key和value的数据类型(需与Reducer类的泛型输出一致,也是最终写入文件的数据类型) job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); // 7. 设置输入文件路径和输出文件路径(路径从命令行参数获取,args[0]为输入路径,args[1]为输出路径) // 注意:输出路径必须是不存在的路径,否则Hadoop会报错(避免覆盖已有数据) FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 8. 提交任务并等待执行完成:参数true表示在控制台打印任务执行日志 // 任务执行成功返回true,失败返回false,根据返回结果退出程序(0表示成功,1表示失败) boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } }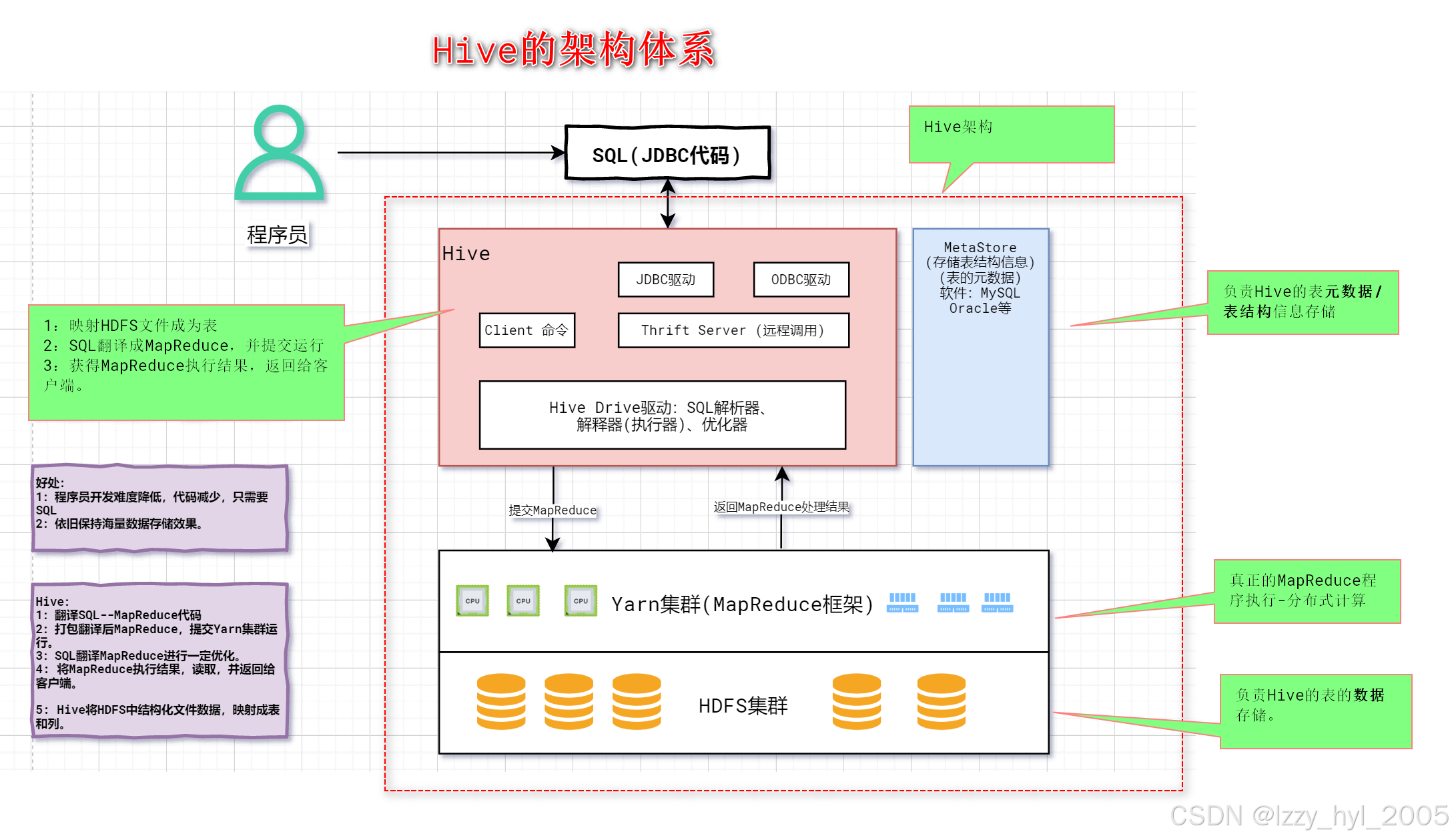
实用工具
代码分析工具 使用静态分析工具如pylint、flake8等检查代码质量:
pylint your_script.py
flake8 your_script.py
# 计算平方和
def square_sum(numbers):
total = 0
for num in numbers: # 遍历数字列表
total += num ** 2 # 累加平方值
return total
变量与函数说明 列出所有变量和函数,说明其用途。例如:
numbers: 输入的数字列表total: 存储累加结果的变量square_sum(): 计算列表元素平方和的函数
流程图绘制 用流程图展示代码的执行流程。适用于复杂逻辑的算法。
print(square_sum([1, 2, 3])) # 应输出14
print(square_sum([])) # 应输出0
复杂度分析 评估时间复杂度和空间复杂度。上述示例为O(n)时间复杂度和O(1)空间复杂度。
依赖关系 列出代码依赖的库或外部资源。例如需要numpy等第三方库时需注明。
边界条件 说明特殊输入情况的处理方式,如空列表、非法输入等。
通过本次Hadoop课程的学习,我不仅掌握了分布式存储与计算的核心技术,更培养了“分布式思维”——在面对海量数据问题时,能够从“拆分-并行-汇总”的角度思考解决方案。同时,实践过程中的踩坑经历也让我明白,大数据技术的学习必须“理论联系实际”,只有亲手操作,才能真正理解技术的底层逻辑。
当然,Hadoop只是大数据生态的基础。后续,我计划深入学习Hadoop生态的其他组件,如Hive(数据仓库工具)、HBase(分布式数据库)、Spark(快速计算框架)等,进一步拓宽自己的大数据技术栈。同时,我也会持续在CSDN分享自己的学习心得和实践项目,与各位开发者共同成长。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)