Transformer位置嵌入详解:从基础到RoPE解决词序感知难题
本文介绍Transformer模型中解决词序感知问题的三种位置嵌入方法:函数编码(sin/cos)、可学习位置嵌入和旋转位置编码(RoPE)。RoPE通过旋转词向量捕捉相对位置关系,配合PI和YaRN扩展方法可处理长文本输入。这些技术使模型能够理解语言中的顺序信息,解决了Transformer无法感知词序的关键缺陷。
本文介绍Transformer模型中解决词序感知问题的三种位置嵌入方法:函数编码(sin/cos)、可学习位置嵌入和旋转位置编码(RoPE)。RoPE通过旋转词向量捕捉相对位置关系,配合PI和YaRN扩展方法可处理长文本输入。这些技术使模型能够理解语言中的顺序信息,解决了Transformer无法感知词序的关键缺陷。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
1
盲点:Transformer无法“感知顺序”
在上一节中,我们介绍了Transformer强大的多头注意力机制。多头自注意力可以让模型灵活地建立起句子中任意两词(Token)之间的联系,无论它们距离远近。然而,它有一个“盲点”:对词的顺序不敏感。换言之:
如果不给模型任何顺序信息,那么注意力层眼中的输入其实是无序的词集合
想象你把“我”、“爱”、“你”写在三张牌上按顺序交给Transformer ,但他只看到一个集合 — “我、爱、你”都在这儿。如果你把三张牌的位置随便打乱,对它来说内容并没有变!
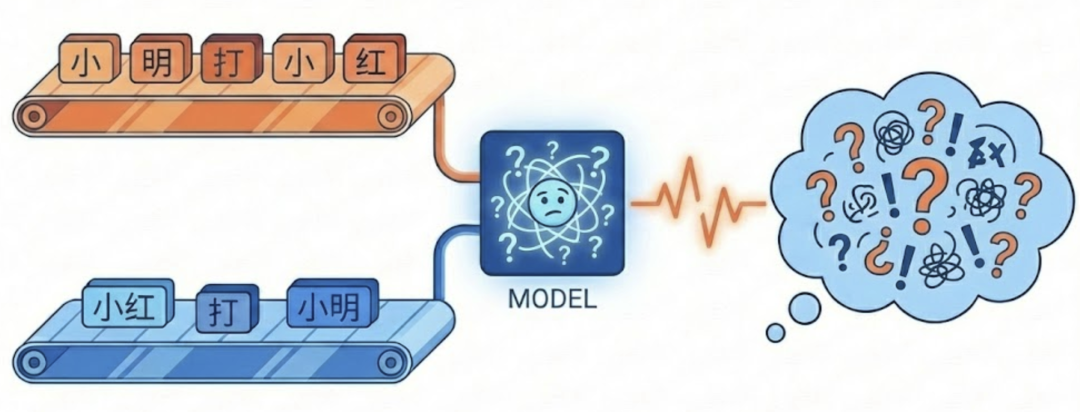
这在自然语言的处理中就会有问题: “小明打小红” 和 “小红打小明” 在 Transformer眼里会非常接近 — 都有“小明”、“小红”和“打”,而这并不符合其真实语义。
为了解决这个问题,我们需要给每个词贴上一个“位置标签”。这就是位置嵌入(Positional Embedding)要做的事。
2
问题:为什么不简单编号1,2,3?
由于词在Transformer模型中的表示都是”向量”(一串N维的数字)。所以为了贴上位置标签,我们需要给词向量来“叠加”一个位置信息。
你可能会问:“给第 1 个词标上 1,第 10000 个词标上 10000,不就行了吗?”
我们在前面学过词向量(Embedding)是一串很精密的数字,数值通常都不大(比如在 -0.1 到 0.1 附近浮动)。
那“位置是 10000”这种信息,如果你直接塞进向量里,直觉做法是这样:
把位置 pos 变成位置向量 P(pos) = [pos, 0, 0, …],然后和词向量相加。
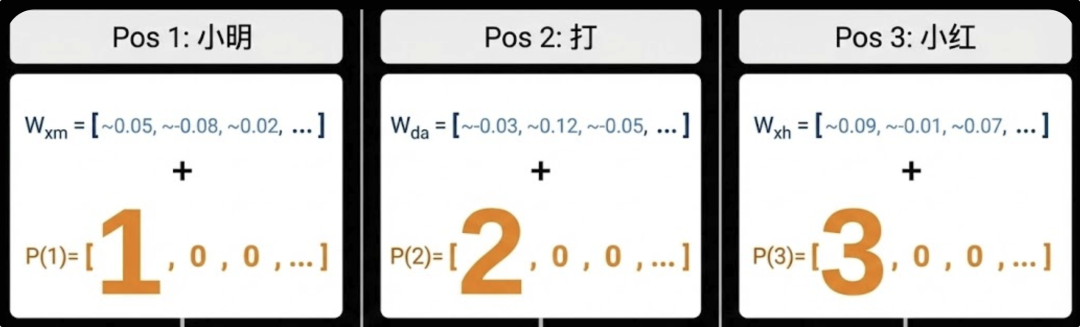
我们用一个3维词向量来举例**(真实模型是几百上千维,但道理一样):**
假设 “苹果” 的词向量是:
E(苹果) = [0.05, -0.02, 0.01]
如果“苹果”出现在第 10000 位,你生成一个代表位置的向量:
P(10000) = [10000, 0, 0]
然后叠加得到:
X = E + P = [10000.05, -0.02, 0.01]
你会发现:代表语义的 0.05 被 10000 完全“淹没”了。模型“听到”的最大信号不再是“苹果”,而是“这是第 10000 位”这种信号。具体到注意力机制里,这种某一维突然变成万级,足以把计算与后续训练整体带偏。
所以正确方法应该是:生成一组数值大小和词向量差不多、但又能代表位置的、维数相同的向量,让它叠加到语义向量上。
3
经典方法一:函数编码
这是 Transformer 模型最开始发明的方法。简单的总结就是:
用一个固定函数,给每个位置算出一个独一无二的“指纹”向量。
具体做法是:用一组不同频率的 sin/cos 函数,把位置 pos 映射成一个 d 维向量;这样每个位置的编码是确定且固定的,同时因为是函数形式,所以理论上可自然延伸到更长序列(至少“能算出来”)。
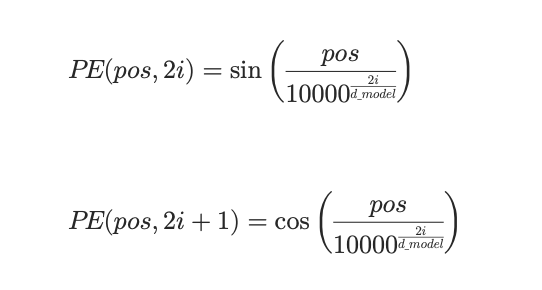
这里:pos是位置(0开始);d_model是向量维度;i是维度索引。很显然对于一个确定的位置(pos),确定的总维度(d_model),计算出的每一维(i)的结果(一个介于-1到1之间的数字)不一样,最后得到一个多维的向量。
如果你还记得sin/cos函数,应该很容易理解,这里生成向量的某一维,其实是某种频率的 sin/cos函数 在 pos 处的取值。特征是:
- 三角函数值范围天然在 [-1, 1],不会出现“10000 碾压语义”的问题
- 不同维度用不同频率,既能区分相邻位置,也能区分远距离位置
继续用同样的 3 维词向量举例:
E(苹果) = [0.05, -0.02, 0.01]
通过上述函数会给位置 10000 的这个词生成一个位置向量,比如:
P_sin(10000) = [0.20, -0.91, 0.03]
叠加后得到:
X = [0.25, -0.93, 0.04]
这种方式下的叠加尺度相当,语义信息不会被“喧宾夺主”。
函数编码的优点是:不受最大位置的上限约束——因为这是函数,你只要有X(位置)就可以算出Y(向量),并且每个位置的结果是固定的。当然缺点也对应:规则是写死的,模型不能自由决定。
4
经典方法二:可学习位置嵌入
这是 BERT 和早期 GPT 采用的方法。它的逻辑非常简单:
不用函数公式,而让模型自己学一套位置编码出来。
假设要训练的模型最长支持 512 个词,我们就准备 512 个“位置向量槽位”,每个槽位都是一条 d 维向量:
- 第 1 位的向量为 P[1]
- 第 2 位的向量为 P[2]
- …依次下去,一直到512位
一开始这些向量是随机的。训练过程中,模型不断调整它们:哪一种 P[pos] 叠加到 token 上能让任务损失更小,它就会把这个位置向量往那个方向“雕刻”。久而久之,这 512 个位置向量就被训练成了“最适合本模型”的一套“坐标”。
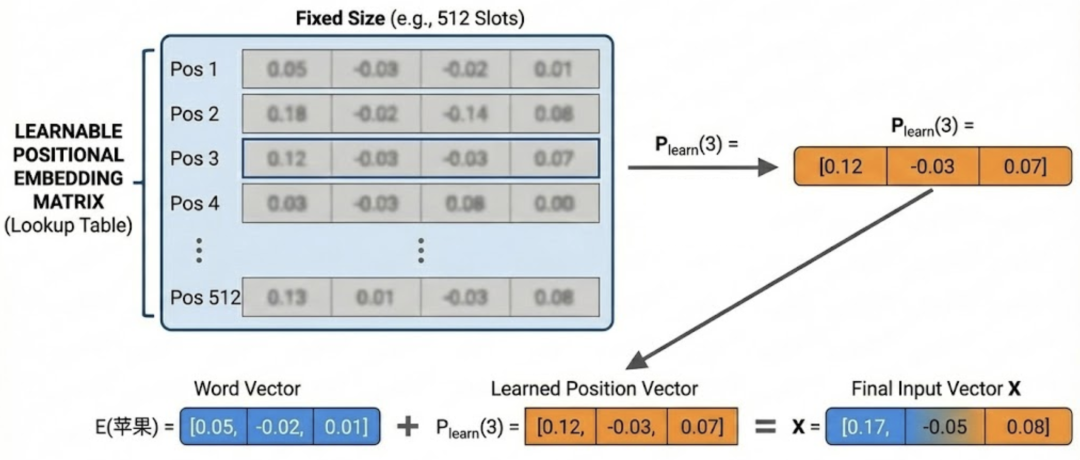
用上面同样的3维词向量举例:
E(苹果) = [0.05, -0.02, 0.01]
现在不再通过函数计算P[pos],而是让模型训练时”学出来“。
比如训练后得到这个P[pos]为:
P_learn(3) = [0.12, -0.03, 0.07]
叠加后得到:
X = [0.17, -0.05, 0.08]
这里与函数编码的区别就在于:这个位置向量是训练出来,更贴合模型需要。
但它的硬伤在于:”槽位“数量是固定的。如果你只准备到 512,那么第 513 位就没有 P[513] 可以查 — 模型就会“傻眼”。这就需要用到改进后的方法。
5
新的主流方法:旋转位置编码(RoPE)
上面两种方法(正弦波、可学习嵌入)都有一个共同点:它们提供的都是绝对位置,即告诉模型“你在第 100 位”。
但在理解语言时,我们更关心相对位置。比如下面句子中的“我”和“吃”:
句子A:“我想去吃饭。”(距离为 3)
句子B:“今天天气不错,于是我想去吃饭。”(距离还是 3)
于是有人设计出一种更聪明的编码,让“相对距离”在注意力计算里显现出来。这就是很多模型大量采用的RoPE(旋转位置编码)。其思想是:
与其把位置向量“加上去”,不如把词向量直接“转个身”。
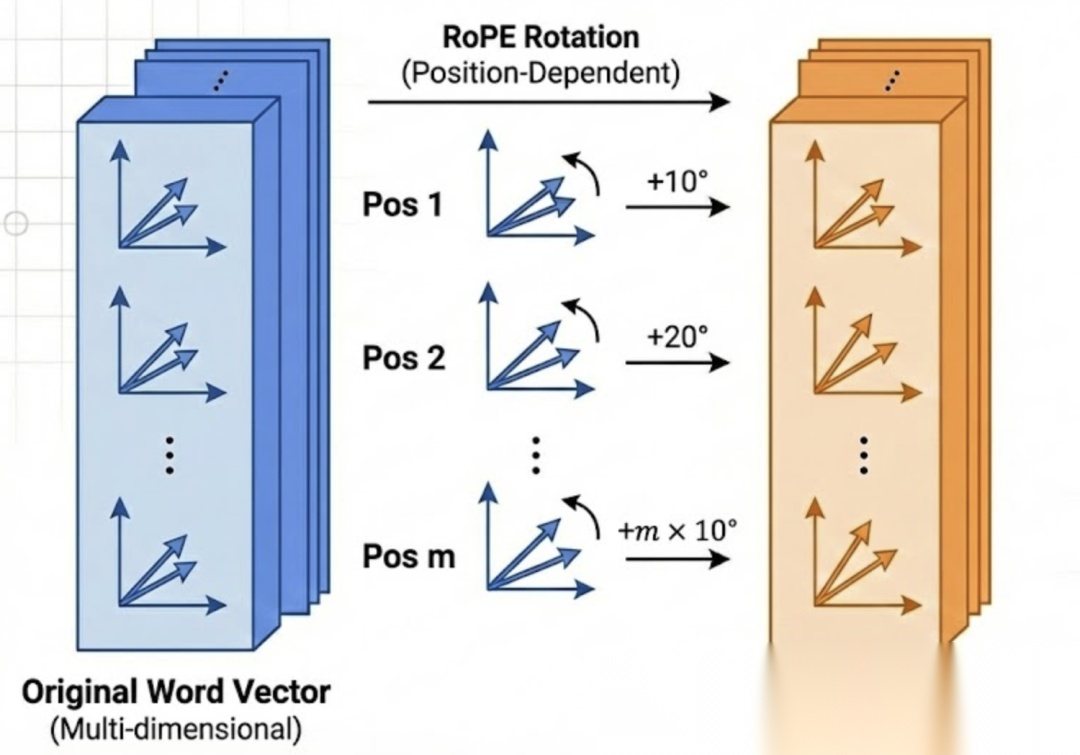
想象词向量是“一个在平面上有方向的箭头”,那么如何让它带有位置信息:
- 第 1 个位置:把箭头逆时针转 10 度
- 第 2 个位置:把箭头逆时针转 20 度
- …
- 第 m 个位置:把箭头逆时针转 m × 10 度
当模型计算两个词的关联度时,就会发现(数学公式里的体现):
- A 转了 100 度(第10位)
- B 转了 120 度(第12位)
- 计算结果只和“差值 20度”有关!
所以模型不需要知道 A 和 B 具体位置,它只感受到:“那个词在我后面转了20度的地方。”这让 RoPE 擅长捕捉到词与词之间的相对关系。

注意,真实训练中,高维向量会分成N组二维向量,在各自的二维子空间里“旋转”,且不同子空间会有不同的“旋转速度”。
继续上面的3维向量的例子:
E(苹果) = [0.05, -0.02, 0.01]
以前两维作为一组二维坐标。那么在位置 pos 上,可以对这个(x,y)旋转一个角度 θ(pos),得到(x’, y’):
那么X = [x’, y’, z],就是带有位置pos信息的新向量。
这里的关键不在于你算不算得出 x’、y’,而在于:
当模型去算两个不同位置 token (比如pos1和pos2)的相关性时,数学上会出现一种“对消”— 最终依赖 θ(pos2) - θ(pos1) 这样的差值,也就是相对位移,而不是绝对的位置。
6
最后:如果输入太长,怎么办?
虽然 RoPE 理论上能“无限旋转”,但实际训练时,模型可能只见过某个长度范围内的旋转角度,忽然你扔给它一本《红楼梦》,比如有些词需要“转 7200 度”,模型没见过这么大的“旋转”,就容易跑偏,注意力漂移等。
为了让模型能读更长的文本,工程师们在 RoPE 基础上常用 PI 和 YaRN 这类扩窗技巧。
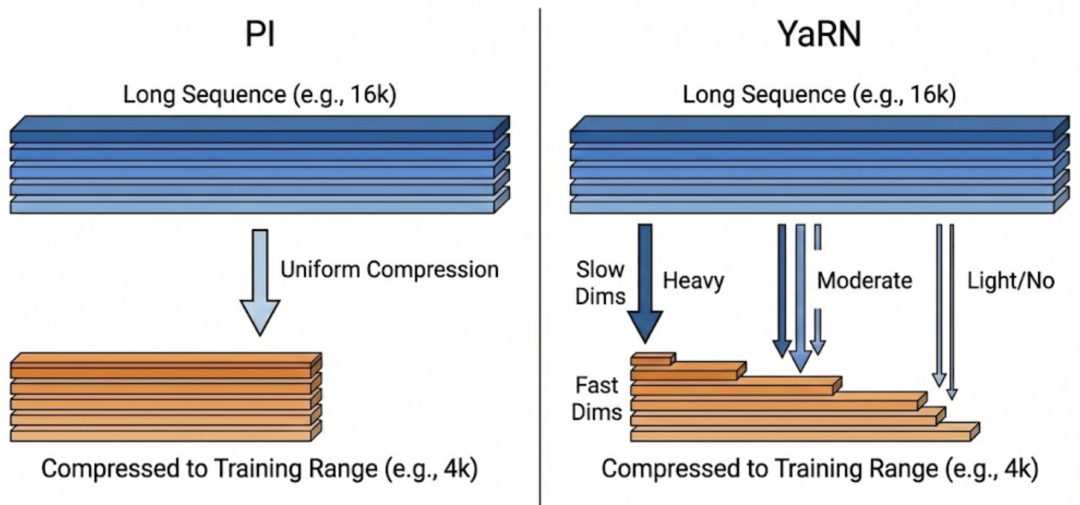
- PI(位置插值)
PI 的本质是:
把“很长的真实位置”压缩成“训练时见过的较短位置”(乘一个缩放因子)。
比如:
假设模型训练时最多见过 4k 长度。现在你要它读 16k 的文本。
PI 的方法是:
真实位置:0 ~ 16000
喂给模型的位置:0 ~ 4000
换句话说:把位置整体除以 4
于是,原本第 12000 位就变成第 3000 位,“缩”到训练范围内。
这就像把一张很长的“道路地图”等比例缩小:路还是那条路,但“刻度”变小。好处是模型不容易“看花”,坏处是“分辨率”下降 — 细微位置关系没那么精确。
- YaRN(RoPE的又一扩展方法)
YaRN的思路更像一种“智能压缩”:
不是所有维度都同样压缩 — “慢”的更敢压,“快”的少压甚至不压。
不是所有维度都一刀切地压缩,而是对不同维度做不同力度的调整。直觉上,慢变化的维度更像负责全局稳定,可以压得更狠;快变化的维度更像承载局部细节,压得少一些甚至尽量保留。
还是训练4k,推理16k的例子:
* PI:所有维度旋转都统一“慢 4 倍”(一刀切)
* YaRN则是:
“慢”维度:慢 4 倍甚至更多(保全局稳定)
“快”维度:慢 1.5~2 倍(保局部清晰)
这样既能覆盖更长范围的输入,又尽量不丢掉局部清晰度。
现在,我们已经理清了 Transformer 识别位置的几代方法:函数编码、可学习编码、RoPE宣传+PI等工程技巧。下一篇我们将结合前面学习的注意力、归一化、残差等方法,看看传说中GPT架构到底是怎样的。
欢迎继续关注。
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐


 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)