《sklearn机器学习》——交叉验证迭代器
本文介绍了scikit-learn中主要的交叉验证迭代器,包括KFold、StratifiedKFold、LeaveOneOut等。它们通过不同的数据划分策略支持模型评估和超参数调优,适用于分类、回归、时间序列等多种场景。文章详细比较了各迭代器的特点和使用方法,并提供了代码示例。最后给出了根据数据特点选择合适迭代器的建议,强调避免数据泄露和确保实验可复现的重要性。正确选择交叉验证策略是获得可靠模型
sklearn 交叉验证迭代器
在 scikit-learn (sklearn) 中,交叉验证迭代器(Cross-Validation Iterators)是一组用于生成训练集和验证集索引的工具。它们是 model_selection 模块的核心组件,决定了数据如何被分割,从而支持模型评估、超参数调优等任务。
这些迭代器实现了不同的数据划分策略,以适应各种数据类型和问题场景。下面详细介绍 sklearn 中主要的交叉验证迭代器。
一、核心概念
所有交叉验证迭代器都遵循相同的接口:
- 输入:数据集大小
n_samples。 - 输出:一个生成器(generator),每次迭代返回一对
(train_indices, test_indices)的 NumPy 数组。 - 用途:可用于
cross_val_score,GridSearchCV等函数的cv参数。
二、主要交叉验证迭代器
1. KFold - 标准 K 折交叉验证
用途:最基础的 K 折 CV,适用于类别均衡的分类或回归问题。
工作方式:
- 将数据集划分为
k个大小基本相等的折(folds)。 - 每次使用其中 1 折作为验证集,其余
k-1折作为训练集。 - 重复
k次,确保每折都恰好被用作一次验证集。
参数:
n_splits:折数,默认为 5。shuffle:是否在划分前打乱数据顺序。建议设为True,除非数据有时间顺序。random_state:随机种子,确保结果可复现。
代码示例:
from sklearn.model_selection import KFold
import numpy as np
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([1, 2, 3, 4, 5])
kf = KFold(n_splits=3, shuffle=True, random_state=42)
for train_index, test_index in kf.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
2. StratifiedKFold - 分层 K 折交叉验证
用途:分类任务的首选,尤其当类别分布不均衡时。
工作方式:
与 KFold 类似,但确保每一折中各类别的比例与原始数据集大致相同。
避免某些折中某个类别样本过少或缺失,导致评估偏差。
为什么重要?
例如:一个二分类数据集中正类占 10%。使用普通 KFold 可能在某折中正类样本极少,导致模型无法学习或评估失真。
StratifiedKFold 保证每折中正类比例都接近 10%。
代码示例:
python
深色版本
from sklearn.model_selection import StratifiedKFold
y = np.array([0, 0, 0, 1, 1]) # 不均衡数据
skf = StratifiedKFold(n_splits=2, shuffle=True, random_state=42)
for train_index, test_index in skf.split(X, y):
print("TRAIN:", train_index, "TEST:", test_index)
print("Y_TRAIN:", y[train_index], "Y_TEST:", y[test_index])
3. LeaveOneOut (LOO) - 留一法交叉验证
用途:样本量非常小(如 < 100)时使用。
工作方式:
每次留出一个样本作为验证集,其余所有样本作为训练集。
重复 n_samples 次。
优缺点:
✅ 几乎无偏估计(训练集最大)。
❌ 计算成本极高(训练 n 次),且方差可能很大(单个样本影响大)。
代码示例:
python
深色版本
from sklearn.model_selection import LeaveOneOut
loo = LeaveOneOut()
for train_index, test_index in loo.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
4. LeavePOut - 留 P 法交叉验证
用途:比 LOO 更一般化,但计算更昂贵。
工作方式:
每次留出 p 个样本作为验证集,其余所有样本作为训练集。
所有可能的 p 个样本组合都会被尝试,因此总次数为 C(n, p)。
p=1 时退化为 LOO。
注意:当 n 或 p 稍大时,组合数爆炸,极少在实际中使用。
5. ShuffleSplit - 随机划分分割
用途:灵活的随机抽样 CV,适合大数据集或需要控制训练/验证比例时。
工作方式:
不强制使用所有样本。
每次迭代从数据中随机抽取指定比例作为训练集,其余作为验证集(可重叠)。
可指定迭代次数 n_splits。
参数:
n_splits:迭代次数。
train_size, test_size:训练/验证集比例。
优点:
可独立控制训练集大小。
适用于大数据,无需完整 K 折。
代码示例:
python
深色版本
from sklearn.model_selection import ShuffleSplit
ss = ShuffleSplit(n_splits=3, test_size=0.25, random_state=0)
for train_index, test_index in ss.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
6. StratifiedShuffleSplit - 分层随机划分
用途:ShuffleSplit 的分层版本,用于类别不均衡的分类任务。
工作方式:
在每次随机划分时,保持训练集和验证集中各类别的比例一致。
适用场景:
大数据集上的分层 CV。
需要固定验证集大小且保持类别平衡。
7. GroupKFold - 组 K 折交叉验证
用途:当数据中存在组结构(如:同一用户多次记录、同一病人多个样本),需确保同一组的数据不同时出现在训练和验证集中,防止数据泄露。
工作方式:
根据 groups 数组划分,确保一个组的所有样本要么全在训练集,要么全在验证集。
参数:
groups:长度为 n_samples 的数组,表示每个样本所属的组。
代码示例:
python
深色版本
from sklearn.model_selection import GroupKFold
X = [0.1, 0.2, 2.2, 2.4, 2.3, 4.5, 5.7, 5.8]
y = [1, 1, 0, 0, 0, 1, 1, 1]
groups = [1, 1, 2, 2, 2, 3, 3, 3] # 3 个组
gkf = GroupKFold(n_splits=3)
for train_index, test_index in gkf.split(X, y, groups):
print("TRAIN:", train_index, "TEST:", test_index)
print("GROUPS:", groups[test_index])
8. TimeSeriesSplit - 时间序列交叉验证
用途:处理时间序列数据,确保不使用未来数据预测过去。
工作方式:
按时间顺序划分。
每次迭代,训练集是过去的数据,验证集是接下来的一段数据。
训练集逐渐增长(“前滚”交叉验证)。
关键特性:
不打乱数据。
验证集始终在训练集之后。
代码示例:
python
深色版本
from sklearn.model_selection import TimeSeriesSplit
tscv = TimeSeriesSplit(n_splits=3)
for train_index, test_index in tscv.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
输出:
深色版本
TRAIN: [0 1 2] TEST: [3]
TRAIN: [0 1 2 3] TEST: [4]
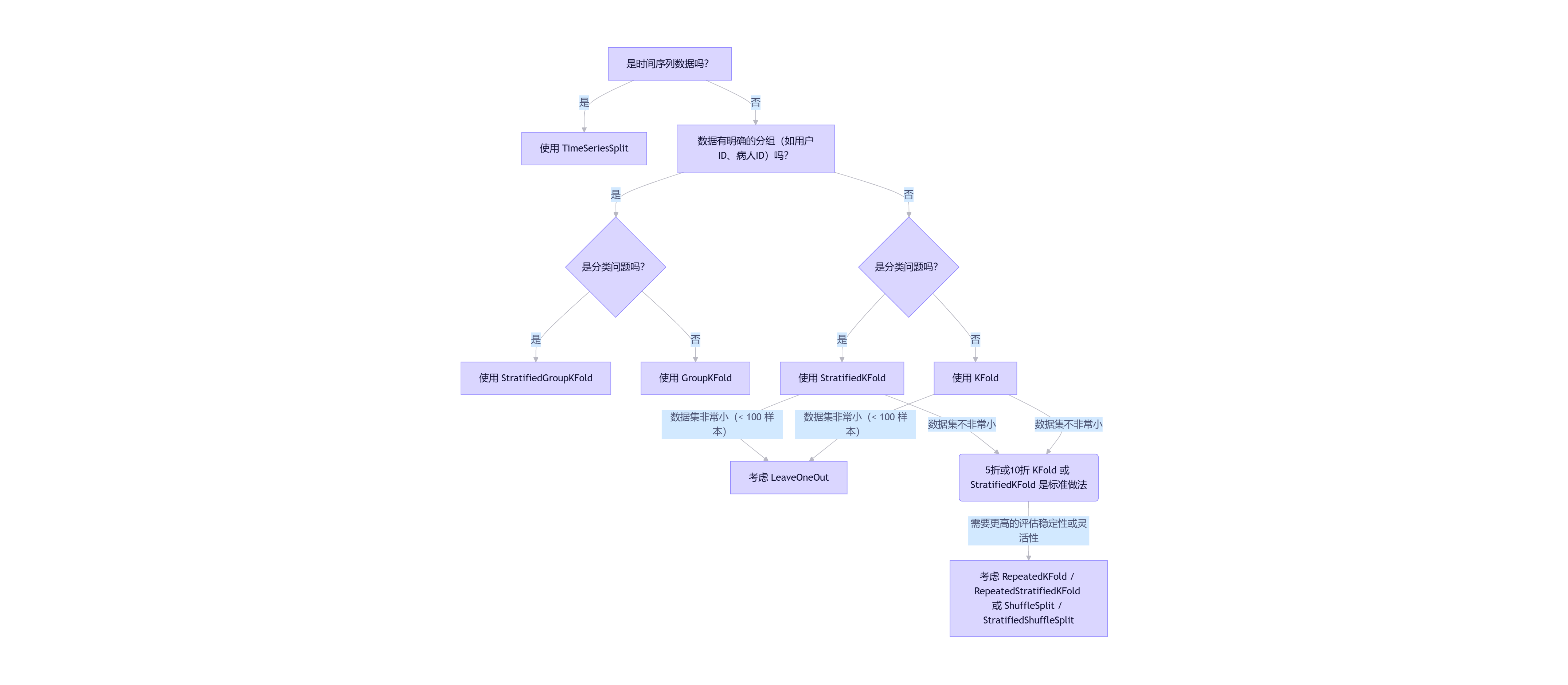
三、如何选择合适的 CV 迭代器?
(1)选择交叉验证迭代器的关键因素
| 因素 | 说明 |
|---|---|
| 数据类型 | 分类任务通常需要分层(Stratified)以保持类别比例;回归任务可能更关注随机性或时间性。 |
| 数据量 | 小数据集适合 LeaveOneOut;大数据集推荐 KFold 或 ShuffleSplit。 |
| 类别不平衡 | 使用 StratifiedKFold 保证每折中类别比例一致。 |
| 时间序列 | 使用 TimeSeriesSplit 保证训练集在测试集之前。 |
| 分组数据 | 样本有分组结构(如同一人多次测量),使用 GroupKFold 避免数据泄露。 |
| 性能 vs 稳定性 | KFold 稳定但计算量大;ShuffleSplit 可控且高效。 |
(2)常用交叉验证迭代器对比
| 迭代器 | 适用场景 | 是否分层 | 是否支持分组 | 时间序列友好 | 备注 |
|---|---|---|---|---|---|
| KFold | 通用,无特殊要求 | ❌ | ❌ | ❌ | 可设置 shuffle |
| StratifiedKFold | 分类任务,类别不平衡 | ✅ | ❌ | ❌ | 推荐用于分类 |
| GroupKFold | 样本有分组依赖 | ❌ | ✅ | ❌ | 防止组内泄露 |
| StratifiedGroupKFold | 分类 + 分组 | ✅ | ✅ | ❌ | 较新,需 sklearn ≥ 1.1 |
| TimeSeriesSplit | 时间序列预测 | ❌ | ❌ | ✅ | 按时间顺序划分 |
| LeaveOneOut | 小数据集(n < 20) | ❌ | ❌ | ❌ | 极高方差,计算昂贵 |
| ShuffleSplit | 大数据集,快速验证 | ❌ | ❌ | ❌ | 可重复多次 |
| StratifiedShuffleSplit | 分类 + 随机抽样 | ✅ | ❌ | ❌ | 控制每折样本数 |
(3)常用交叉验证迭代器及其适用场景
| 迭代器 | 适用场景 | 代码示例 |
|---|---|---|
KFold(n_splits=5, shuffle=False, random_state=None) |
标准选择。适用于大多数回归和分类问题,假设数据是 i.i.d。shuffle=True 可以打乱数据顺序,对于有顺序的数据(非时间序列)更安全。 |
python from sklearn.model_selection import KFold cv = KFold(n_splits=5, shuffle=True, random_state=42) |
StratifiedKFold(n_splits=5, shuffle=False, random_state=None) |
分类问题的首选。确保每个 fold 中各类别的比例与原始数据集大致相同。对于类别不平衡的数据尤其重要。 | python from sklearn.model_selection import StratifiedKFold cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42) |
| 迭代器 | 适用场景 | 代码示例 |
| — | — | — |
LeaveOneOut() |
极小数据集。每次留一个样本作为验证集,其余作为训练集。计算成本为 O(n),n 为样本数,n 大时不可行。 | python from sklearn.model_selection import LeaveOneOut cv = LeaveOneOut() |
LeavePOut(p=2) |
极小数据集。每次留 p 个样本作为验证集。组合数为 C(n, p),计算成本极高。 | python from sklearn.model_selection import LeavePOut cv = LeavePOut(p=2) |
ShuffleSplit(n_splits=10, test_size=0.2, train_size=0.8, random_state=None) |
灵活性高。不强制使用所有数据,可以指定训练/测试集大小。常用于大数据集或需要特定比例时。结果方差可能比 KFold 略大。 | python from sklearn.model_selection import ShuffleSplit cv = ShuffleSplit(n_splits=10, test_size=0.2, random_state=42) |
| 迭代器 | 适用场景 | 代码示例 |
| — | — | — |
StratifiedShuffleSplit(n_splits=10, test_size=0.2, random_state=None) |
分层的 ShuffleSplit。在 ShuffleSplit 的基础上保持类别比例。适用于分类问题且需要灵活划分比例时。 |
python from sklearn.model_selection import StratifiedShuffleSplit cv = StratifiedShuffleSplit(n_splits=10, test_size=0.2, random_state=42) |
TimeSeriesSplit(n_splits=5) |
时间序列数据。按时间顺序划分,训练集在前,验证集在后,确保没有未来信息泄露。 | python from sklearn.model_selection import TimeSeriesSplit cv = TimeSeriesSplit(n_splits=5) |
GroupKFold(n_splits=5) |
数据有分组。确保同一个组的样本不会同时出现在训练集和验证集中。 | python from sklearn.model_selection import GroupKFold cv = GroupKFold(n_splits=5) # 需要在调用时传入 groups 参数 |
StratifiedGroupKFold(n_splits=5) |
分组 + 分类 + 分层。在 GroupKFold 的基础上,尽可能保持每个 fold 中各类别的比例。 |
python from sklearn.model_selection import StratifiedGroupKFold cv = StratifiedGroupKFold(n_splits=5) |
| 迭代器 | 适用场景 | 代码示例 |
| — | — | — |
RepeatedKFold(n_splits=5, n_repeats=10, random_state=None) |
提高评估稳定性。重复进行多次 KFold,可以得到更可靠的性能估计。 | python from sklearn.model_selection import RepeatedKFold cv = RepeatedKFold(n_splits=5, n_repeats=10, random_state=42) |
RepeatedStratifiedKFold(n_splits=5, n_repeats=10, random_state=None) |
分类问题 + 提高稳定性。重复进行多次 StratifiedKFold。 | python from sklearn.model_selection import RepeatedStratifiedKFold cv = RepeatedStratifiedKFold(n_splits=5, n_repeats=10, random_state=42) |
四、使用建议
默认选择:
分类:StratifiedKFold
回归:KFold
设置 shuffle=True:除非数据有序(如时间序列),否则建议打乱。
固定 random_state:确保实验可复现。
避免数据泄露:在使用 CV 时,任何数据预处理(如标准化、填充)都应在 CV 循环内部进行(使用 Pipeline)。
python
深色版本
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
pipe = Pipeline([
('scaler', StandardScaler()),
('clf', SVC())
])
在 cross_val_score 中使用 pipe,确保 scaler 只在训练集上拟合
cross_val_score(pipe, X, y, cv=5)
总结
sklearn 的交叉验证迭代器提供了丰富且灵活的工具,能够适应从标准分类到时间序列、组数据等各种复杂场景。选择合适的迭代器是获得可靠、无偏模型评估的关键第一步。务必根据数据的结构和任务类型,选择最匹配的 CV 策略。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 23
23 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)