Generating Synergistic Formulaic Alpha Collections via Reinforcement Learning
论文基本信息 (Basic Information)
| 标题 (Title) | Generating Synergistic Formulaic Alpha Collections via Reinforcement Learning |
|---|---|
| Adress | https://dl.acm.org/doi/pdf/10.1145/3580305.3599831 |
| Journal/Time | KDD 2023 |
| Author | 中国科学院计算技术研究所, 华为 EI 创新实验室, |
| Code |
0. 背景知识补充
- Alpha Factor(Alpha 因子):输入是过去几天的股票价格(Open, Close, High, Low),输出是一个数值。我们希望这个数值能预测明天的涨跌。Formulaic Alpha:用数学公式写出来的特征,比如 (Close - Open) / Open。目标是利用AI 写出这种公式能更好的预测 Alpha 因子。类似CV 中需要提取出来的特征。
- IC (Information Coefficient):因子值和未来股票收益率的相关性。IC 越高,预测得越准。优化目标就是让 IC 变大。类似相关系数,就是最后和GT 的相似度。
1. 核心思想 (Core Idea)
本文提出了一个基于强化学习(RL)的框架,用于自动生成一组数学公式(Alpha 因子),用于预测股票趋势。
它的目标不是“生成一个最强的因子”,而是生成一组具有协同效应(Synergistic)的公式化 Alpha 因子。Alpha挖掘不应该是一个独立的筛选过程,而应该是一个团队组建的过程。
不再以单个因子的能力判断,而是利用组合后的整体的因子组为目标训练(RL 的奖励信号(Reward))。关心的目标从 这个因子强不强 -> 把这个因子加入当前的队伍后,整个队伍的收益有没有变高。
2. 研究背景与动机 (Background and Motivation)
在量化交易中,投资者需要挖掘大量“因子”(特征)来预测股价。目前的趋势是用 AI 自动挖掘公式化因子(由加减乘除等算子构成的公式)。
现有的进化算法(如遗传规划 GP)通常是独立挖掘每一个因子。-> 利用是否能针对整个因子组的性能有提升。
为了避免因子重复,传统方法是计算两两相关性,把相似的剔除。 -> “高相关性”不代表不能互补(例如两个相似因子相减可能消除噪声),将其线性组合也会有提升。
3. 方法论 (Methodology)
- 公式表示:公式、树 (Tree)一般用于遗传规划、逆波兰表达式 (RPN)用于本文适用LSTM,数据流
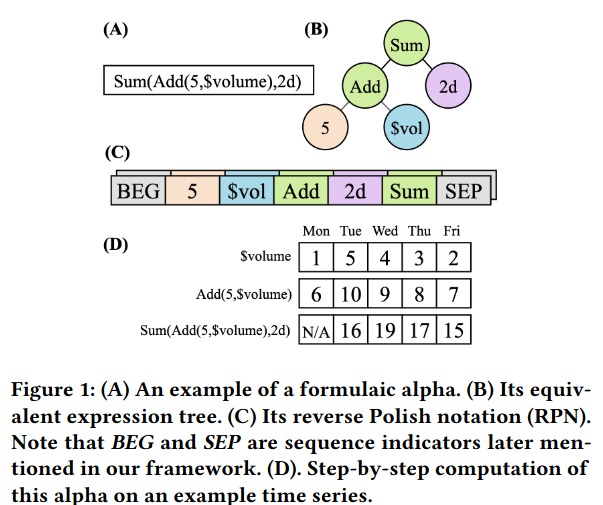
输入: (Nstocks,Twindow,Cfeatures)(N_{stocks}, T_{window}, C_{features})(Nstocks,Twindow,Cfeatures)
NstocksN_{stocks}Nstocks:股票池大小。
TwindowT_{window}Twindow:时间窗口(Lookback Window)过去20天甚至60天。
CfeaturesC_{features}Cfeatures:通道数(Channels)。Open (开盘价), Close (收盘价), High (最高价), Low (最低价), Volume (成交量), VWAP (成交量加权平均价);
RL Agent 输出:一个离散的 Token 序列即逆波兰表达式 (RPN) 。上图 c 部分。
最终输出 (Output):Alpha Factor 一个实数值向量 (Real-valued Vector) z∈Rnz \in \mathbb{R}^nz∈Rn ,如果有 300 只股票,就输出 300 个数字。得分越高,预测这只股票未来涨得越好。
预测目标 (Ground Truth):未来 20 天的收益率 (20-day Return)。
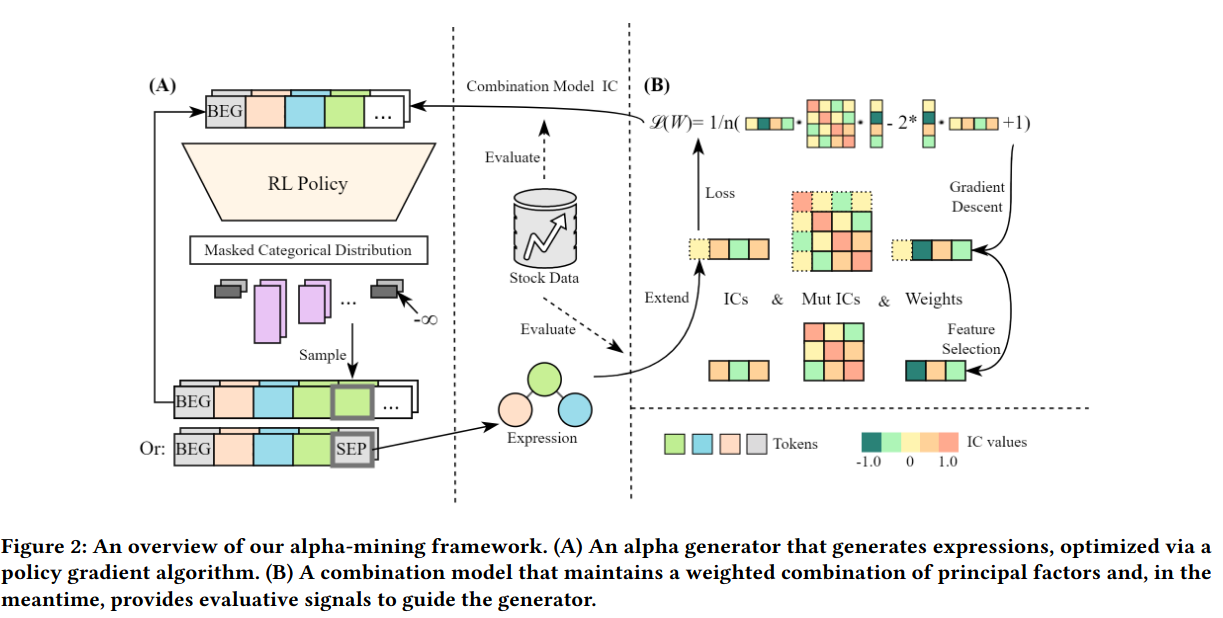
典型的 强化学习(RL) 闭环:
- Alpha Generator (生成器 - Agent):图左侧
- 结构:LSTM 网络,输出序列化的 Token。
- 表示法:使用逆波兰表达式 (RPN) 来表示数学公式(类似编译器原理),保证生成的公式结构合法。
- 优化:使用 PPO (Proximal Policy Optimization) 算法进行训练。
- 有一个 Mask 机制(类似 Attention Mask)
- Combination Model (评估器 - Environment):图右侧
- 把新生成的因子加入当前的因子池。计算新因子和老因子的相关性矩阵。
- 模型:简单的线性回归模型(Linear Regression)。
- 创新点 (Theorem 3.1):为了解决训练慢的问题,作者推导了一个公式,不需要每次都重新训练线性模型,只需根据因子的 IC 和 互相关矩阵,就能快速算出新因子的边际贡献。
- Reward:新因子加入后,组合模型在验证集上的 Loss 下降程度。
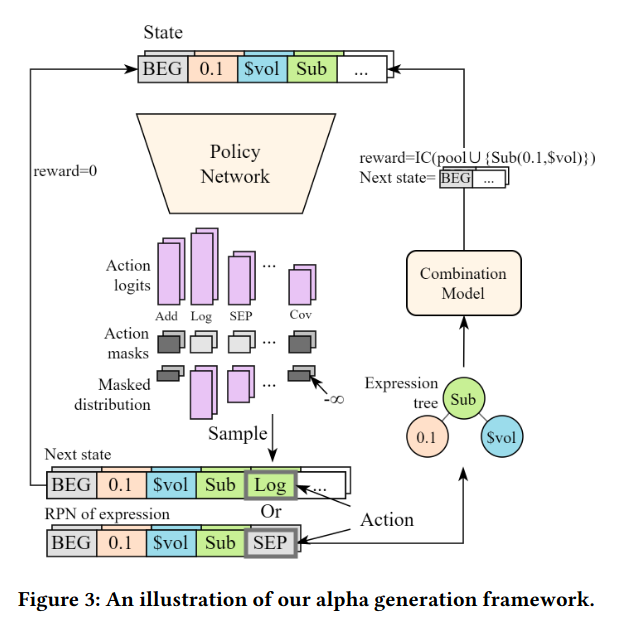
State:当前的 Token 序列。
Action:下一个 Token。
Reward:只有当生成完完整的公式(遇到 SEP),并且放入组合模型跑完测试后,才会得到一个 Reward。稀疏奖励(Sparse Reward)。但其实不知道是具体哪个部分做的好。
公式 (5) & (6): 组合模型与 Loss定义:组合模型就是一个简单的线性回归 。
c(X;F,w)=∑j=1kwjfj(X)=zc(X; \mathcal{F}, w) = \sum_{j=1}^k w_j f_j(X) = zc(X;F,w)=j=1∑kwjfj(X)=z 即:最终预测值 zzz 是 kkk 个因子 fjf_jfj 的加权和。
Loss:目标是让预测值 zzz 和真实收益率 yyy 的均方误差 (MSE) 最小:L(w)=1nT∑t=1T∣∣zt−yt∣∣2\mathcal{L}(w) = \frac{1}{nT} \sum_{t=1}^T ||z_t - y_t||^2L(w)=nT1t=1∑T∣∣zt−yt∣∣2
公式 (7):由 Eq. 6 推导出来的等价公式。
- 线性组合模型:预测值 zzz 必须是所有因子 fif_ifi 的加权和 。
- 归一化:所有的因子输出 f(X)f(X)f(X) 和真实标签 yyy 都必须预先经过归一化处理 mean=0,Length=1。
- 当两个向量被归一化(均值为0,模长为1)后,它们的内积(点积)就严格等于它们的皮尔逊相关系数 。
Theorem 3.1 (核心加速定理)问题:如果在 Loss 里直接算 ∣∣zt−yt∣∣2||z_t - y_t||^2∣∣zt−yt∣∣2,每次都要遍历几年的历史数据(TTT 很大),训练太慢。解决:作者推导出 Loss 等价于以下形式 :(附录 B Eq. 12)复杂度从 O(N*T) 到 O(K²) 。
L(w)=1n(1−2∑i=1kwiσ‾y(fi)+∑i=1k∑j=1kwiwjσ‾(fi,fj))\mathcal{L}(w) = \frac{1}{n}(1 - 2\sum_{i=1}^k w_i \overline{\sigma}_y(f_i) + \sum_{i=1}^k \sum_{j=1}^k w_i w_j \overline{\sigma}(f_i, f_j))L(w)=n1(1−2i=1∑kwiσy(fi)+i=1∑kj=1∑kwiwjσ(fi,fj))
σ‾y(fi)\overline{\sigma}_y(f_i)σy(fi) 是 单个因子的 IC(和 Label 的相关性)。
σ‾(fi,fj)\overline{\sigma}(f_i, f_j)σ(fi,fj) 是 因子两两之间的互相关(Mutual IC)。
增量式组合优化:新因子加入后,如何快速调整权重,保持精简。
算互相关性,梯度下降(公式7)更新权重,把权重绝对值最小的剔除,保持因子池大小恒定。
Alpha 挖掘流程,RL 的训练过程。
RL Agent 根据当前状态,一个一个生成token,直到能生成完整的公式。调用 Algorithm 1,计算新组合的 IC ,判断是否能降loss。如果公式还没写完(中间步骤),Reward = 0。生成了很多个公式后利用PPO算法(策略网络参数 θ\thetaθ)更新。

Proximal Policy Optimization (PPO)
LCLIP=E[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)]L^{CLIP} = \mathbb{E} [ \min( r_t(\theta) \hat{A}_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) \hat{A}_t ) ]LCLIP=E[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)]
rt(θ)r_t(\theta)rt(θ): 代表变化的程度,ϵ\epsilonϵ论文里设为 0.2
控制每次变的最大程度,限制每次参数更新的幅度,避免过早收敛策略崩溃。
4. 实验结果 (Experimental Results)
-
数据集:中国 A 股市场(CSI300 和 CSI500 成分股)。
-
对比基线:单因子生成模型:GP (遗传规划), Deep Learning (LSTM 等)。组合策略:Top-K 选取,相关性过滤选取。
-
主要结论:性能: 该方法生成的因子集合在 IC 和 Rank IC 指标上均优于所有基线 。
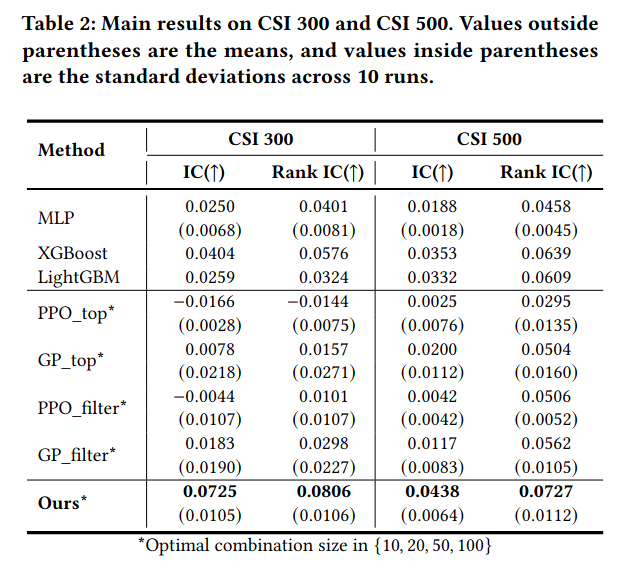
扩展性: 随着因子池大小(Pool Size)增加(如从 10 增加到 100),该方法的性能持续提升,而 GP 方法在后期因难以找到协同因子而停滞。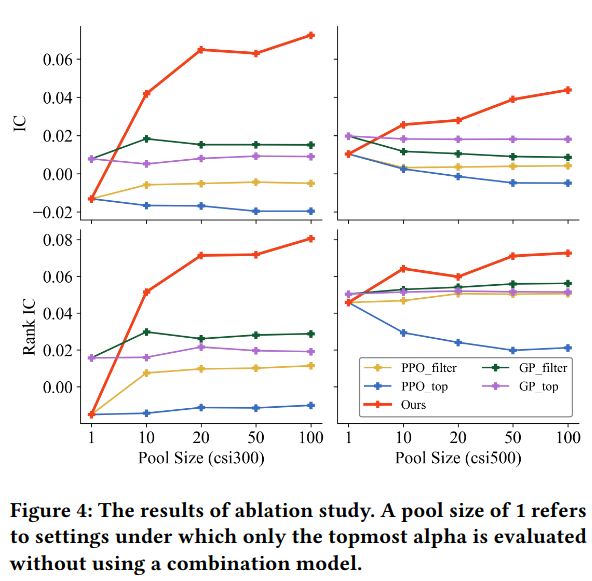
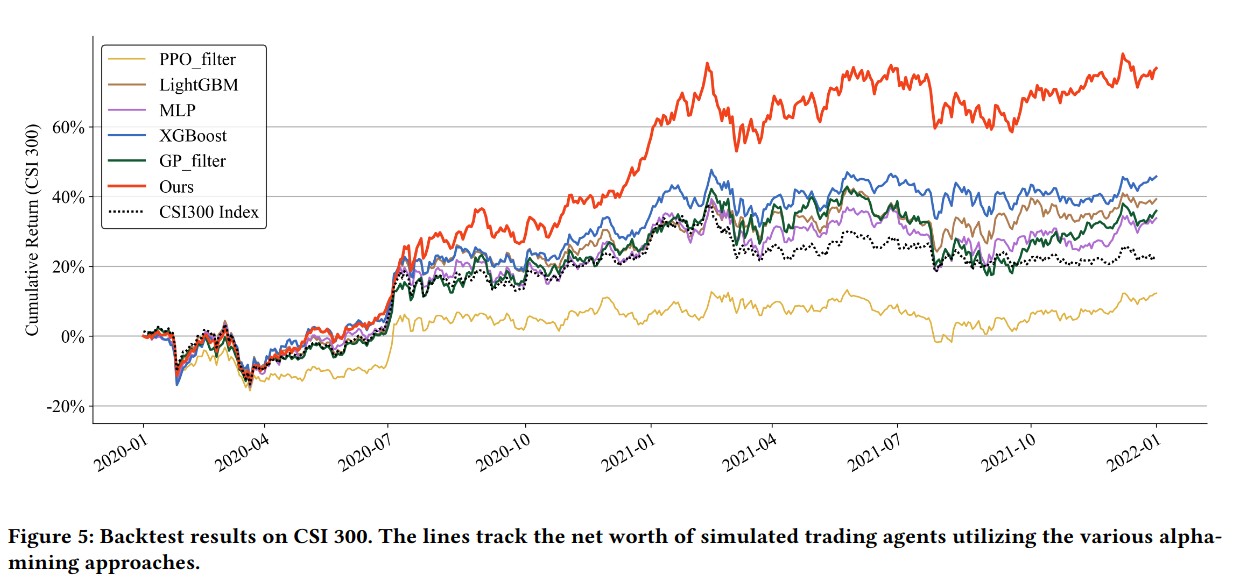
投资回测: 在模拟交易中取得了最高的累积收益 。
案例分析: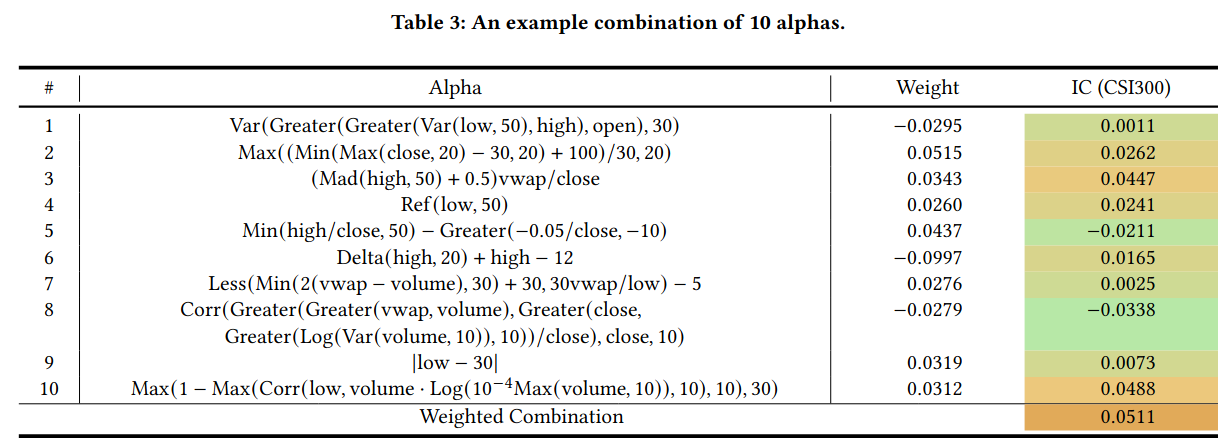
Alpha #2 和 Alpha #6 相关性高达 0.97。它们的权重分别是 0.0515 和 -0.0997
5. 结论与讨论 (Conclusion & Discussion)
本文证明了在特征生成任务中,端到端(End-to-End) 的优化目标(组合性能)比局部目标(单个性能 + 规则过滤)更有效。
RL 在探索巨大的公式空间时比 GP 更具优势 。
目前的组合模型仅使用了线性模型,理论上可以扩展到非线性模型(如树模型),但这会增加计算复杂度 。
公式长度被限制在 20 个 token 以内,可能限制了复杂逻辑的表达 。
6. 主要贡献总结 (Summary of Key Contributions)
提出了第一个直接以组合协同效应 (Synergy) 为优化目标的 Alpha 挖掘框架 。
设计了一个结合 RPN 生成和 PPO 优化的 RL 框架,专门用于生成公式。
提出了基于 IC 和互相关矩阵的快速 Loss 计算方法(Theorem 3.1),使强化学习在大规模因子搜索中成为可能。
7. 附录
公式 7 推导

8. 个人思考
数学公式的离散搜索空间,目标函数的设计上的思考推导太优雅了。
由于是线性回归还是存在一些局限性,在非线性的表现是未知的。
两个高相关性可能只能作为分析,差异太微小了,在算权重的时候有波动的风险。是否也应该加入一些限制。
后期因子越来越多也会平缓的,而且不同 Pool Size 下性能波动依然存在,其实会存在参数敏感的情况。
数据集只在中国 A 股(CSI300, CSI500)上进行,不具有普遍性。
目前也有 多目标优化的遗传规划,也是将相关性作为惩罚项,相关方法没对比。
可解释性是生成过程可解释,但是公式不具备可解释性。
可以对公式长度硬性限制在 20 个 Token 以内这个token进行个消融。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)