【TNNLS2025】YOLO-MS: Rethinking Multi-Scale Representation Learning for Real-Time Object Detection
论文作者:Yuming Chen , Xinbin Yuan , Jiabao Wang , Ruiqi Wu, Xiang Li , Qibin Hou , Member, IEEE, and Ming-Ming Cheng , Senior Member, IEEE发布年份:2025代码链接:1.MS-Block和全局查询学习(GQL):作者提出了一种新的多分支构建块,称为MS-Block,用
论文作者:Yuming Chen , Xinbin Yuan , Jiabao Wang , Ruiqi Wu, Xiang Li , Qibin Hou , Member, IEEE, and Ming-Ming Cheng , Senior Member, IEEE
发布年份:2025
代码链接:
https://github.com/FishAndWasabi/YOLO-MS
论文创新点
1.MS-Block和全局查询学习(GQL):作者提出了一种新的多分支构建块,称为MS-Block,用于增强多尺度特征学习。它利用全局查询来动态指导跨阶段的空间表示,减少冗余的空间信息,并提高多尺度特征的多样性。
2.异构卷积核选择(HKS):论文提出了HKS协议,该协议在网络的不同阶段使用不同的卷积核大小。这种方法通过在浅层使用小卷积核处理高分辨率特征,在深层使用大卷积核捕获高级语义信息,从而优化了计算和性能之间的平衡。
3.可插拔模块增强:YOLO-MS可以作为模块集成到其他YOLO模型中,显著提高性能,同时减少参数量和计算成本。例如,它能在不增加计算负担的情况下,提升YOLOv8模型的准确度,同时保持实时检测速度。
方法
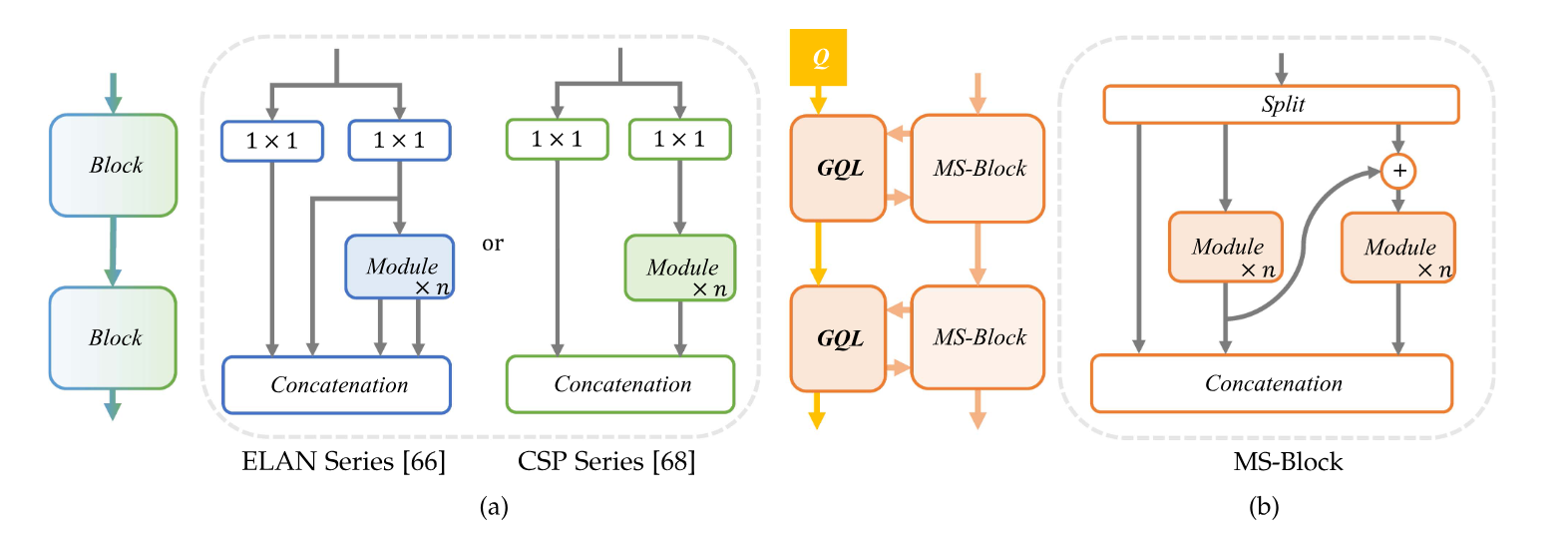
MS-Block
如图三右
多分支设计:MS-Block采用了一个层次化的多分支结构,与传统的两分支结构(如CSP和ELAN)相比,MS-Block的每个分支拥有不同的感受野。这样可以更好地捕捉不同尺度的信息,避免特征冗余,提升模型对各种尺度目标的检测能力。
倒置瓶颈模块(Inverted Bottleneck Module, IBM):每个分支采用了倒置瓶颈模块(IBM),这是为了更高效地提取特征。IBM可以通过深度卷积来处理大卷积核,从而提高模块的计算效率,并减少计算成本。
分支特征融合:每个分支独立处理特征后,MS-Block通过1×1卷积将各分支的特征融合在一起。这一卷积操作用于调整每个分支的输出通道数,确保深层网络中多尺度特征的融合。
IBM
1×1卷积(扩展):
先使用一个 1×1 卷积将输入特征图的通道数扩展,通常使用一个较大的通道数来增加网络的表达能力。
深度可分卷积(Depthwise Convolution):
然后,使用深度可分卷积(Depthwise Separable Convolution),即对每个输入通道单独进行卷积操作,这大大减少了计算量。深度卷积的特点是它不将所有通道的特征融合在一起,而是分别处理每个通道的特征,这比标准卷积计算量小。
1×1卷积(压缩):
最后,通过另一个1×1 卷积来压缩通道数,恢复到期望的输出通道数。这一压缩步骤帮助减少了模型的参数数量和计算复杂度。
全局查询学习

为了进一步提升多尺度特征的表达能力,MS-Block引入了**全局查询学习(GQL)**机制。GQL的目的是通过一个全局查询来引导各分支的特征提取过程,并增强分支之间的特征多样性。
全局查询(Global Query, Q):GQL使用一个轻量的、可学习的全局查询
,其中 N 是分支数,是查询的通道数。这个全局查询与每个分支的特征进行交互,动态调整每个分支的影响力。
交互过程:在MS-Block的每个阶段,GQL通过与当前分支的特征 Y 进行交互来调节分支的影响力。具体来说,GQL通过以下方式计算输出:
GAP 是全局平均池化(Global Average Pooling),将每个分支的特征图 Y 压缩成一个全局的特征表示 K,Q 是全局查询,用来与 K 进行点积操作,生成每个分支的权重。
S 表示Sigmoid函数,用于计算每个分支的注意力权重。
Fms(Y)是多尺度块的特征输出。
从代码层面详细看GQL模块:
完整模块:
class GQL(nn.Module):
def __init__(self, dim: int, length: int = 3, size: int = 4) -> None:
super().__init__()
self.pool = nn.AdaptiveAvgPool2d((size, size))
self.length = length
self.down_conv = nn.Conv2d(dim, 1, kernel_size=1)
def forward(self, inputs: torch.Tensor, query: torch.Tensor) -> torch.Tensor:
n, _ = query.shape
b, C, _, _ = inputs.shape
# Apply adaptive average pooling and convolution
pooled = self.pool(inputs)
outs = self.down_conv(pooled)
# Compute attention weights
weight = torch.matmul(query[None, ...].repeat(b, 1, 1), outs.reshape(b, -1, 1)).sigmoid()
# Apply attention weights to the input tensor
inputs = inputs * weight.repeat(1, C // n, 1).unsqueeze(-1)
return inputs
拆分开:
def __init__(self, dim: int, length: int = 3, size: int = 4) -> None:
super().__init__()
self.pool = nn.AdaptiveAvgPool2d((size, size))
self.length = length
self.down_conv = nn.Conv2d(dim, 1, kernel_size=1)
def init(self, dim: int, length: int = 3, size: int = 4) -> None:
dim:输入通道数 C(与输入张量 inputs 的通道数对应)。
length:查询(query)向量的数量 N(默认 3)。
size:AdaptiveAvgPool 的目标空间尺寸(默认 4,意味着池化结果是 size x size)。
super().init():初始化父类 nn.Module。
self.pool = nn.AdaptiveAvgPool2d((size, size)):把任意 H x W 池化到固定的 size x size(例如 4×4),输出形状 (B, C, size, size)。
self.length = length:保存 length(后续用于构造或断言)。
self.down_conv = nn.Conv2d(dim, 1, kernel_size=1):1×1 卷积把 C 通道降为 1 通道,输出形状 (B, 1, size, size)。目的是把池化后的每个空间位置映射成一个 scalar(作为 attention 的“value”或“投影”)。
def forward(self, inputs: torch.Tensor, query: torch.Tensor) -> torch.Tensor:
n, _ = query.shape
b, C, _, _ = inputs.shape
# Apply adaptive average pooling and convolution
pooled = self.pool(inputs)
outs = self.down_conv(pooled)
n, _ = query.shape
query 形状是 (N, D),这里 n = N(查询个数),下划线 _ 是 D(查询向量的维度),但代码没有把 D 存起来,只解出 n。
b, C, _, _ = inputs.shape
inputs 形状是 (B, C, H, W),这里 b = B, C = 通道数,空间尺寸丢弃(用 _ 占位)。
pooled = self.pool(inputs)
经过 AdaptiveAvgPool2d((size, size)),pooled 形状是 (B, C, size, size)。把 H×W 信息压缩到固定小网格。
outs = self.down_conv(pooled)
down_conv 把 C 通道降为 1,所以 outs 形状是 (B, 1, size, size)。
这一步得到每个空间位置一个 scalar 特征(每张图 size*size 个标量)
# Compute attention weights
weight = torch.matmul(query[None, ...].repeat(b, 1, 1), outs.reshape(b, -1, 1)).sigmoid()
# Apply attention weights to the input tensor
inputs = inputs * weight.repeat(1, C // n, 1).unsqueeze(-1)
return inputs
weight = torch.matmul(query[None, …].repeat(b, 1, 1), outs.reshape(b, -1, 1)).sigmoid()
query[None, …]
把 query 从 (N, D) 变成 (1, N, D)(在最前面加一维)。
.repeat(b, 1, 1)
把上面那一维复制 b 次,变成 (B, N, D)。也就是为每个 batch 都复制一份 query。
outs.reshape(b, -1, 1)
outs 原来 (B, 1, size, size),reshape 后 (B, S, 1),其中 S = sizesize(每张图有 S 个空间位置的投影值)。
torch.matmul((B, N, D), (B, S, 1))
进行 batched 矩阵乘法:对每个 batch i,计算 (N, D) @ (S, 1)。矩阵乘法要求中间维度一致,即 D 必须等于 S(D == sizesize)。
若满足,结果形状为 (B, N, 1)(每个 query 在每张图上的一个标量响应)。
.sigmoid()
把响应分数压缩到 (0, 1),用作注意力/缩放因子
inputs = inputs * weight.repeat(1, C // n, 1).unsqueeze(-1)
weight.repeat(1, C // n, 1):对 weight 在通道维度重复 C // n 次,意图把 N→C,得到形状 (B, C, 1)(前提:C // n * n == C 即 C 可以被 n 整除)。
如果 C % n != 0,这里会有问题(会造成重复后通道数 != C 或不可整除的行为)。
.unsqueeze(-1) 把 (B, C, 1) 变为 (B, C, 1, 1),可与 inputs (B, C, H, W) 广播相乘,从而按通道缩放输入的每个通道(每个通道乘上一个标量)。
最终 inputs 返回形状仍为 (B, C, H, W)(按通道加权后的原尺寸特征图)
HKS(异构核大小选择策略)
HKS(Heterogeneous Kernel Size Selection,异构卷积核选择) 是 YOLO-MS 中提出的一个重要创新,它通过在网络的不同阶段使用不同大小的卷积核来增强多尺度特征的提取能力。传统的卷积神经网络(CNN)通常使用统一的卷积核大小,而HKS通过为不同网络阶段选择不同的卷积核大小,来更有效地捕捉不同尺度的特征。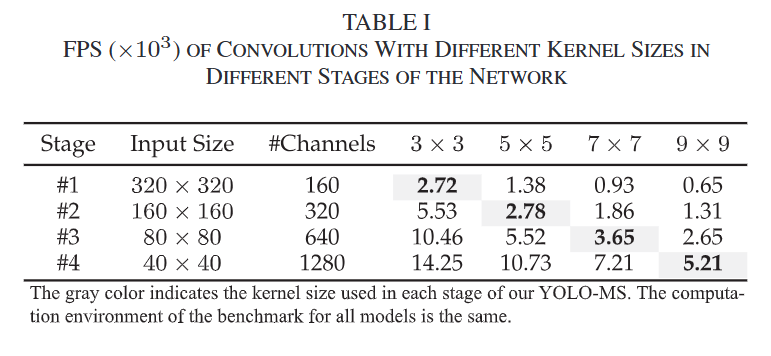
所有模型的基准测试环境是相同的。灰色表示YOLOMS每个阶段使用的内核大小
代码实现:
arch_settings = {
'C3-K3579': [
[MSBlock, 80, 160, [1, (3, 3), (3, 3)], [1, 1, 1], False, None],
[MSBlock, 160, 320, [1, (5, 5), (5, 5)], [1, 1, 1], False, None],
[MSBlock, 320, 640, [1, (7, 7), (7, 7)], [1, 1, 1], False, None],
[MSBlock, 640, 1280, [1, (9, 9), (9, 9)], [1, 1, 1], True, None],
],
'C3-K3579-A234': [
[MSBlock, 80, 160, [1, (3, 3), (3, 3)], [1, 1, 1], False, None],
[MSBlock, 160, 320, [1, (5, 5), (5, 5)], [1, 1, 1], False, True],
[MSBlock, 320, 640, [1, (7, 7), (7, 7)], [1, 1, 1], False, True],
[MSBlock, 640, 1280, [1, (9, 9), (9, 9)], [1, 1, 1], True, True],
],
}
‘C3-K3579’ :基础版本(只包含多尺度卷积核策略 HKS)
‘C3-K3579-A234’ :进阶版本(在 Stage 2、3、4 启用注意力机制 GQL)
对应位置参数含义:
第1个:阶段模块类,固定为 MSBlock
第2个:in_channels(输入通道)
第3个:out_channels(输出通道)
第4个:kernel_sizes(各分支核大小,例 [1,(3,3),(3,3)] 表示3个分支,其中1表示直通分支)
第5个:channel_split_ratios(分支通道划分比例,对应第4个的分支数)
第6个:use_spp(是否先经过 SPP 模块)
第7个:use_attention_cfg(是否对该阶段启用“分支前/聚合前”注意力;为 True 时会把 msblock_attention_cfg 传给该阶段的 MSBlock)
整体架构
YOLO-MS模型的主干由四个阶段组成,每个阶段之后都有一个3×3卷积(步长为2)用于下采样。YOLO-MS采用最先进的实时检测器RTMDet作为基线。在编码器中,利用使用SiLU作为激活函数,使用BN进行归一化。在第三阶段后添加了一个SPP块。使用PAFPN作为颈部,在编码器上构建特征金字塔。它融合了从 backbone 不同阶段提取的多尺度特征。颈部使用的基本构建块也是MS-Block,并且HKS在颈部和头部中同样被使用。此外,为了在速度和精度之间取得更好的平衡,我们将来自backbone的多级特征的通道深度减半。YOLO-MS有三个变体,即YOLO-MS-XS、YOLO-MS-S和YOLO-MS。不同尺度的YOLO-MS的详细配置列于表II中。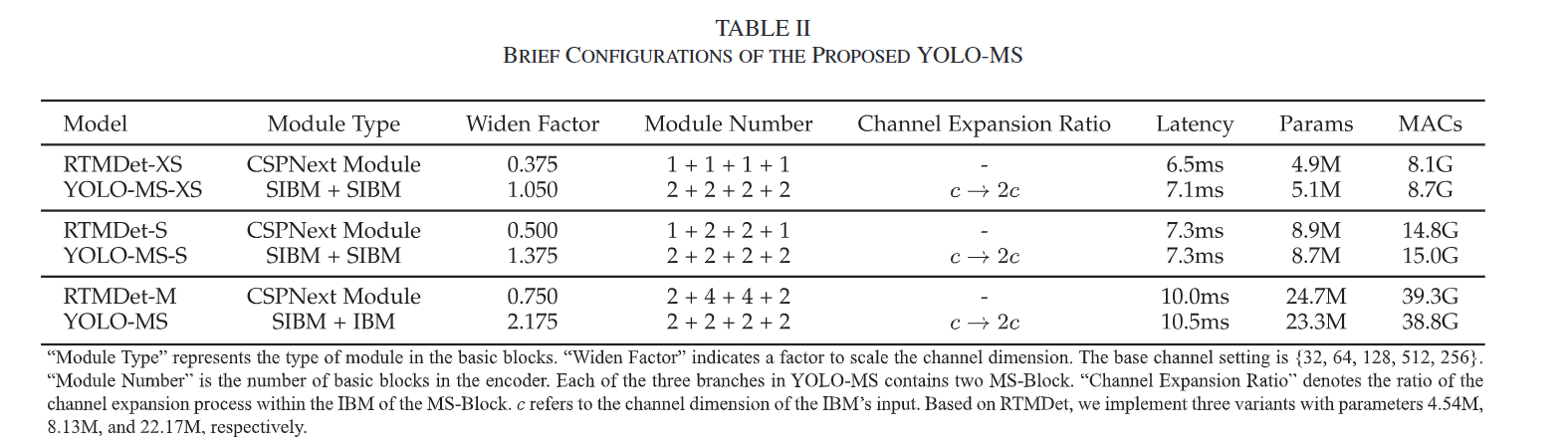
实验

图8. 通过Grad-CAM与最先进技术的视觉对比。我们的方法能够更好地定位不同尺度的物体。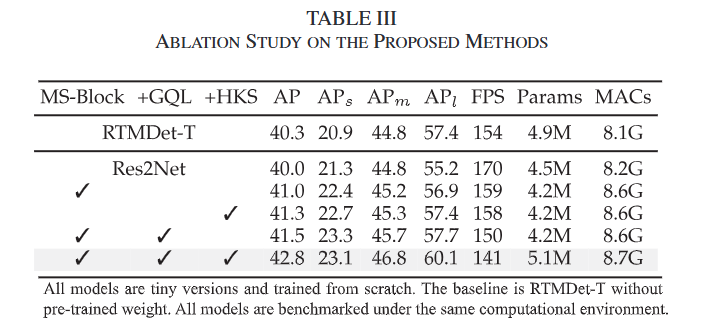
表3: 所提方法的消融实验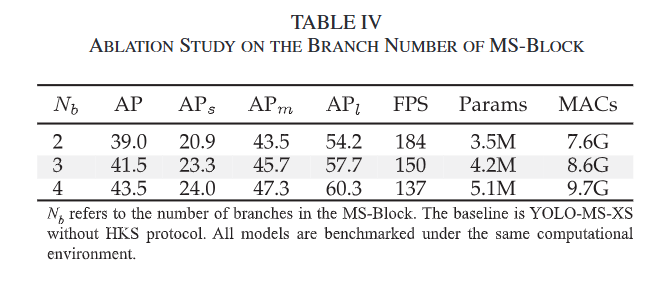
表4 :MS-Block分支数量的消融研究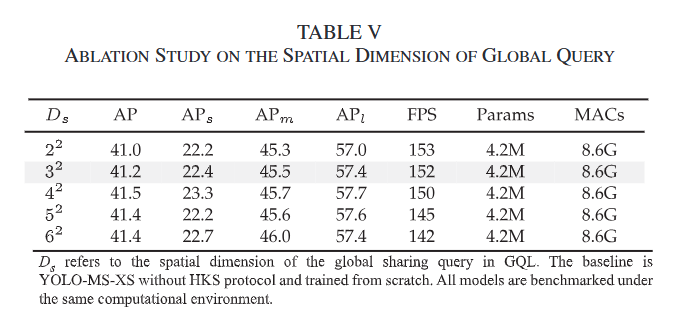
表5: 全局查询空间维度的消融研究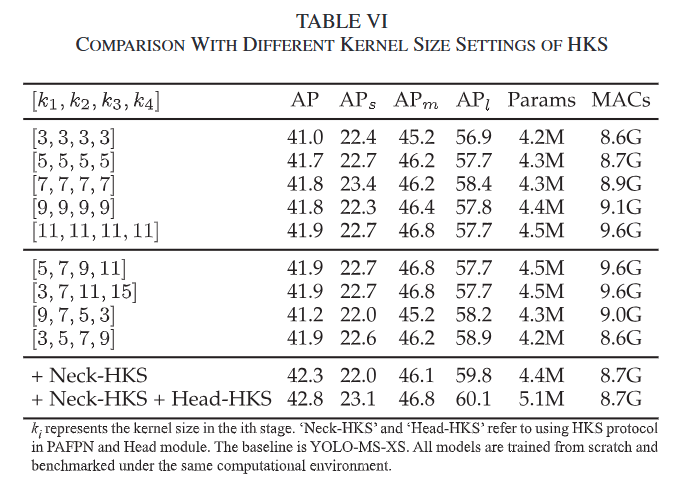
表6: 不同HKS核大小设置的比较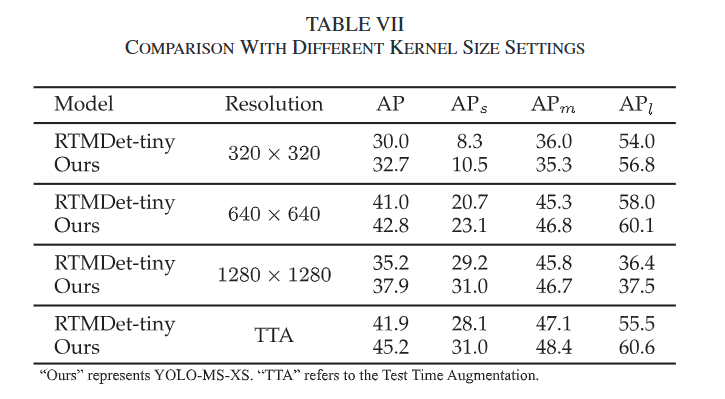
表7: 不同内核大小设置的比较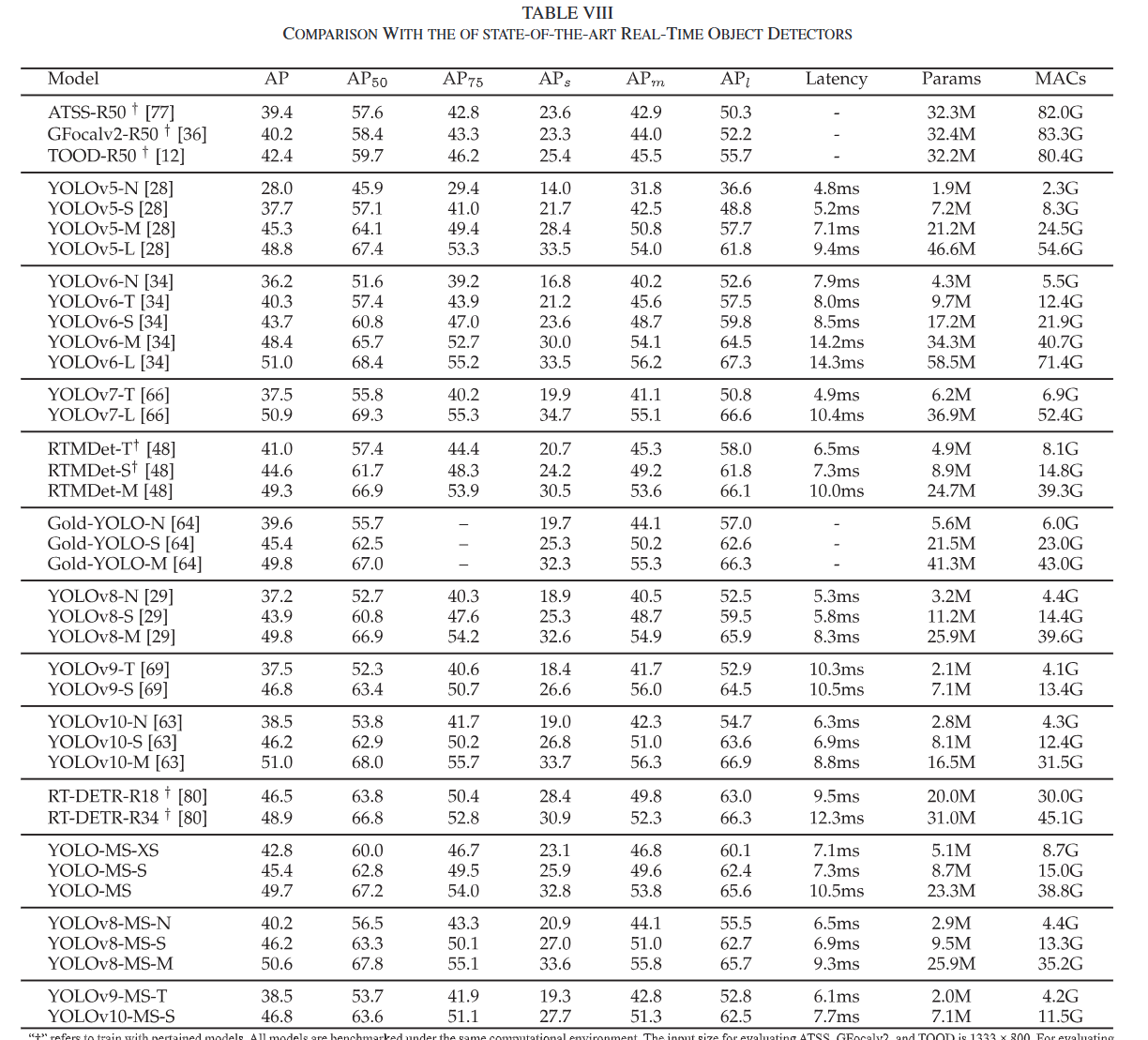
表8: 与最先进的实时目标检测器的比较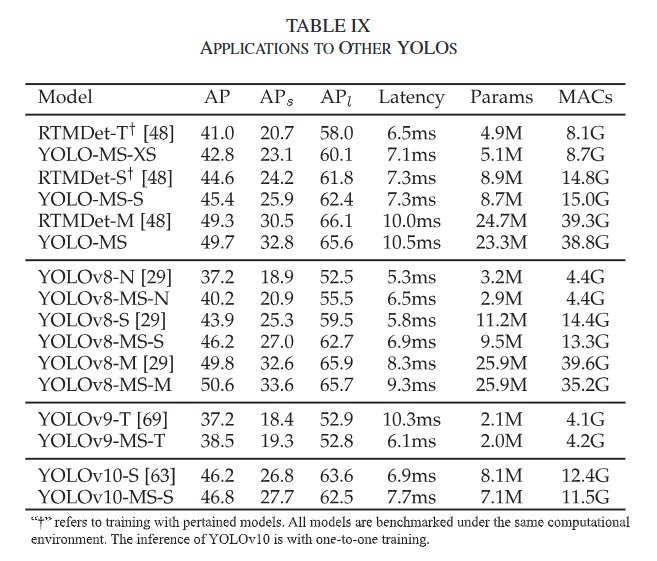
表9:对其他YOLO模型的应用
结论
本文提出了一种高性能的实时目标检测器,其计算成本合理。为实现这一目标,我们研究了特征分布以及不同 kernel 大小的卷积所产生的影响,并构建了一个能够高效提取多尺度特征表示的编码器。我们的实验研究表明,所提出的 MS-Block 与 GQL 和 HKS 协议相结合,显著改善了检测器在速度和精度之间的平衡,性能超过了其他实时检测器。我们希望这项工作能为目标检测领域带来新的见解。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)