测试驱动强化学习框架TdRL:告别手动奖励设计,多目标连续控制性能提升超13%
制造系统工程国家重点实验室&西安交通大学&南安普顿大学的团队联合研发提出的测试驱动强化学习(TdRL)框架《Test-driven Reinforcement Learning》:以 “通过 - 失败测试 + 指示性测试” 替代传统单一奖励函数,通过词典序轨迹比较学习轨迹返回函数,在 DeepMind Control Suite 基准中匹配甚至超越手工设计奖励的 SAC/PPO 算法,多目标任务中
摘要:来自制造系统工程国家重点实验室&西安交通大学&南安普顿大学的团队联合研发提出的测试驱动强化学习(TdRL)框架《Test-driven Reinforcement Learning》:以 “通过 - 失败测试 + 指示性测试” 替代传统单一奖励函数,通过词典序轨迹比较学习轨迹返回函数,在 DeepMind Control Suite 基准中匹配甚至超越手工设计奖励的 SAC/PPO 算法,多目标任务中满足所有指标阈值的成功率提升 13%+,彻底解决传统 RL“奖励设计难、多目标平衡复杂、易出现奖励欺骗” 的核心痛点。
一、传统强化学习的核心技术瓶颈
现有强化学习(RL)在连续控制任务中面临三大关键挑战:
-
奖励设计复杂:手动设计需兼顾 “定义最优目标 + 引导学习过程”,依赖领域 expertise,易出现奖励欺骗(Reward Hacking);
-
多目标优化难:多目标任务中需手动平衡权重,常导致某一指标最优而其他指标不达标;
-
评估粒度局限:基于状态 - 动作对的奖励评估,忽视轨迹级整体性能,与实际任务需求脱节。
二、核心创新:TdRL 的三大技术突破
框架以 “测试函数定义目标→轨迹比较学习返回→策略优化收敛” 为核心逻辑,三大创新点如下:
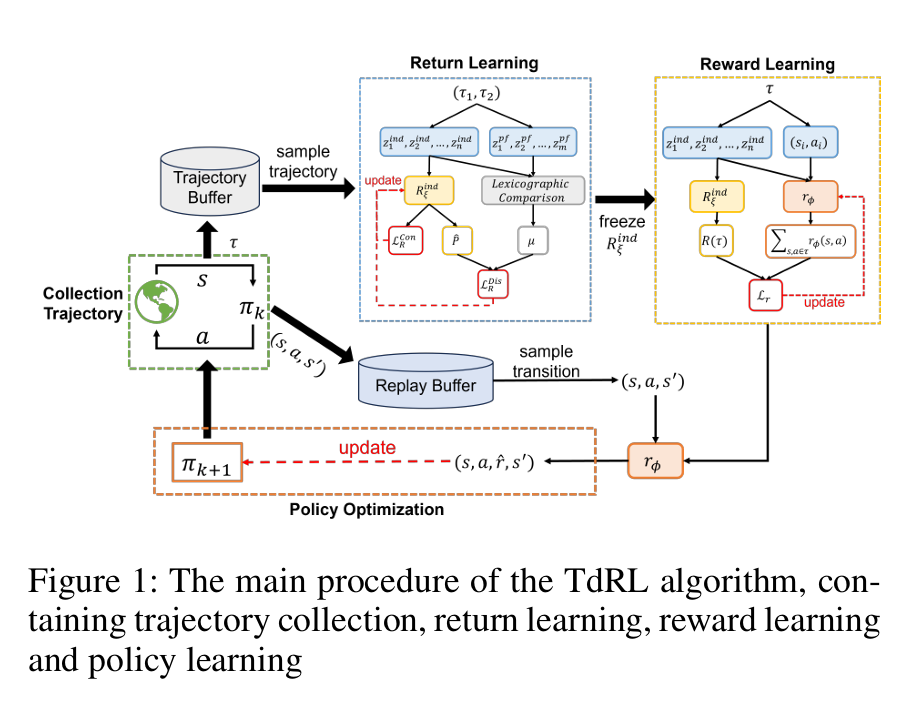
1. 测试函数设计:拆分目标定义与学习引导
-
定义:用两类测试函数替代单一奖励函数,分别承担 “定义最优目标” 和 “引导学习” 功能;
-
核心分类:
-
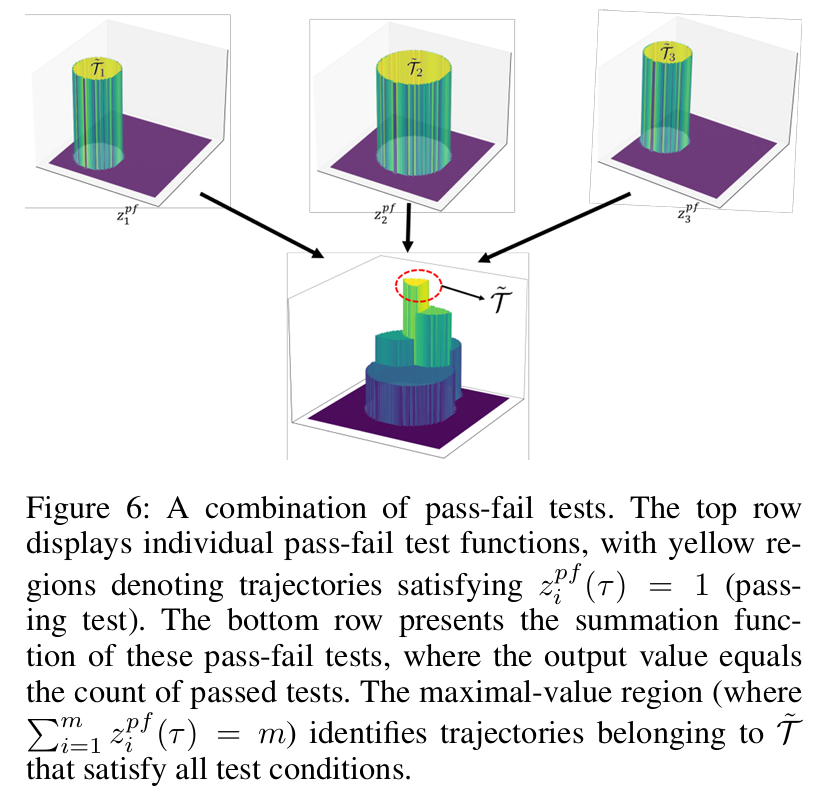
通过 - 失败测试(Pass-fail Tests):输出二进制结果,定义任务必须满足的硬指标(如躯干高度≥1.2);
-
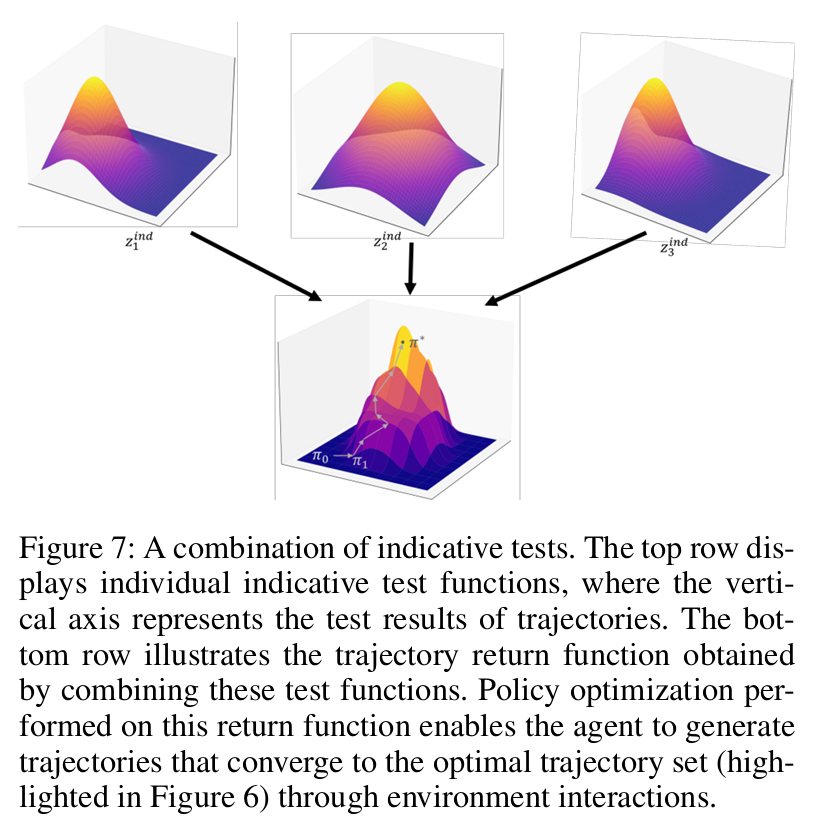
指示性测试(Indicative Tests):输出连续值,提供学习引导信号(如平均速度、直立时间占比);
-
优势:无需手动平衡多目标权重,设计直观,天然支持多目标优化(图 6、图 7)。
2. 轨迹返回函数:保证收敛的理论基础
-
定义:构造单调非增的轨迹返回函数 R (τ),轨迹与最优轨迹集(通过所有通过 - 失败测试)距离越近,返回值越高;
-
核心证明:若 R (τ) 满足单调性,最大熵策略优化会使新策略更接近最优策略集(定理 1),为算法收敛提供理论保障;
-
学习机制:通过距离损失(L_R^Dis)和惩罚损失(L_R^Penalty)学习返回函数,避免返回值失控,提升训练稳定性。
3. 词典序轨迹比较:高效获取相对距离关系
-
定义:在最优轨迹集未知的情况下,通过优先级排序比较轨迹与最优集的相对距离,无需直接计算距离;
-
核心步骤:
-
优先比较通过 - 失败测试通过率,通过率高的轨迹更优;
-
通过率相同时,按测试难度排序比较;
-
最后按指示性测试的优化缺口排序(未优化指标优先);
-
-
优势:高效获取轨迹相对质量,为返回函数学习提供监督信号,计算复杂度 O (MN) 且支持并行。
三、实验验证:多任务性能与多目标优势双突破
基于 DeepMind Control Suite(Walker-Stand/Run、Cheetah-Run 等),以 SAC/PPO 为基准算法,关键结果如下:
1. 核心性能:匹配甚至超越手工奖励
-
单目标任务:TdRL-ES/TdRL-GN 变体在 Walker-Stand、Cheetah-Run 等任务中 episode return 与 SAC( oracle 奖励)相当,Quadruped-Run 任务速度指标提升 15.4%(3.95→4.56);
-
多目标任务(Walker-Run):传统 SAC 未满足躯干高度阈值(1.12<1.2),TdRL 达到 1.30,同时保持速度(6.78)与直立度(0.94)达标,多目标满足率提升 13%+。
2. 消融实验:关键模块不可或缺
-
无惩罚项:返回值失控导致训练不稳定,episode return 波动幅度增加 40%;
-
直接学习奖励函数:需持续调整奖励范围,性能下降 25%,无法适配多目标场景;
-
词典序比较:替代随机比较后,训练收敛速度提升 30%,多目标满足率提升 8%。
3. 鲁棒性与扩展性
-
超参数敏感性:ES 倍数 K^ES=10 时性能最优,过大或过小均导致性能下降≤10%;
-
跨算法适配:适配 PPO 时,在 Walker-Stand 等任务中性能与 PPO(oracle 奖励)相当,部分任务差距≤5%;
-
新任务扩展:Walker-JumpRun 任务中,新增 “最大躯干高度” 测试后,TdRL 可快速学会跳跃前进,无需重新设计奖励。
4. 核心实验结果汇总
|
任务 |
评估指标 |
传统 SAC(Oracle 奖励) |
TdRL-ES |
性能提升幅度 |
|
Walker-Run |
躯干高度(≥1.2) |
1.12±0.01(未达标) |
1.30±0.01(达标) |
-(从无到有) |
|
Walker-Run |
平均速度 |
6.80±0.08 |
6.78±0.07 |
基本持平 |
|
Quadruped-Run |
平均速度(≥5) |
3.95±0.09(未达标) |
4.56±0.49(达标) |
+15.4% |
|
Cheetah-Run |
平均速度 |
9.44±0.19 |
9.88±0.08 |
+4.7% |
四、核心价值与适用场景
1. 技术突破点
-
简化任务设计:测试函数仅需定义单项目标阈值,无需平衡多目标权重,降低设计门槛;
-
理论收敛保障:轨迹返回函数的单调性证明确保策略向最优集收敛,避免训练发散;
-
抗奖励欺骗:轨迹级评估替代状态 - 动作级奖励,从根源减少奖励欺骗风险。
2. 适用场景
-
机器人连续控制:四足机器人奔跑、人形机器人行走等多目标任务(速度、稳定性、姿态达标);
-
自动驾驶:满足安全、效率、舒适等多约束的路径规划与控制;
-
工业流程优化:兼顾产能、能耗、质量的多目标生产调度。
五、结语
TdRL 通过 “测试函数定义目标 + 轨迹比较学习 + 理论收敛保障” 的创新链路,重构了 RL 的任务定义方式,将多目标优化、奖励设计难题转化为直观的测试函数设计。其在连续控制任务中的优异表现,为 RL 在真实场景的落地提供了低门槛、高稳健的新范式。
END

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)