小杰-自然语言处理(eight)——RNN——BiLSTM
绕屋树扶疏,当轩山嵯峨。
·
1. 引入
双向长短时记忆网络(Bidirectional Long Short-Term Memory,简称BiLSTM)是一种深度学习模型,是长短时记忆网络(LSTM)的扩展形式。
LSTM 只能单向捕捉过去依赖关系,而实际情况需捕捉过去与未来的依赖关系。
2.BiLSTM的结构
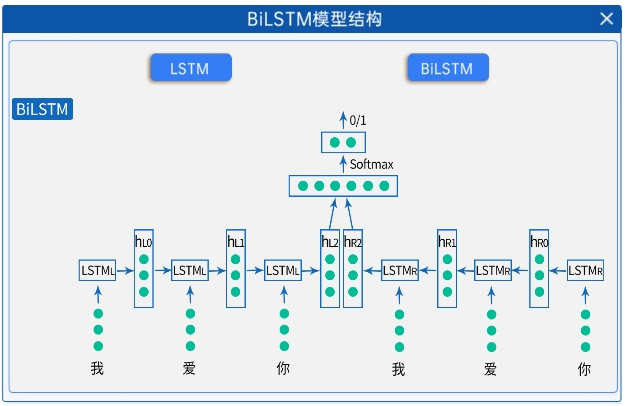
BiLSTM结构包含两个方向的LSTM网络:一个正向(forward)LSTM和一个反向(backward)LSTM。
两个方向的 LSTM 分别处理输入序列,将其隐藏状态拼接,使模型能同时利用每个位置的过去与未来信息,全面捕捉上下文。
如下面这个情感分类的例子,正向的LSTM按照从左到右的顺序处理“我”、“爱”、“你”,反向的LSTM按照从右到左的顺序处理“你”、“爱”、“我”,然后将两个LSTM的最后一个隐藏层拼接起来再经过softmax处理得到分类结果。
3.总结
BiLSTM相对于单向LSTM具有以下优势:
- 能够捕捉到输入序列中每个位置的过去和未来信息,更全面地捕捉序列中的上下文信息。
- 可以更好地处理长距离的依赖关系。
- 在许多自然语言处理任务中都取得了良好的效果。
代码
import torch
import torch.nn as nn
import numpy as np
text = "In Bejing Jack bought a basket of apples In Guangzhou Jack bought a basket of bananas"
chars = set(''.join(text))
chars = sorted(chars)
int2char = dict(enumerate(chars))
char2int = {char: ind for ind, char in int2char.items()}
input_seq = []
target_seq = []
# text去除最后一个作为输入
input_seq.append(text[:-1])
# text去除第一个作为目标
target_seq.append(text[1:])
input_seq = [[char2int[char] for char in seq] for seq in input_seq]
target_seq = [[char2int[char] for char in seq] for seq in target_seq]
dict_size = len(char2int)
seq_len = len(text) - 1
batch_size = 1
# 将输入和输出数据进行one-hot编码
def one_hot_encode(sequence, dict_size, seq_len, batch_size):
features = np.zeros((batch_size, seq_len, dict_size), dtype=np.float32)
for i in range(batch_size):
for u in range(seq_len):
features[i, u, sequence[i][u]] = 1
return features
# Input shape --> (Batch Size, Sequence Length, One-Hot Encoding Size)
input_seq = one_hot_encode(input_seq, dict_size, seq_len, batch_size)
input_seq = torch.from_numpy(input_seq)
target_seq = torch.Tensor(target_seq)
torch.manual_seed(10)
# 定义 LSTM 模型
class Model(nn.Module):
def __init__(self, input_size, output_size, hidden_dim, n_layers):
super(Model, self).__init__()
self.hidden_dim = hidden_dim
self.bilstm = nn.LSTM(input_size, hidden_dim, bidirectional=True)
self.fc = nn.Linear(hidden_dim * 2, output_size)
def forward(self, x):
out, hidden = self.bilstm(x)
out = out.contiguous().view(-1, self.hidden_dim * 2)
out = self.fc(out)
return out, hidden
n_epochs = 1000
lr = 0.01
model = Model(input_size=dict_size, output_size=dict_size, hidden_dim=16, n_layers=1)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
# 训练模型
for epoch in range(1, n_epochs + 1):
optimizer.zero_grad()
output, hidden = model(input_seq)
loss = criterion(output, target_seq.view(-1).long())
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print('Epoch: {}/{}.............'.format(epoch, n_epochs), end=' ')
print("Loss: {:.4f}".format(loss.item()))
# 访问LSTM模型的输入输出矩阵大小
print("input shape:", input_seq.shape)
print("out shape:", output.shape)
# 访问LSTM模型的权重和偏置
print("input_w shape:", model.bilstm.weight_ih_l0.shape)
print("input_b shape:", model.bilstm.bias_ih_l0.shape)
print("hidden_w shape:", model.bilstm.weight_hh_l0.shape)
print("hidden_b shape:", model.bilstm.bias_hh_l0.shape)
print("out_w shape:", model.fc.weight.shape)
print("out_b shape:", model.fc.bias.shape)
# 定义预测函数
def predict(model, character):
character = np.array([[char2int[c] for c in character]])
character = one_hot_encode(character, dict_size, character.shape[1], 1)
character = torch.from_numpy(character)
out, hidden = model(character)
prob = nn.functional.softmax(out[-1], dim=0).data
char_ind = torch.max(prob, dim=0)[1].item()
return int2char[char_ind], hidden
def sample(model, out_len, start='hey'):
model.eval() # eval mode
chars = [ch for ch in start]
size = out_len - len(chars)
for ii in range(size):
char, h = predict(model, chars)
chars.append(char)
return ''.join(chars)
result = sample(model, 41, 'In Bejing Jack bought a basket of')
print(result)

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)