使用cephadm安装ceph
某个OSD突然down掉,集群显示HEALTH_WARN。
·
环境准备
| 节点名称 | IP地址 | 角色 |
|
node1 |
192.168.2.16 |
mon/mgr osd |
|
node2 |
192.168.2.19 |
mon/mgr osd |
|
node3 |
192.168.2.18 |
mod/osd |
# 1. 系统要求(以CentOS 8为例)
cat /etc/os-release
# 2. 时间同步(关键!)
systemctl enable --now chronyd
chrony sources -v
# 3. 防火墙配置
firewall-cmd --zone=public --add-port=6789/tcp --permanent
firewall-cmd --zone=public --add-port=6800-7300/tcp --permanent
firewall-cmd --reload
# 4. SELinux设置
setenforce 0
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
#5. 同步
cat >> /etc/hosts <<EOF
192.168.2.16 node1
192.168.2.19 node2
192.168.2.18 node3
EOF
#6. 安装docker-ce
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum install docker-ce
systemctl start docker && systemctl enable docker
安装cephadm工具
# 安装官方包管理器
wget https://download.ceph.com/rpm-17.2.6/el8/noarch/cephadm
chmod +x cephadm
./cephadm add-repo --release 17.2.6
./cephadm install
######如果是Ubuntu系统自带这个包
apt install -y cephadm=17.2.7-0ubuntu0.22.04.2 lvm2 chrony
###安装完成后初始化集群
# 1. 初始化第一个Monitor节点,这里会下载国外镜像,可以修改cephadm命令,将镜像改为国内地址
vim /usr/sbin/cephadm
# Default container images -----------------------------------------------------
DEFAULT_IMAGE = 'swr.cn-north-4.myhuaweicloud.com/ddn-k8s/quay.io/ceph/ceph:v17.2.6'
DEFAULT_IMAGE_IS_MASTER = False
DEFAULT_IMAGE_RELEASE = 'quincy'
DEFAULT_PROMETHEUS_IMAGE = 'swr.cn-north-4.myhuaweicloud.com/ddn-k8s/quay.io/prometheus/prometheus:v2.43.0'
DEFAULT_LOKI_IMAGE = 'swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/grafana/loki:2.3.0'
DEFAULT_PROMTAIL_IMAGE = 'swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/grafana/promtail:2.3.0'
DEFAULT_NODE_EXPORTER_IMAGE = 'swr.cn-north-4.myhuaweicloud.com/ddn-k8s/quay.io/prometheus/node-exporter:v1.5.0'
DEFAULT_ALERT_MANAGER_IMAGE = 'swr.cn-north-4.myhuaweicloud.com/ddn-k8s/quay.io/prometheus/alertmanager:v0.25.0'
DEFAULT_GRAFANA_IMAGE = 'swr.cn-north-4.myhuaweicloud.com/ddn-k8s/quay.io/ceph/ceph-grafana:9.4.7'
DEFAULT_HAPROXY_IMAGE = 'swr.cn-north-4.myhuaweicloud.com/ddn-k8s/quay.io/ceph/haproxy:2.3'
DEFAULT_KEEPALIVED_IMAGE = 'swr.cn-north-4.myhuaweicloud.com/ddn-k8s/quay.io/ceph/keepalived:2.1.5'
DEFAULT_SNMP_GATEWAY_IMAGE = 'docker.1ms.run/maxwo/snmp-notifier:v1.2.1'
#DEFAULT_REGISTRY = 'docker.io' # normalize unqualified digests to this
####初始化
cephadm bootstrap --mon-ip 192.168.2.16
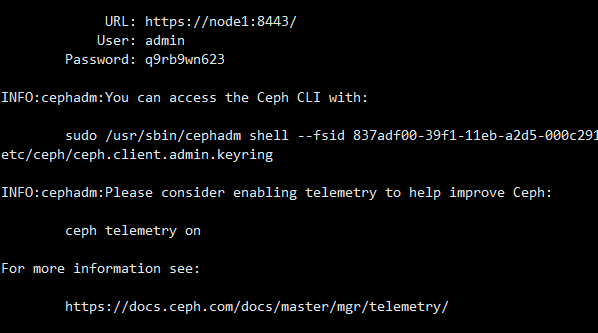
#####ceph dashboard汉化
1.安装必要软件、node版本需要16
yum install wget npm ng-common
2.下载源码并编译
wget https://download.ceph.com/tarballs/ceph-17.2.6.tar.gz
tar -zxvf ceph-17.2.6.tar.gz
cd ceph-17.2.6/src/pybind/mgr/dashboard/frontend
npm ci
####只编译中文
npx ng build --configuration=zh-Hans
#####编译全语言
./node_modules/.bin/ng build --localize --output-path=dist_localized --configuration=production
tar -zcvf dist.tar.gz dist
3.安装
1.将dist.tar.gz拷贝到部署mgr的节点
2.解压dist.tar.gz, 将里面的内容拷贝到容器/usr/share/ceph/mgr/dashboard/frontend/dist/, 并重启容器ceph-mgr服务。
docker cp zh-Hans ed4e79b9:/usr/share/ceph/mgr/dashboard/frontend/dist/
docker restart ed4e79b9
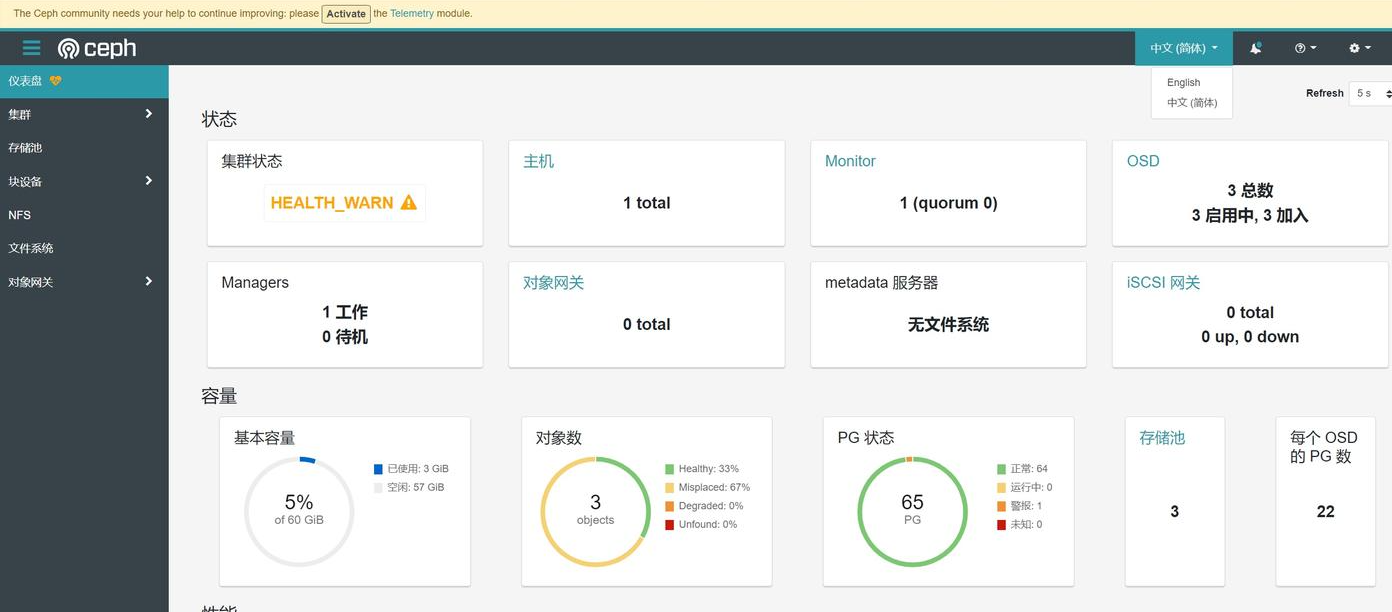
添加OSD节点
ssh-copy-id -f -i /etc/ceph/ceph.pub root@node2
cephadm shell -- ceph orch host add node2 192.168.2.19
ssh-copy-id -f -i /etc/ceph/ceph.pub root@node3
cephadm shell -- ceph orch host add node3 192.168.2.18
# 验证
cephadm shell -- ceph orch host ls
cephadm shell
root@node1:/# ceph orch daemon add osd node1:/dev/vdb
root@node1:/# ceph orch daemon add osd node2:/dev/vdb
root@node1:/# ceph orch daemon add osd node3:/dev/vdb
###验证ceph集群
cephadm shell -- ceph -s
###主机安装ceph操作集群
cephadm install ceph-common
配置存储池
# 1. 创建复制池(3副本)
ceph osd pool create mypool 128 128 replicated
# 2. 设置应用类型
ceph osd pool application enable mypool rbd
# 3. 设置CRUSH规则(机架级容错)
ceph osd crush rule create-replicated rack_rule default rack
ceph osd pool set mypool crush_rule rack_rule生产环境运维实战
性能监控与调优
核心监控指标
# 1. 集群整体健康状态
ceph health detail
# 2. 存储使用情况
ceph df
# 3. OSD性能统计
ceph osd perf
# 4. 慢查询监控
ceph osd slow-requests
# 5. PG状态分布
ceph pg stat性能调优参数
创建优化配置文件 /etc/ceph/ceph.conf:
[global]
# 网络优化
ms_bind_port_max = 7300
ms_bind_port_min = 6800
# OSD优化
osd_max_write_size = 512
osd_client_message_size_cap = 2147483648
osd_deep_scrub_interval = 2419200
osd_scrub_max_interval = 604800
# BlueStore优化
bluestore_cache_size_hdd = 4294967296
bluestore_cache_size_ssd = 8589934592
# 恢复控制
osd_recovery_max_active = 5
osd_max_backfills = 2
osd_recovery_op_priority = 2故障排查实战案例
案例一:OSD Down故障
现象:某个OSD突然down掉,集群显示HEALTH_WARN
# 1. 查看具体错误
ceph health detail
# HEALTH_WARN: 1 osds down
# 2. 定位问题OSD
ceph osd tree | grep down
# osd.3 down
# 3. 检查OSD日志
journalctl -u ceph-osd@3 -f
# 4. 尝试重启OSD
systemctl restart ceph-osd@3
# 5. 如果硬件故障,标记为out并替换
ceph osd out 3案例二:PG不一致修复
# 1. 发现不一致PG
ceph pg dump | grep inconsistent
# 2. 修复不一致数据
ceph pg repair 2.3f
# 3. 深度清理
ceph pg deep-scrub 2.3f案例三:磁盘空间不足
# 1. 检查使用率
ceph df detail
# 2. 找出占用最多的池
ceph osd pool ls detail
# 3. 临时提高告警阈值(紧急情况)
ceph config set global mon_osd_full_ratio 0.95
ceph config set global mon_osd_backfillfull_ratio 0.90
ceph config set global mon_osd_nearfull_ratio 0.85
# 4. 长期解决:添加OSD或删除数据
ceph orch daemon add osd node4:/dev/sdb容量规划与扩容策略
容量计算公式
可用容量 = 原始容量 × (1 - 副本数/副本数) × (1 - 预留空间比例)
# 例如:100TB原始容量,3副本,10%预留
# 可用容量 = 100TB × (1 - 3/3) × (1 - 0.1) = 30TB平滑扩容流程
# 1. 添加新OSD前设置
ceph config set global osd_max_backfills 1
ceph config set global osd_recovery_max_active 1
# 2. 逐个添加OSD
ceph orch daemon add osd node5:/dev/sdb
# 等待数据平衡完成
ceph -w
# 3. 恢复默认配置
ceph config rm global osd_max_backfills
ceph config rm global osd_recovery_max_active备份与灾难恢复
RBD快照备份
# 1. 创建快照
rbd snap create mypool/myimage@snapshot1
# 2. 导出快照
rbd export mypool/myimage@snapshot1 /backup/myimage.snapshot1
# 3. 跨集群复制
rbd mirror pool enable mypool image
rbd mirror image enable mypool/myimage集群级备份策略
# 1. 配置导出
ceph config dump > /backup/ceph-config.dump
# 2. CRUSH Map备份
ceph osd getcrushmap -o /backup/crushmap.bin
# 3. Monitor数据备份
ceph-mon --extract-monmap /backup/monmap高级运维技巧
自动化运维脚本
创建集群健康检查脚本:
#!/bin/bash
# ceph-health-check.sh
LOG_FILE="/var/log/ceph-health.log"
ALERT_EMAIL="admin@company.com"
check_health() {
HEALTH=$(ceph health --format json | jq -r '.status')
if [ "$HEALTH" != "HEALTH_OK" ]; then
echo"$(date): Cluster health is $HEALTH" >> $LOG_FILE
ceph health detail >> $LOG_FILE
# 发送告警邮件
echo"Ceph cluster health issue detected" | mail -s "Ceph Alert"$ALERT_EMAIL
fi
}
check_capacity() {
USAGE=$(ceph df --format json | jq -r '.stats.total_used_ratio')
THRESHOLD=0.80
if (( $(echo "$USAGE > $THRESHOLD" | bc -l) )); then
echo"$(date): Storage usage is ${USAGE}" >> $LOG_FILE
echo"Storage capacity warning" | mail -s "Ceph Capacity Alert"$ALERT_EMAIL
fi
}
main() {
check_health
check_capacity
}
main性能基准测试
# 1. RADOS性能测试
rados bench -p mypool 60 write --no-cleanup
rados bench -p mypool 60 seq
rados bench -p mypool 60 rand
# 2. RBD性能测试
rbd create --size 10G mypool/test-image
rbd map mypool/test-image
fio --name=rbd-test --rw=randwrite --bs=4k --size=1G --filename=/dev/rbd0
# 3. CephFS性能测试
mkdir /mnt/cephfs/test
fio --name=cephfs-test --rw=write --bs=1M --size=1G --directory=/mnt/cephfs/test生产环境最佳实践
安全配置
# 1. 启用认证
ceph config set mon auth_cluster_required cephx
ceph config set mon auth_service_required cephx
ceph config set mon auth_client_required cephx
# 2. 创建专用用户
ceph auth get-or-create client.backup mon 'allow r' osd 'allow rwx pool=mypool'
# 3. 网络加密
ceph config set global ms_cluster_mode secure
ceph config set global ms_service_mode secure日志管理
# 1. 配置日志轮转
cat > /etc/logrotate.d/ceph << EOF
/var/log/ceph/*.log {
daily
rotate 30
compress
sharedscripts
postrotate
systemctl reload ceph.target
endscript
}
EOF
# 2. 调整日志级别
ceph config set global debug_osd 1/5
ceph config set global debug_mon 1/5升级策略
# 1. 滚动升级前检查
ceph status
ceph versions
# 2. 升级OSD节点
ceph orch upgrade start --ceph-version 15.2.14
# 3. 监控升级进度
ceph orch upgrade status常见问题与解决方案
Q1: 新添加的OSD不平衡数据怎么办?
# 手动触发数据平衡
ceph osd reweight-by-utilization 105
# 调整特定OSD权重
ceph osd crush reweight osd.6 2.0Q2: 集群时钟偏差导致的问题
# 检查时钟偏差
ceph time-sync-status
# 修复方案
systemctl restart chronyd
ceph config set global mon_clock_drift_allowed 0.5Q3: 大量慢查询如何优化?
# 分析慢查询
ceph daemon osd.0 dump_historic_ops
# 临时缓解
ceph tell 'osd.*' injectargs '--osd-op-complaint-time 30'
# 永久优化
ceph config set osd osd_op_complaint_time 30
开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐

 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)