【第四周】论文精读:DARP: Difference-Aware Retrieval Policies for Imitation Learning
摘要:华盛顿大学与丰田研究所等机构提出DARP框架,解决行为克隆(BC)中的分布偏移问题。DARP通过检索训练数据的k近邻,利用查询状态与邻居状态的差异向量预测局部动作,并聚合生成最终决策,隐式实现拉普拉斯平滑以抑制高频方差。实验显示,DARP在连续控制、机器人操作及视觉任务中性能提升15%-46%,无需额外数据或专家反馈。核心创新包括差异感知机制和半参数架构设计,平衡了非参数检索的鲁棒性与参数化
前言:行为克隆(Behavior Cloning, BC)是模仿学习中最简单且广泛使用的方法,但其在部署时极易受分布偏移(Covariate Shift)影响,导致误差累积和策略崩溃。来自华盛顿大学与丰田研究所等机构的研究团队提出了 DARP (Difference-Aware Retrieval Policies),一种半参数的检索增强模仿学习框架。DARP 创新性地不再直接学习“状态到动作”的全局映射,而是通过检索训练数据中的 k k k 个最近邻,利用查询状态与邻居状态的差异向量来预测局部动作,并通过聚合生成最终决策。理论证明 DARP 隐式实现了拉普拉斯平滑(Laplacian Smoothing),能有效抑制高频方差。实验显示,DARP 在连续控制、机器人操作及高维视觉任务中,相比标准 BC 取得了 15%-46% 的性能提升,且无需任何额外数据或专家反馈。
关键词解释:BC学习
关键词解释:拉普拉斯平滑 (Laplace Smoothing)
📄 论文基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | Difference-Aware Retrieval Policies for Imitation Learning |
| 核心方法名 | DARP (Difference-Aware Retrieval Policies) |
| 作者 | Quinn Pfeifer, Ethan Pronovost, Paarth Shah, et al. |
| 所属机构 | University of Washington, Toyota Research Institute, Google DeepMind, Mila |
| 发表年份 | 2026 (ICLR Conference Paper) |
| 核心领域 | Imitation Learning, Behavior Cloning, Retrieval-Augmented Generation, Manifold Regularization |
| 关键数据集 | MuJoCo (Hopper, Ant, etc.), Robosuite, RoboCasa, Push-T (Multi-modal) |
| 代码开源 | 承诺公开源代码与配置 |
🔍 研究背景与痛点
1. 行为克隆(BC)的致命弱点:协变量偏移
- 误差累积:BC 仅在专家演示的状态分布上最小化监督损失。一旦部署中因微小误差进入分布外(OOD)状态,策略往往产生高方差、不可靠的动作,导致任务失败。
- 全局拟合的局限:传统 BC 试图用一个全局参数化函数拟合所有数据,容易在低密度区域产生剧烈震荡(过拟合噪声),缺乏对数据流形结构的感知。
2. 现有解决方案的不足
- 显式正则化:如添加平滑性惩罚项,需要调节超参数 λ \lambda λ,且可能改变优化景观。
- 纯非参数方法:如最近邻策略(R&P)或局部加权回归(LWR),虽能利用局部结构,但难以处理多模态分布,且对距离度量极度敏感,泛化能力弱。
- 额外依赖:许多改进方法需要模拟器、在线专家反馈或次优数据,违背了纯 BC 的设定。
3. DARP 的核心洞察
- 隐式流形正则化:通过将“邻域聚合”操作嵌入到模型架构中而非损失函数中,可以隐式地实现拉普拉斯平滑,无需调节正则化系数。
- 差异感知(Difference-Aware):仅检索邻居状态是不够的,必须显式输入查询状态与邻居状态的差异向量( Δ s = s n e i g h b o r − s q u e r y \Delta s = s_{neighbor} - s_{query} Δs=sneighbor−squery),让模型学习动作随状态微扰的变化规律。
- 半参数优势:结合了参数化模型的学习能力(处理多模态、复杂映射)和非参数检索的鲁棒性(锚定在真实数据分布上)。
🛠️ 核心方法:DARP 架构详解
DARP 的工作流程分为训练和推理两个阶段,核心在于重新参数化了策略函数。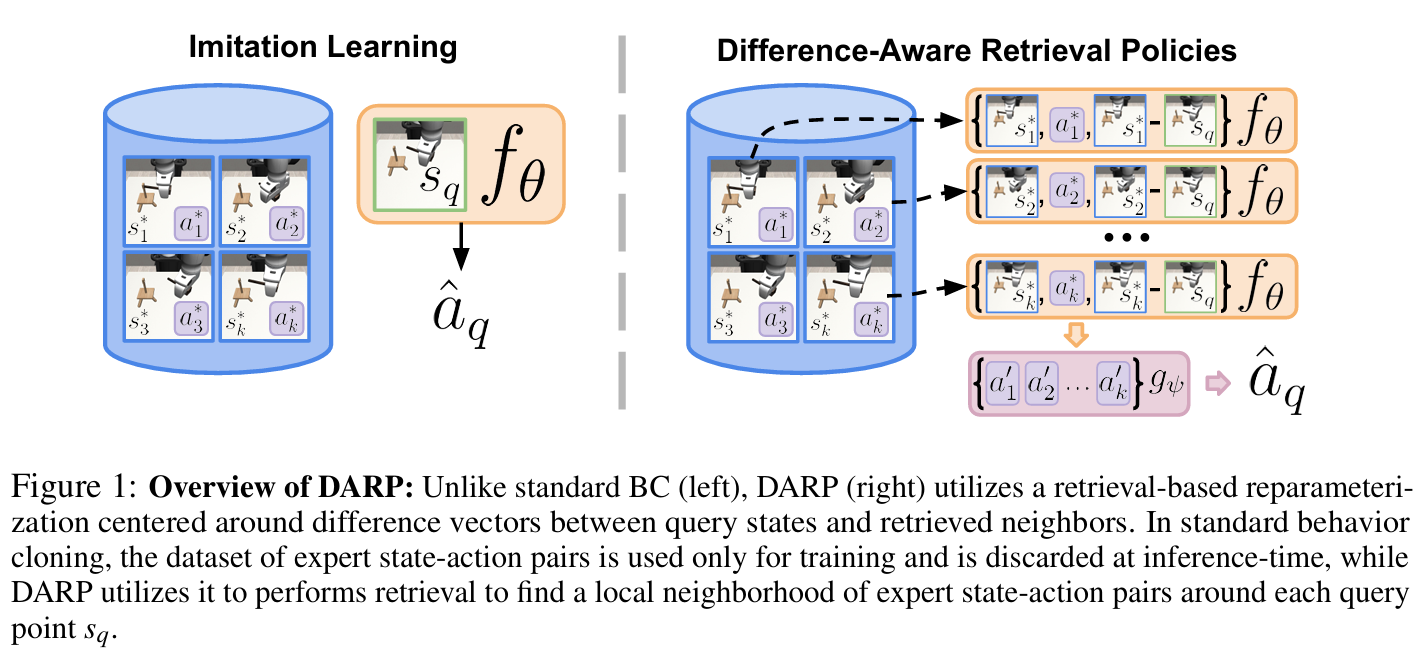
1. 策略重参数化
传统 BC 学习 π ( s ) → a \pi(s) \to a π(s)→a。
DARP 学习一个条件函数 f θ f_\theta fθ,其输入为三元组 ( s i ∗ , a i ∗ , Δ s i ) (s^*_i, a^*_i, \Delta s_i) (si∗,ai∗,Δsi),其中:
- s i ∗ , a i ∗ s^*_i, a^*_i si∗,ai∗:检索到的专家邻居状态及其动作。
- Δ s i = s i ∗ − s q \Delta s_i = s^*_i - s_q Δsi=si∗−sq:邻居状态与当前查询状态 s q s_q sq 的差异向量。
2. 推理流程(Inference)
对于任意查询状态 s q s_q sq:
- 检索(Retrieval):从训练集 D ∗ D^* D∗ 中检索 k k k 个最近邻状态 { s i ∗ } i = 1 k \{s^*_i\}_{i=1}^k {si∗}i=1k(基于欧氏距离或嵌入空间距离)。
- 局部预测(Local Prediction):对每个邻居,计算差异向量 Δ s i \Delta s_i Δsi,输入网络得到候选动作:
a i ′ = f θ ( s i ∗ , a i ∗ , Δ s i ) a'_i = f_\theta(s^*_i, a^*_i, \Delta s_i) ai′=fθ(si∗,ai∗,Δsi)
注:这里显式利用差异向量,使模型能根据当前位置相对邻居的偏移,自适应调整动作。 - 聚合(Aggregation):通过置换不变函数 g ψ g_\psi gψ(如平均或 Set Transformer)聚合所有候选动作:
a ^ q = g ψ ( { a i ′ } i = 1 k ) \hat{a}_q = g_\psi(\{a'_i\}_{i=1}^k) a^q=gψ({ai′}i=1k)- 若 g g g 为平均,则隐含高斯分布假设。
- 若 g g g 为参数化网络(如 Set Transformer),可输出高斯混合模型(GMM)或扩散模型参数,处理多模态动作。
3. 训练目标
尽管架构复杂,训练目标依然是标准的行为克隆损失(MSE 或 NLL):
L = E ( s q , a q ) ∼ D ∗ [ ∥ a ^ q − a q ∥ 2 ] \mathcal{L} = \mathbb{E}_{(s_q, a_q) \sim D^*} [ \| \hat{a}_q - a_q \|^2 ] L=E(sq,aq)∼D∗[∥a^q−aq∥2]
- 关键点:不需要修改损失函数添加正则项。架构本身的设计(检索 + 差异输入 + 聚合)隐式强制了策略在数据流形上的平滑性。
4. 理论保证:隐式拉普拉斯平滑
- 谱分析:论文证明 DARP 的聚合操作等价于在 k k k-NN 图上应用了一个固定的低通滤波器 ϕ ( μ ) = 1 − μ \phi(\mu) = 1 - \mu ϕ(μ)=1−μ(其中 μ \mu μ 是图拉普拉斯特征值)。
- 效果:该滤波器保留了低频模式(平滑变化的动作),强力抑制了高频模式(剧烈震荡的噪声),且无需像显式正则化那样调节 λ \lambda λ 参数。这保证了策略在局部邻域内的 Lipschitz 连续性,从而提升稳定性。
🏆 实验结果与分析
作者在多个基准测试中评估了 DARP,涵盖低维状态、高维视觉及多模态任务。
1. 性能全面超越 BC (Q1)
在 MuJoCo 和 Robosuite/RoboCasa 任务中,DARP 均取得显著提升:
- MuJoCo ( locomotion):
- Hopper: DARP (3545) vs BC (2313) -> 提升 53%。
- HalfCheetah: DARP (5515) vs BC (1063) -> 提升 418% (极端案例,BC 几乎失效)。
- Robosuite (Manipulation):
- Stack: DARP (72%) vs BC (47%) -> 提升 53%。
- Threading: DARP (63%) vs BC (37%) -> 提升 70%。
- 对比其他基线:DARP 显著优于纯非参数方法(R&P, LWR)和显式正则化方法(MRIL, CCIL)。
2. 高维视觉与多模态适应性 (Q2)
- 视觉输入:在使用 R3M 图像嵌入作为状态输入时,DARP 的平均提升幅度(~35%)甚至高于低维状态任务,证明其在高维空间中更能利用局部结构。
- 多模态动作:在 Push-T 任务(需多模态策略)中,结合 GMM 头的 DARP 达到 70% 成功率,远超 BC 的 48%。
- 不连续环境:在专门设计的“长迷宫”不连续环境中,DARP (57%) 依然大幅领先 BC (25%),证明差异向量和聚合机制能有效区分看似相近但动作迥异的状态。
3. 消融实验关键发现 (Q3)
- 差异向量 ( Δ s \Delta s Δs) 至关重要:移除差异向量(仅输入 s i ∗ , a i ∗ s^*_i, a^*_i si∗,ai∗)导致性能大幅下降,证明模型必须感知“相对位置”才能做出正确修正。
- 置换不变聚合:使用置换相关(Permutation-dependent)的聚合器会破坏性能,验证了理论中关于对称性的假设。
- 邻居动作的作用:虽然重要,但相比差异向量,其贡献略小;不过保留 a i ∗ a^*_i ai∗ 仍能提供直接的行动参考。
4. 鲁棒性与发散分析
- 发散点分析:在 BC 失败的 rollout 中,DARP 往往能在 BC 进入低概率 OOD 状态时,利用邻近的高概率专家数据将其“拉回”正轨。
- 恢复能力:即使在 BC 已经严重偏离的分支上启动 DARP,它也能迅速恢复高分表现,而 BC 无法自救。
💡 主要创新点总结
-
架构即正则化(Architecture as Regularization):
- 首次提出通过检索增强的架构设计隐式实现拉普拉斯平滑,避免了显式正则化超参数调节的麻烦,同时保持了标准 BC 的训练目标。
-
差异感知机制(Difference-Aware Mechanism):
- 创新性地将状态差异向量作为核心输入,使模型能够学习动作场在局部流形上的梯度变化,而非死记硬背绝对状态的动作。
-
半参数策略范式:
- 巧妙结合了非参数检索的数据锚定能力(减少外推风险)和参数化网络的表达能力(处理多模态和复杂映射),在鲁棒性和灵活性之间找到了最佳平衡点。
-
理论驱动的谱分析:
- 从谱图理论角度严格证明了 DARP 等价于一个固定的低通滤波器,为检索增强策略的平滑性提供了坚实的数学基础。
⚠️ 局限性与挑战
- 检索开销:推理时需要实时检索 k k k 个最近邻,虽然论文指出在 k = 500 k=500 k=500 时仍能满足 >200Hz 的控制频率,但在超大规模数据集上可能需要高效的近似最近邻搜索(ANN)。
- 距离度量敏感性:虽然对欧氏距离和余弦相似度表现稳健,但在极高维或语义复杂的视觉空间中,距离度量的选择仍需谨慎(需配合好的表征如 R3M)。
- 存储需求:需要存储完整的专家演示数据集用于推理,这在内存受限的嵌入式机器人平台上可能是一个挑战。
📝 总结与工程建议
《DARP》展示了如何通过简单的架构修改(检索 + 差异输入 + 聚合)来解决模仿学习中长期存在的分布偏移问题。它证明了利用训练数据进行推理时增强(Test-time Augmentation with Training Data)的巨大潜力。
🚀 对开发者的实战建议:
-
引入检索增强推理:
- 在部署 BC 策略时,不要丢弃训练数据。构建一个向量数据库,在推理时检索相似的历史状态,利用这些信息修正当前预测。
-
使用差异向量作为特征:
- 在设计检索增强模型时,务必计算Query 与 Neighbor 的差异向量( Δ x = x n e i g h b o r − x q u e r y \Delta x = x_{neighbor} - x_{query} Δx=xneighbor−xquery)并输入网络。这比单纯拼接绝对状态更能激发模型的局部泛化能力。
-
隐式平滑替代显式正则:
- 如果面临策略震荡问题,尝试这种“检索 - 预测 - 聚合”的架构,而不是盲目调整 Loss 中的正则化系数。这种架构天然具有低通滤波效果。
-
处理多模态分布:
- 聚合模块可以使用 Set Transformer 或 DeepSets 结构,输出 GMM 或扩散模型参数,从而优雅地处理多模态动作分布,避免平均化导致的模糊动作。
-
高效检索优化:
- 对于实时系统,结合 FAISS 等库进行近似最近邻搜索,并限制 k k k 的大小(论文建议 k ≈ 500 k \approx 500 k≈500 即可达到最优),以平衡精度与延迟。
一句话总结:DARP 通过“差异感知的检索聚合”架构,将训练数据转化为推理时的稳定器,以极小的工程代价实现了模仿学习在分布外状态下的鲁棒性飞跃,是构建高可靠机器人策略的优选方案。
参考文献:
[1] Pfeifer Q, Pronovost E, Shah P, et al. Difference-Aware Retrieval Policies for Imitation Learning[C]//The Thirteenth International Conference on Learning Representations (ICLR). 2026.

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)