深度学习模型在多领域预测中的应用:以BiLSTM为例
BiLSTM是一种特殊的循环神经网络(RNN)架构。与传统RNN只能按顺序处理序列数据不同,BiLSTM可以同时从正向和反向处理序列。这使得它能够更好地捕捉序列中的长期依赖关系,无论是过去的信息还是未来的信息,对于预测任务非常有帮助。在自然语言处理(NLP)领域,比如情感分析,BiLSTM可以同时考虑一个句子中单词之前和之后的上下文信息,从而更准确地判断情感倾向。# 样本数据# 文本向量化# 构建
BiLSTM,双向长短期记忆 算法实现,交通流量预测,负荷预测,风力发电预测,深度学习,自然语言处理nlp,情感分析,时间序列预测, 【时间序列】【多元回归】 多输入,多变量,多步长,基于MATLAB。
在当今数据驱动的时代,预测任务在众多领域都扮演着至关重要的角色。从交通流量管理到电力负荷预测,再到风力发电预测,准确的预测能够帮助我们更好地规划资源、优化运营。而深度学习技术,尤其是像双向长短期记忆(BiLSTM)这样的模型,在这些预测任务中展现出了强大的能力。同时,结合MATLAB平台,我们可以更便捷地实现这些算法。
BiLSTM模型概述
BiLSTM是一种特殊的循环神经网络(RNN)架构。与传统RNN只能按顺序处理序列数据不同,BiLSTM可以同时从正向和反向处理序列。这使得它能够更好地捕捉序列中的长期依赖关系,无论是过去的信息还是未来的信息,对于预测任务非常有帮助。
在自然语言处理(NLP)领域,比如情感分析,BiLSTM可以同时考虑一个句子中单词之前和之后的上下文信息,从而更准确地判断情感倾向。以下是一个简单的使用Keras构建BiLSTM模型进行文本分类(可类比情感分析)的代码示例:
from keras.models import Sequential
from keras.layers import Embedding, Bidirectional, LSTM, Dense
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
import numpy as np
# 样本数据
texts = ['I love this product', 'This is terrible']
labels = [1, 0]
# 文本向量化
tokenizer = Tokenizer(num_words = 1000)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
data = pad_sequences(sequences, maxlen = 100)
# 构建BiLSTM模型
model = Sequential()
model.add(Embedding(1000, 128, input_length = 100))
model.add(Bidirectional(LSTM(128)))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(data, np.array(labels), epochs = 10, batch_size = 32)在这段代码中,首先我们使用Tokenizer对文本进行向量化处理,将文本转化为数字序列。然后通过Embedding层将这些数字映射到低维向量空间。Bidirectional包裹着LSTM层,使得模型能够双向处理序列数据。最后通过一个全连接层Dense进行分类,激活函数sigmoid适用于二分类任务。
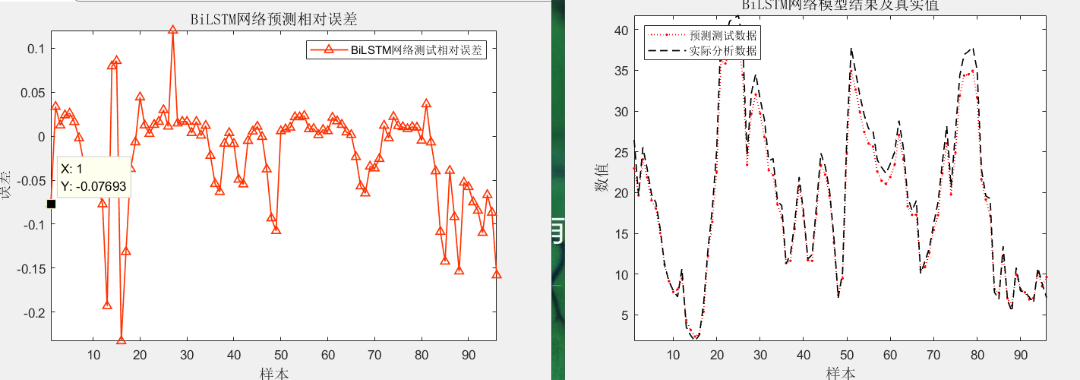
在时间序列预测中的应用
时间序列预测在很多领域都有应用,如交通流量预测、电力负荷预测和风力发电预测等。这些预测通常面临多输入、多变量和多步长的挑战。
以电力负荷预测为例,输入可能包括历史负荷数据、天气数据(温度、湿度等多变量),预测未来多个时间步长的负荷值(多步长)。基于MATLAB实现一个简单的基于BiLSTM的时间序列预测代码如下:
% 生成模拟数据,假设我们有历史负荷数据和温度数据
loadData = randn(1000, 1); % 模拟历史负荷数据
tempData = randn(1000, 1); % 模拟温度数据
inputData = [loadData, tempData];
% 划分训练集和测试集
trainData = inputData(1:800, :);
testData = inputData(801:end, :);
% 创建BiLSTM网络
numFeatures = size(trainData, 2);
numHiddenUnits = 50;
layers = [...
sequenceInputLayer(numFeatures)
bilstmLayer(numHiddenUnits, 'OutputMode', 'last')
fullyConnectedLayer(1)
regressionLayer];
% 训练网络
options = trainingOptions('adam',...
'MaxEpochs', 50,...
'GradientThreshold', 1,...
'InitialLearnRate', 0.001,...
'LearnRateSchedule', 'piecewise',...
'LearnRateDropPeriod', 10,...
'LearnRateDropFactor', 0.2,...
'Verbose', 0,...
'Plots', 'training-progress');
net = trainNetwork(trainData, loadData(1:800), layers, options);
% 预测
predictedLoad = predict(net, testData);在这段MATLAB代码中,我们首先生成了模拟的负荷数据和温度数据作为多变量输入。然后将数据划分为训练集和测试集。接着构建了一个BiLSTM网络,sequenceInputLayer作为输入层,接收多变量序列数据。bilstmLayer定义了双向LSTM层,这里OutputMode设置为last表示只输出序列最后一个时间步的隐藏状态。fullyConnectedLayer和regressionLayer用于回归预测。通过trainNetwork进行训练,并使用训练好的模型对测试数据进行预测。
多元回归与BiLSTM的对比
传统的多元回归方法也常用于多变量预测任务。多元回归通过建立因变量与多个自变量之间的线性关系来进行预测。例如,对于电力负荷预测,如果自变量是温度、湿度等,多元回归会找到一个线性方程来描述负荷与这些变量之间的关系。
然而,与BiLSTM相比,多元回归假设数据之间存在线性关系,对于复杂的、非线性的时间序列数据表现可能不佳。BiLSTM则能够自动学习数据中的复杂模式,包括非线性关系,在处理具有长期依赖的时间序列数据上更具优势。
总结
BiLSTM作为深度学习中的强大模型,在交通流量预测、负荷预测、风力发电预测等多个领域以及自然语言处理的情感分析等任务中都有出色的表现。通过MATLAB等平台,我们可以方便地实现这些模型,并结合多输入、多变量和多步长的实际需求进行定制化的预测。在面对复杂的预测问题时,BiLSTM相较于传统的多元回归等方法,能够更好地挖掘数据中的潜在信息,为我们提供更准确的预测结果。无论是优化城市交通,还是保障电力供应的稳定性,这些技术都在发挥着越来越重要的作用。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐


 36
36 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)