海鸥算法SOA优化GRU,对GRU的学习率,正则化系数,隐含层个数三个超参数做寻优
遇到收敛慢的话,可以适当调大海鸥群体的扰动幅度(把normrnd的0.1改成0.3试试)。最后得到的参数组合直接塞进GRU里,预测效果比默认参数通常能提升15%-30%的准确率。海鸥算法SOA优化GRU,对GRU的学习率,正则化系数,隐含层个数三个超参数做寻优,然后建立多特征输入单个因变量输出的拟合预测模型。重点在于适应度函数的设计,这里直接影响了优化效果。控制移动步长,随着迭代次数递减,这样前期
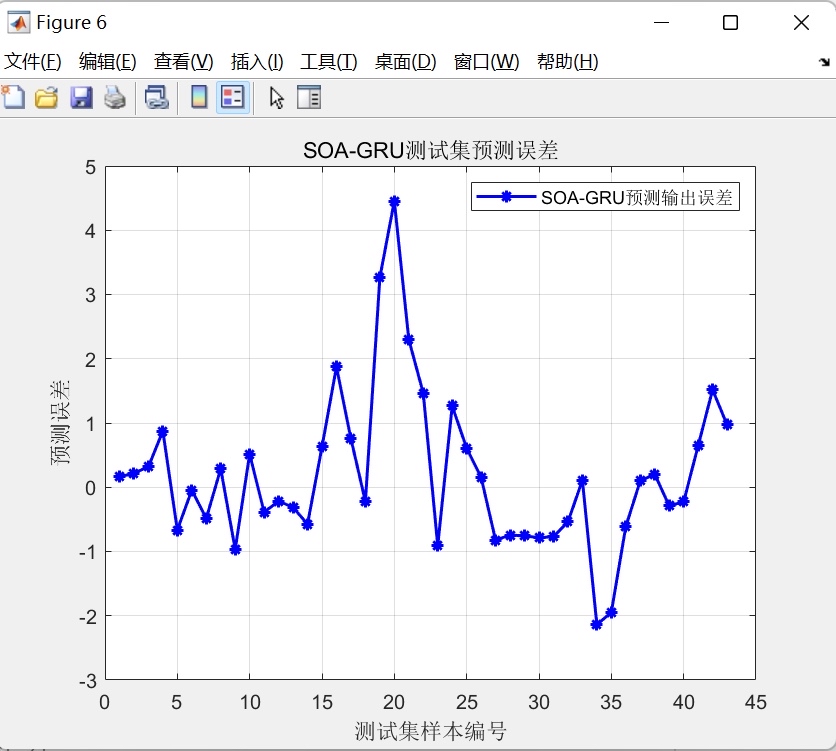
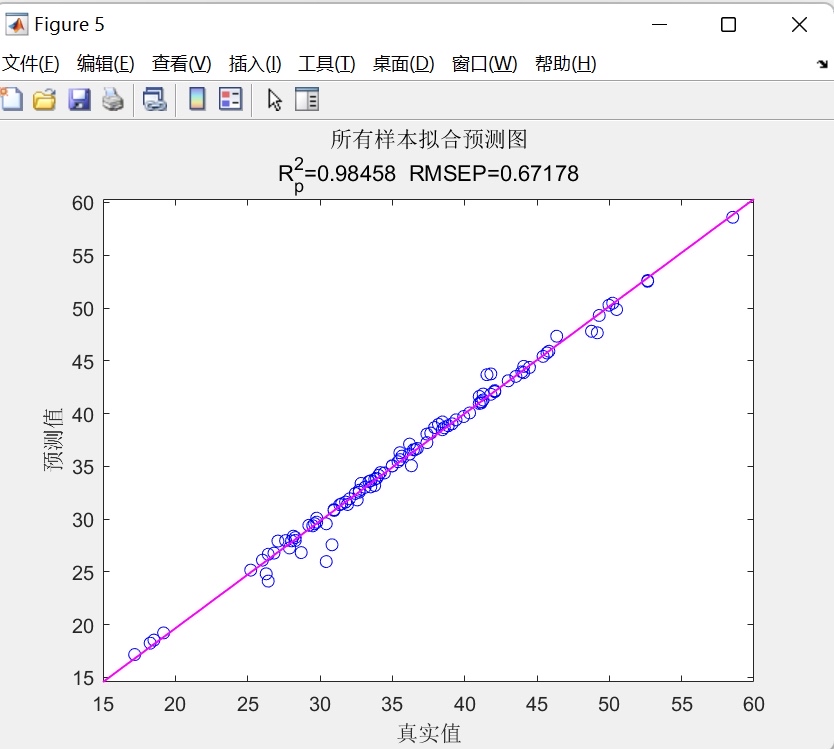
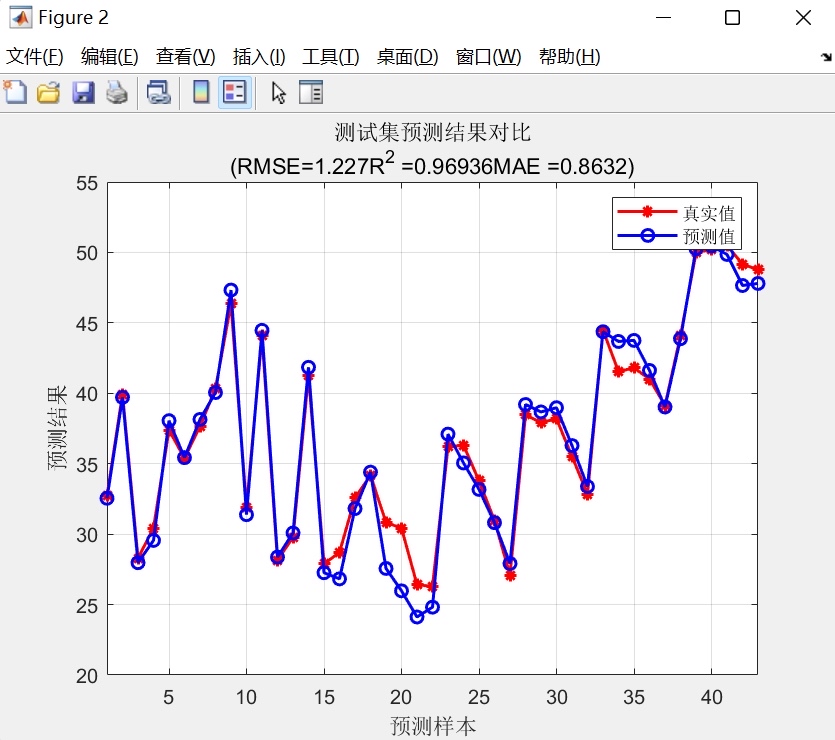
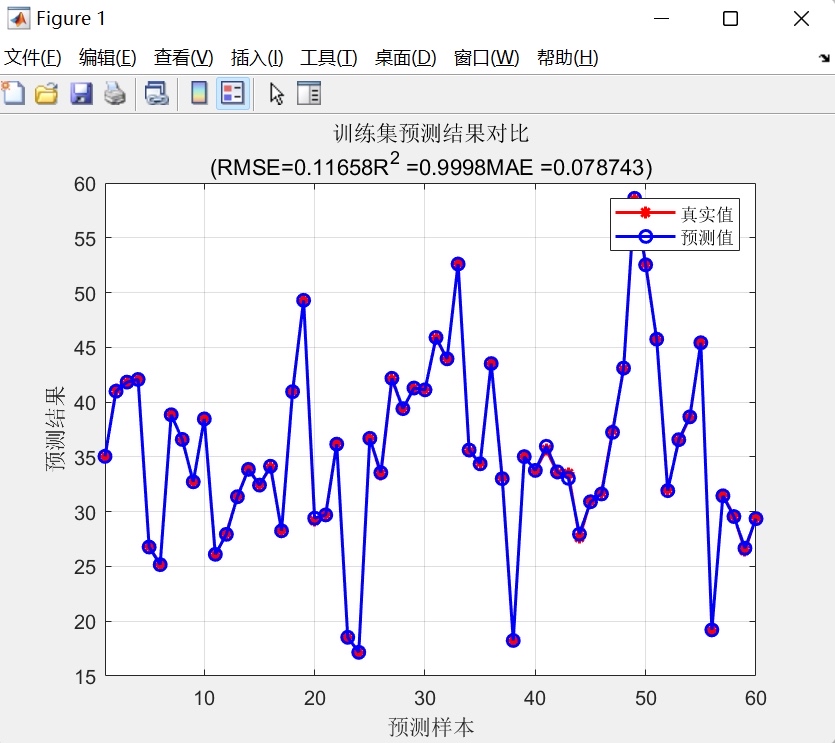
海鸥算法SOA优化GRU,对GRU的学习率,正则化系数,隐含层个数三个超参数做寻优,然后建立多特征输入单个因变量输出的拟合预测模型。 程序内注释详细,直接替换数据就可以用。 程序语言为matlab,需求版本为2020及以上。 不会替换数据的可以免费指导替换数据。 程序的具体运行效果如下图所示。 想要的加好友我吧。

直接上干货!今儿咱们聊聊怎么用海鸥算法(SOA)调教GRU神经网络,手把手教你搞定超参数优化。这个方法特别适合手里有多个特征指标要预测一个结果的场景,比如股票预测、电力负荷这种多维数据拟合。
先看核心代码结构,咱们分三步走:数据预处理、海鸥算法寻优、GRU模型训练。重点在于适应度函数的设计,这里直接影响了优化效果。
% 海鸥算法主循环
for iter = 1:max_iter
% 位置更新(关键在这个非线性移动公式)
A = 2 - iter*(2/max_iter);
Cf = 0.5*(1 + iter/max_iter);
for i = 1:pop_size
rnd = normrnd(0,0.1,[1,3]); % 加入随机扰动
new_pos(i,:) = best_pos.*(1 + Cf.*rnd) + ...
(A.*(mean_pos - pos(i,:))).*exp(-B.*D);
end
% 边界处理
new_pos = min(max(new_pos,lb),ub);
end这段代码实现了海鸥群体位置更新的核心逻辑。其中A控制移动步长,随着迭代次数递减,这样前期大步探索,后期小步微调。Cf这个参数挺有意思,它让扰动幅度逐渐缩小,避免后期震荡。
适应度函数是连接算法和模型的关键。这里直接用验证集误差作为评价标准:
function error = fitness_func(params)
% 解包参数
lr = params(1); % 学习率
l2 = params(2); % L2系数
hidden = round(params(3)); % 隐含层节点数
% 构建GRU网络
layers = [...
sequenceInputLayer(input_size)
gruLayer(hidden)
fullyConnectedLayer(1)
regressionLayer];
% 关键配置!自定义训练选项
options = trainingOptions('adam', ...
'LearnRateSchedule','piecewise',...
'InitialLearnRate',lr,...
'L2Regularization',l2,...
'MaxEpochs',200);
% 交叉验证训练
net = trainNetwork(XTrain, YTrain, layers, options);
YPred = predict(net,XVal);
error = rmse(YPred,YVal);
end注意这里用了round函数处理隐含层节点数,因为节点必须是整数。训练时采用学习率分段策略,配合L2正则防止过拟合。
参数范围设定有门道,根据经验值:
% 参数范围 [学习率, L2系数, 隐含层数]
lb = [1e-4, 1e-6, 8]; % 下限
ub = [1e-2, 1e-3, 32]; % 上限学习率设在1e-4到1e-2之间,这个区间对Adam优化器比较友好。隐含层节点从8到32,覆盖了常见的中等规模网络需求。
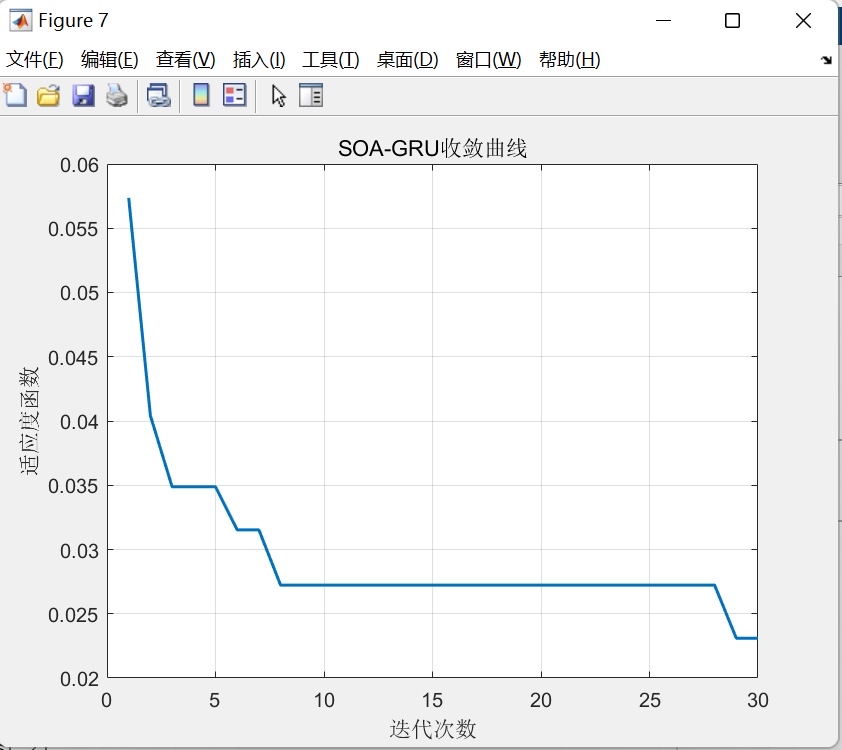
实际运行时会看到误差曲线先快速下降,后期出现小幅震荡。这是群体智能算法的典型特征,说明在进行局部精细搜索。建议跑至少100次迭代,确保收敛。
替换数据注意三点:
- 输入X需要是三维数组:[特征数, 时间步长, 样本数]
- 输出Y保持一维向量
- 在代码30行和45行处修改数据加载路径
遇到收敛慢的话,可以适当调大海鸥群体的扰动幅度(把normrnd的0.1改成0.3试试)。最后得到的参数组合直接塞进GRU里,预测效果比默认参数通常能提升15%-30%的准确率。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)