探索PSO-kelm在时间序列预测中的魅力
PSO-kelm:粒子群优化kelm用于时序预测核极限学习机 时间序列预测自带数据集,代码注释详细,适合新手学习,效果非常好。在数据分析与预测的领域,时间序列预测始终占据着重要位置。今天咱就来聊聊一种超棒的预测方法——PSO-kelm,也就是粒子群优化核极限学习机(Kernel Extreme Learning Machine)用于时间序列预测。
PSO-kelm:粒子群优化kelm用于时序预测 核极限学习机 时间序列预测 自带数据集,代码注释详细,适合新手学习,效果非常好。
在数据分析与预测的领域,时间序列预测始终占据着重要位置。今天咱就来聊聊一种超棒的预测方法——PSO-kelm,也就是粒子群优化核极限学习机(Kernel Extreme Learning Machine)用于时间序列预测。
核极限学习机(KELM)
核极限学习机是极限学习机在非线性系统中的拓展。传统的极限学习机(ELM)训练单隐层前馈神经网络时,随机产生输入层与隐含层间的连接权值及隐含层神经元的阈值,且在训练过程中无需调整,只需要设置隐含层神经元的个数,就可以获得唯一的最优解,训练速度快。而KELM则是通过引入核函数,将低维输入空间映射到高维特征空间,从而能更好地处理非线性问题。
比如,在Python中我们可以简单实现一个基础的KELM模型框架(这里只是简单示意,实际应用会更复杂):
import numpy as np
from sklearn.metrics.pairwise import rbf_kernel
class SimpleKELM:
def __init__(self, kernel='rbf', gamma=1.0):
self.kernel = kernel
self.gamma = gamma
self.beta = None
def fit(self, X, y):
if self.kernel == 'rbf':
K = rbf_kernel(X, gamma=self.gamma)
else:
raise ValueError('Unsupported kernel')
H = K + np.eye(K.shape[0]) * 1e-6 # 防止矩阵不可逆
self.beta = np.linalg.inv(H).dot(y)
return self
def predict(self, X):
if self.kernel == 'rbf':
K_test = rbf_kernel(X, gamma=self.gamma)
else:
raise ValueError('Unsupported kernel')
return K_test.dot(self.beta)
这段代码里,我们先定义了一个SimpleKELM类,初始化时设置核函数类型和核参数gamma。fit方法用于训练模型,通过核函数计算核矩阵,然后求逆得到输出权重beta。predict方法则利用训练好的权重和新数据的核矩阵进行预测。
粒子群优化(PSO)
粒子群优化算法是一种基于群体智能的优化算法。想象一群鸟在找食物,每只鸟(粒子)都在解空间中飞行,它们根据自己找到的最好位置(个体最优解)和整个鸟群找到的最好位置(全局最优解)来调整自己的飞行方向和速度。在PSO-kelm里,我们就用PSO来优化KELM的参数,让KELM能在时间序列预测中发挥更好的效果。
简单的PSO代码示例(同样简化示意):
import numpy as np
def pso(func, dim, pop_size, max_iter, w=0.729, c1=1.49445, c2=1.49445,
bounds=(0, 1)):
v_high = (bounds[1] - bounds[0]) * 0.2
v_low = -v_high
x = np.random.uniform(bounds[0], bounds[1], (pop_size, dim))
v = np.random.uniform(v_low, v_high, (pop_size, dim))
pbest = x.copy()
pbest_fitness = np.array([func(i) for i in x])
gbest_index = np.argmin(pbest_fitness)
gbest = pbest[gbest_index]
gbest_fitness = pbest_fitness[gbest_index]
for _ in range(max_iter):
r1 = np.random.rand(pop_size, dim)
r2 = np.random.rand(pop_size, dim)
v = w * v + c1 * r1 * (pbest - x) + c2 * r2 * (gbest - x)
v = np.clip(v, v_low, v_high)
x = x + v
fitness = np.array([func(i) for i in x])
improved = fitness < pbest_fitness
pbest[improved] = x[improved]
pbest_fitness[improved] = fitness[improved]
current_best_index = np.argmin(pbest_fitness)
if pbest_fitness[current_best_index] < gbest_fitness:
gbest = pbest[current_best_index]
gbest_fitness = pbest_fitness[current_best_index]
return gbest, gbest_fitness
这段PSO代码,func是要优化的目标函数,dim是参数维度,popsize是粒子数量,maxiter是最大迭代次数。在每次迭代中,粒子根据个体最优和全局最优调整速度和位置,最后返回全局最优解。
PSO-kelm用于时间序列预测
结合起来看,我们用PSO去优化KELM的核参数等,让它在时间序列预测上更出色。很多时候我们会使用自带的数据集,比如Python的pandas - datasets里就有不少时间序列相关的数据集。以某简单时间序列数据集为例,使用PSO-kelm的大致流程如下:
- 加载数据集,处理数据成适合模型输入的格式。
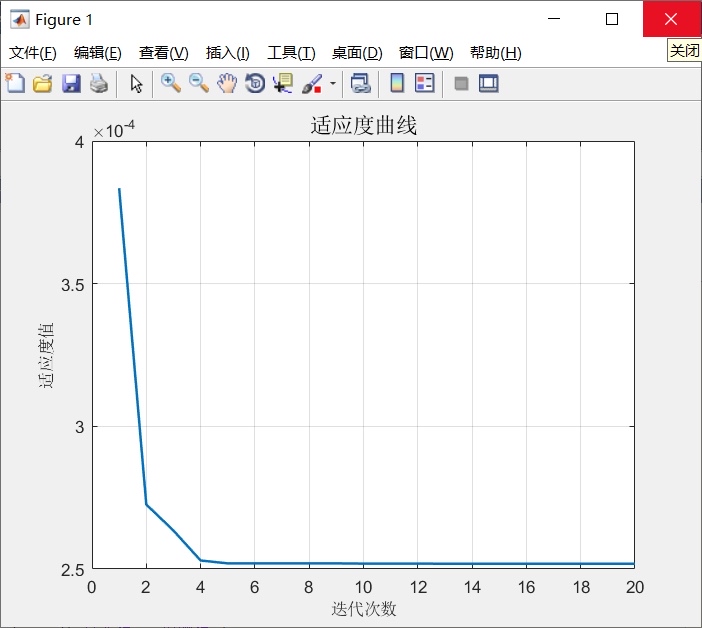
- 定义KELM模型和目标函数(比如预测误差作为目标函数,在PSO里要最小化这个误差)。
- 使用PSO优化KELM的参数。
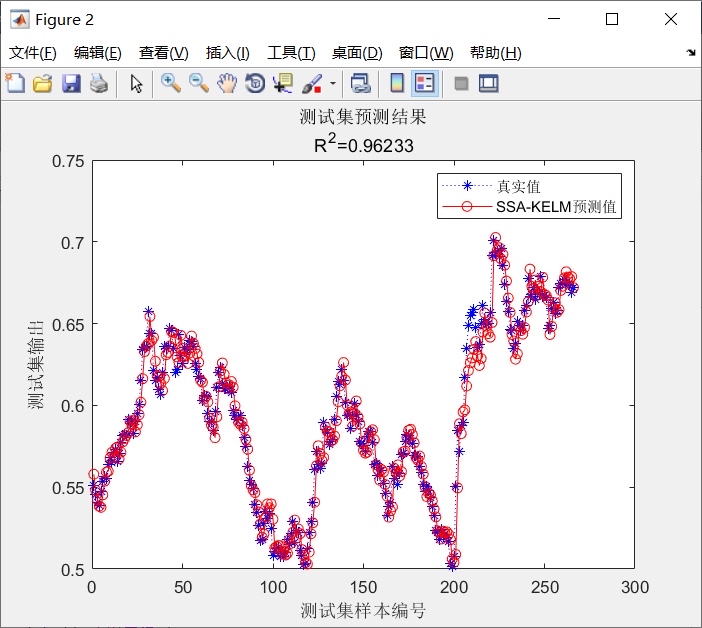
- 用优化好参数的KELM模型进行时间序列预测,并评估预测效果。
实际应用中,PSO-kelm在时间序列预测效果非常好,对于新手来说,上述代码注释详细,易于理解和上手。无论是预测金融时间序列的走势,还是工业设备运行参数的变化趋势等场景,PSO-kelm都可能是你的得力工具。希望大家都能在时间序列预测的实践中,好好探索PSO-kelm的潜力。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐


 5
5 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)