DeepRL-TensorFlow2:Python深度强化学习实践工具包
深度强化学习(Deep Reinforcement Learning, DRL)是将深度学习(Deep Learning, DL)与强化学习(Reinforcement Learning, RL)相结合的交叉领域。它利用深度神经网络的强大特征提取能力来处理高维数据,例如图像和语音信号,以解决传统强化学习方法难以应对的问题。强化学习的核心在于通过探索(Exploration)与利用(Exploita

简介:深度强化学习(DRL)融合了深度学习和强化学习,通过TensorFlow 2.0框架,本资源包使开发高效便捷。它提供了一系列用Python实现的DRL算法,特别是DDPG算法。资源包详细介绍了DRL基础、TensorFlow 2.0的特性、Python进化算法工具包、DDPG原理、Actor-Critic方法、经验回放缓冲区的使用,以及如何通过Python进行编程实践。包含代码、模拟器、日志和配置文件等,旨在帮助学习者深入理解并实践DRL。 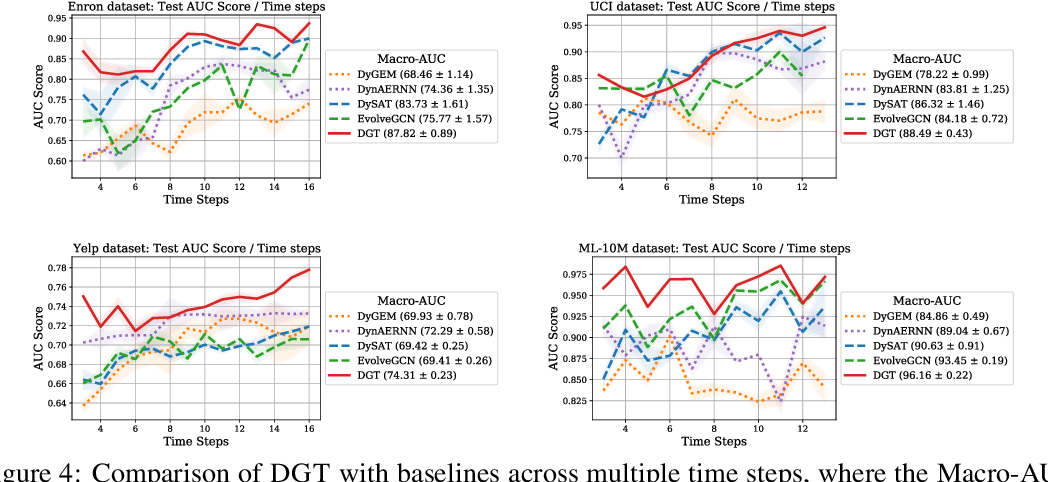
1. 深度强化学习基础和定义
深度强化学习(Deep Reinforcement Learning, DRL)是将深度学习(Deep Learning, DL)与强化学习(Reinforcement Learning, RL)相结合的交叉领域。它利用深度神经网络的强大特征提取能力来处理高维数据,例如图像和语音信号,以解决传统强化学习方法难以应对的问题。强化学习的核心在于通过探索(Exploration)与利用(Exploitation)来学习策略(Policy),即智能体如何根据当前状态采取行动,以最大化长期累积奖励。
在深度强化学习中,智能体通过与环境的交互,学习到的策略能够直接映射观察到的状态到行为。DRL模型通常包含两个关键组件:策略网络(Policy Network)和价值网络(Value Network)。策略网络直接输出动作,而价值网络评估给定状态下采取特定动作的预期回报。DRL的关键挑战在于如何平衡探索与利用,设计有效的奖励机制,以及确保学习过程的稳定性和收敛性。
DRL已经在多个领域证明了其有效性,例如游戏AI、机器人控制和推荐系统等。然而,它的复杂性和计算开销要求从业者有扎实的数学基础、编程能力和对问题的深入理解。后续章节将详细介绍如何利用TensorFlow等深度学习框架来实现DRL应用,进一步提升模型的性能和优化训练过程。
2. TensorFlow 2.0框架介绍与优势
TensorFlow是深度学习领域的一个重要框架,经过多年的迭代和优化,TensorFlow 2.0版本的发布,更进一步降低了机器学习和深度学习应用的门槛,同时提升了性能。本章将介绍TensorFlow 2.0的核心特性,其优势,并探索在深度强化学习中的应用。
2.1 TensorFlow 2.0的核心特性
TensorFlow 2.0的设计哲学是让深度学习模型的开发更加简单、直观,并且更加强大。为此,它引入了诸多新特性,其中张量流动、计算图以及Keras集成与高级API是TensorFlow 2.0的核心特性之一。
2.1.1 张量流动和计算图
在TensorFlow中,计算图是所有操作的图形表示,它定义了操作之间的依赖关系。张量流动是指数据在网络中的流动,每个节点都是一个操作,每个边表示操作间传递的数据(即张量)。这使得TensorFlow能够以异步和多设备的方式有效地运行计算。
import tensorflow as tf
# 创建一个常数张量
a = tf.constant([[1, 2], [3, 4]])
b = tf.constant([[1, 2], [3, 4]])
# 张量相加
c = tf.add(a, b)
# 计算图
with tf.Graph().as_default() as g:
# 在计算图中创建占位符
x = tf.placeholder(tf.float32, shape=[None, 4])
# 创建一个简单的矩阵乘法
matmul_result = tf.matmul(x, b)
# 创建会话并运行
with tf.compat.v1.Session(graph=g) as sess:
output = sess.run(matmul_result, feed_dict={x: [[1, 2, 3, 4], [5, 6, 7, 8]]})
print(output)
这段代码展示了如何定义一个简单的计算图,包括常数张量和张量的加法操作。然后,在会话中执行了这个图的矩阵乘法运算。
2.1.2 Keras集成与高级API
TensorFlow 2.0默认集成了Keras API,这是一个高级神经网络API,用户可以轻松构建和训练模型。Keras提供了快速实验的能力,而且由于它的模块化和易用性,也便于构建和测试新想法。
from tensorflow.keras import layers, models
# 定义一个简单的顺序模型
model = models.Sequential([
layers.Dense(64, activation='relu', input_shape=(32,)),
layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 使用模型
# model.fit(...)
上述代码段展示了如何使用Keras API快速定义一个分类模型,其中包含两个全连接层,并编译该模型以用于后续训练。
2.2 TensorFlow 2.0的优势分析
TensorFlow 2.0不仅继承了之前的优点,还在易用性、灵活性、性能优化和分布式计算方面有了显著提升。
2.2.1 易用性与灵活性的提升
TensorFlow 2.0提高了易用性和灵活性,使得开发者可以更容易地构建和调试深度学习模型。通过Eager Execution(即时执行),开发者可以直观地查看中间变量的状态,从而更方便地调试。
# 开启即时执行模式
tf.compat.v1.enable_eager_execution()
# 即时执行模式下,可以简单打印张量值
x = tf.constant([[2.0, 3.0], [4.0, 5.0]])
print(x)
开启即时执行模式后,代码将按顺序逐行执行,类似普通Python代码,调试更为直观。
2.2.2 性能优化与分布式计算
除了易用性之外,性能优化是TensorFlow 2.0的另一大亮点。TensorFlow提供了多种性能优化手段,比如自动微分、自动并行计算等。同时,其分布式计算能力使得在多个设备上运行大规模计算成为可能。
# 创建两个变量并进行分布式求和
with tf.distribute.MirroredStrategy().scope():
var1 = tf.Variable([[1.0, 2.0], [3.0, 4.0]])
var2 = tf.Variable([[1.0, 2.0], [3.0, 4.0]])
result = var1 + var2
print(result)
上述代码展示了分布式策略的简单使用,其中 MirroredStrategy 用于在多GPU上同步训练模型。
2.3 TensorFlow 2.0在深度强化学习中的应用
深度强化学习(DRL)是强化学习与深度学习相结合的领域,它允许智能体通过与环境的交互来学习策略。TensorFlow 2.0为DRL的模型搭建和训练提供了强大的支持。
2.3.1 模型搭建与训练流程
在搭建DRL模型时,TensorFlow 2.0可以利用Keras API来构建复杂的神经网络结构,并结合OpenAI Gym、DeepMind Lab等环境来搭建训练流程。
import gym
# 创建环境
env = gym.make('CartPole-v1')
# 使用Keras构建网络
model = models.Sequential([
layers.Dense(64, activation='relu', input_shape=(4,)),
layers.Dense(64, activation='relu'),
layers.Dense(2, activation='linear')
])
# 编译模型
model.compile(optimizer='adam', loss='mse')
# 训练模型的伪代码
# for _ in range(epochs):
# observation = env.reset()
# while not done:
# action = model.predict(observation[None, :])
# observation, reward, done, _ = env.step(action)
# # 更新模型
这里给出的是一个使用TensorFlow 2.0框架搭建DRL模型的简化示例,模型接受环境的观测作为输入,输出策略的动作值。
2.3.2 环境与交互的管理
管理训练环境和智能体的交互是DRL中的关键部分。在TensorFlow 2.0中,可以使用环境包装器(wrappers)来处理与环境的交互,并确保稳定高效地收集经验。
from tensorflow.keras import layers, models
# 环境包装器的伪代码
class MyWrapper(gym.Env):
def __init__(self, env):
self.env = env
def reset(self):
# 返回经过包装后的环境状态
return self.env.reset()
def step(self, action):
# 处理智能体的动作,并返回环境的结果
observation, reward, done, info = self.env.step(action)
return observation, reward, done, info
env = MyWrapper(gym.make('CartPole-v1'))
以上是一个环境包装器的示例代码,展示了如何使用自定义包装器来处理原始环境的输出。
通过上述章节的内容,我们可以看到TensorFlow 2.0框架在深度强化学习领域的强大支持和应用潜力。其易用性、灵活性、性能优化和分布式计算优势,使得开发复杂模型和高效训练变得触手可及。接下来的章节将探讨如何通过Python实现进化算法,并深入分析DDPG和Actor-Critic方法在深度强化学习中的应用。
3. Python实现进化算法
3.1 进化算法的基本原理
进化算法(Evolutionary Algorithms, EAs)是一种模拟自然选择和遗传学原理的优化算法。它们是解决优化和搜索问题的强大工具,特别适用于解决传统优化算法难以解决的复杂问题。进化算法的核心在于通过迭代过程,使问题的潜在解逐渐进化,最终找到最优解或近似最优解。
3.1.1 遗传算法与自然选择
遗传算法(Genetic Algorithms, GAs)是进化算法中最著名和应用最广泛的算法之一。它模仿生物的进化过程,通过模拟自然选择的过程来进化解。每个解被称为一个个体,每个个体由一组代表特定解特征的基因组成。在迭代过程中,算法根据个体的适应度来选择优良的基因,使其有机会遗传给下一代,并淘汰适应度较低的个体。这个过程模拟了自然界中适者生存的法则,通过这种方式,算法能够有效地搜索解空间,找到高质量的解。
在遗传算法中,主要的操作包括选择(Selection)、交叉(Crossover)和变异(Mutation):
- 选择操作用于选择适应度高的个体进行繁殖,常见的选择方法有轮盘赌选择(Roulette Wheel Selection)、锦标赛选择(Tournament Selection)等。
- 交叉操作是指两个个体交换它们的部分基因,从而产生新的个体。这模拟了生物的有性繁殖,可以产生新的特征组合。
- 变异操作则是在个体的基因中引入随机的改变,这有助于算法跳出局部最优解,增加种群的多样性。
3.1.2 适应度函数与选择机制
适应度函数是遗传算法中非常关键的组件,它用于评价个体的性能好坏。设计一个好的适应度函数是算法成功的关键因素之一。适应度函数需要根据具体问题设计,以反映解的优劣。
选择机制的目的是根据适应度函数来选择优良的个体参与繁殖。理想的选择机制能够平衡探索(Exploration)和利用(Exploitation),即在保持种群多样性的同时,确保性能较好的个体能够传承其基因。如果选择机制过于偏向于利用,可能导致算法快速收敛至局部最优解;如果偏向于探索,则可能导致算法收敛缓慢。
3.2 Python中的进化算法实践
在Python中实现进化算法,我们可以使用内置数据结构如列表、元组等来表示基因,利用Python的强大功能来完成选择、交叉和变异操作。下面我们将展示如何使用Python实现一个简单的遗传算法。
3.2.1 编码与种群初始化
在编码阶段,我们需要定义如何将问题的解表示为个体的基因。编码的方式取决于问题的特性,常见的方式有二进制编码、实数编码和排列编码等。
import numpy as np
# 假设我们要解决的是一个简单的优化问题,目标是最大化以下函数:
# f(x) = x^2, 其中x在-10到10之间
# 编码函数,将x映射为一个实数编码
def encode(x):
return x
# 解码函数,将编码转换回x
def decode(gene):
return gene
# 初始化种群
def initialize_population(pop_size, gene_range):
return np.array([encode(np.random.uniform(-10, 10)) for _ in range(pop_size)])
# 示例:初始化种群大小为100的种群
population = initialize_population(100, (-10, 10))
3.2.2 交叉、变异与选择操作
交叉操作用于创建新的后代。这里我们使用单点交叉作为例子,选择两个父代的基因片段,然后在某一点交换它们的片段,生成新的后代。
# 单点交叉
def crossover(parent1, parent2, crossover_rate=0.7):
if np.random.rand() < crossover_rate:
cross_point = np.random.randint(0, len(parent1))
child1 = np.concatenate((parent1[:cross_point], parent2[cross_point:]))
child2 = np.concatenate((parent2[:cross_point], parent1[cross_point:]))
return child1, child2
else:
return parent1, parent2
变异操作是引入随机性的重要手段,它可以防止算法过早收敛到局部最优解。这里我们使用随机变异作为例子,将基因中的某一部分随机地改变其值。
# 随机变异
def mutate(gene, mutation_rate=0.01, mutation_range=(-10, 10)):
if np.random.rand() < mutation_rate:
mutation_point = np.random.randint(0, len(gene))
gene[mutation_point] = np.random.uniform(*mutation_range)
return gene
选择操作用于从当前种群中选择优良的个体参与交叉和变异。这里我们使用轮盘赌选择作为例子,选择的个体概率与其适应度成正比。
# 轮盘赌选择
def select(population, fitness, num_parents):
idx = np.random.choice(np.arange(len(population)), num_parents, p=fitness/fitness.sum())
return population[idx]
接下来,我们将这些操作组合起来,构成遗传算法的一个完整迭代过程:
# 遗传算法迭代
def genetic_algorithm(population, fitness, num_parents, num_generations):
for generation in range(num_generations):
parents = select(population, fitness, num_parents)
children = []
for _ in range(len(parents)//2):
parent1, parent2 = parents[_*2], parents[_*2+1]
child1, child2 = crossover(parent1, parent2)
children.append(mutate(child1))
children.append(mutate(child2))
population = np.concatenate((parents, np.array(children)))
# 可以在此处添加适应度更新逻辑
# fitness = update_fitness(population)
return population[np.argmax(fitness)]
# 运行遗传算法并打印结果
best_individual = genetic_algorithm(population, np.abs, 10, 100)
print(f"Best Individual: {decode(best_individual)} with Fitness: {np.abs(best_individual)**2}")
通过上述过程,我们可以使用Python来模拟一个简单的进化算法,并在问题空间中进行搜索,以期找到最优解。需要注意的是,为了确保算法的效率和效果,适应度函数、编码方式和算法参数(如交叉率和变异率)需要根据具体问题仔细选择和调整。
4. DDPG算法的原理和应用
深度确定性策略梯度(DDPG)算法是深度强化学习领域的一个重要进展。DDPG结合了确定性策略和策略梯度方法,以及与DQN相似的回放记忆和目标网络。它的出现,特别是在连续动作空间的学习任务中,显示了显著的效果。DDPG通过引入Actor-Critic框架来处理连续动作空间问题,其中Actor代表策略网络,Critic代表价值网络。Actor负责输出确定性策略,而Critic则对这个策略进行评估。
4.1 DDPG算法的核心概念
4.1.1 深度确定性策略梯度的介绍
DDPG算法的核心是一个确定性策略。在强化学习中,传统策略梯度方法(如REINFORCE算法)通常采用概率性策略,它通过输出一个动作的概率分布来选择动作。相比之下,DDPG的策略是确定性的,即对于给定的状态,策略直接输出一个最优动作。这种确定性策略在连续动作空间中尤其有用,因为概率性策略可能需要在连续的动作中进行采样,导致效率低下和方差问题。
DDPG算法在结构上借鉴了DQN的机制,使用经验回放和目标网络来稳定训练过程。在DDPG中,一个称为Actor的网络负责策略的确定性映射,而另一个称为Critic的网络负责评价这个策略的价值。Critic网络利用贝尔曼方程的性质,通过学习价值函数来评估给定状态和动作的期望回报。
4.1.2 智能体与环境的交互原理
在DDPG中,智能体(Agent)通过Actor网络与环境进行交互,它接收环境的当前状态,并根据其策略输出一个动作。然后,这个动作被应用到环境中,产生新的状态和回报(reward)。智能体的目标是通过最大化累积回报来学习一个最优策略。
为了实现这一点,DDPG算法使用了经验回放机制。智能体会将状态、动作、奖励和新状态的转换存储在回放缓冲区中,并使用这些经验进行离线学习。此外,DDPG引入了一个目标网络来减少训练过程中的方差并稳定学习过程。在训练过程中,Critic网络的目标是学习当前策略的最优价值函数,而Actor网络则更新以直接最大化Critic的输出。
4.2 DDPG算法的应用案例
4.2.1 策略探索与利用的平衡
在强化学习中,策略的探索(Exploration)和利用(Exploitation)之间的平衡是一个核心问题。DDPG算法通过Actor网络来解决这一问题,因为Actor网络为每个状态输出一个确定性的动作,减少了探索空间。而Critic网络评估这个动作,帮助智能体调整策略,以期达到更好的回报。
DDPG算法在训练初期采取随机性策略来探索环境,并随着训练的进行逐渐收敛到一个确定性的策略。这样不仅保证了在探索阶段的多样性和灵活性,也确保了在利用阶段的稳定性和高效性。
4.2.2 实际问题中的调参与部署
DDPG算法已在多个实际问题中得到了应用,包括机器人控制、自动驾驶车辆的路径规划、游戏等领域。在这些应用中,DDPG的调参和部署变得至关重要。
调参过程中,需要仔细选择Actor和Critic网络的结构、优化器的类型和超参数,例如学习率、折扣因子、批量大小、经验回放大小等。此外,由于DDPG算法采用的深度神经网络,对于大规模的状态和动作空间,数据的归一化、正则化等技巧也是必不可少的。
在部署阶段,DDPG训练出的模型需要在实际环境中进行验证。这通常涉及到将训练好的Actor网络部署到真实系统中,并且监控模型的实时表现,确保模型在实际环境中的稳定性和可靠性。为了实现这一点,可能需要考虑模型的压缩、加速以及在硬件上的优化。
DDPG算法的一个关键优势是其能够处理高维动作空间问题,这使得它在多个领域中具有广泛的应用潜力。理解DDPG算法的工作原理以及如何在实际问题中有效部署,对于深入研究和应用深度强化学习具有重要意义。
5. Actor-Critic方法的解释和应用
Actor-Critic 方法是深度强化学习(DRL)中的一种重要算法架构,它将智能体的决策过程拆分为两个部分:Actor 和 Critic。Actor 负责根据当前策略生成动作,而 Critic 评估动作的效果,为 Actor 提供学习信号。这种方法的引入,有效结合了策略梯度方法和价值函数方法的优点,提高了学习过程的稳定性和效率。
5.1 Actor-Critic方法概述
5.1.1 代理与评价器的分离机制
在 Actor-Critic 方法中,代理(Actor)和评价器(Critic)协同工作,形成了一个闭合的反馈循环。Actor 的目标是选择最大化预期回报的动作,而 Critic 则评估这些动作的即时价值,并通过与预期回报的差距来指导 Actor 进行策略更新。这种分离机制允许 Actor 专注于探索动作空间,而 Critic 负责提供准确的价值评估。
5.1.2 策略梯度与价值函数的联合优化
Actor-Critic 方法的一个关键优势在于它能够利用策略梯度方法直接优化策略,同时利用价值函数评估动作。在实践中,通常采用一种称为 Advantage Function 的方法来平衡这两种学习信号,从而在探索和利用之间取得平衡。
5.2 Actor-Critic方法在实际中的应用
5.2.1 算法的稳定性与效率提升
Actor-Critic 方法之所以在实际应用中受到青睐,是因为它在稳定性方面的表现要优于单独使用策略梯度或价值函数方法。此外,由于 Critic 可以重用之前的经验来计算价值函数,从而减少了样本的方差,这在提高效率方面表现显著。
5.2.2 复杂环境下的案例分析
在复杂或连续动作空间的环境中,Actor-Critic 方法尤其有用。例如,在自动驾驶模拟环境中,Actor-Critic 能够持续评估车辆的驾驶策略,并根据路况变化进行实时调整。在这些场景中,Actor-Critic 方法能够更好地处理高维状态空间和动作空间的挑战。
在实际案例中,我们可以分析 Actor-Critic 方法如何在一个具体的应用环境,如游戏AI中,通过优势函数的计算来改进决策。可以通过代码示例和实验数据来展示如何实现 Actor-Critic 结构,并使用经验回放来进一步提升性能。
# 下面是一个使用 PyTorch 实现的简化版 Actor-Critic 算法的代码片段
import torch
import torch.nn as nn
import torch.optim as optim
class Actor(nn.Module):
def __init__(self, state_dim, action_dim):
super(Actor, self).__init__()
self.fc = nn.Sequential(
nn.Linear(state_dim, 128),
nn.ReLU(),
nn.Linear(128, action_dim),
nn.Tanh()
)
def forward(self, x):
return self.fc(x)
class Critic(nn.Module):
def __init__(self, state_dim):
super(Critic, self).__init__()
self.fc = nn.Sequential(
nn.Linear(state_dim, 128),
nn.ReLU(),
nn.Linear(128, 1)
)
def forward(self, x):
return self.fc(x)
# 策略梯度优化器
policy_optimizer = optim.Adam(Actor.parameters(), lr=1e-4)
# 价值函数优化器
value_optimizer = optim.Adam(Critic.parameters(), lr=1e-3)
# 仿真中执行策略并收集数据的伪代码
# for each episode:
# state = env.reset()
# done = False
# while not done:
# action = actor(state)
# next_state, reward, done = env.step(action)
# buffer.store(state, action, reward, next_state, done)
# state = next_state
# # 更新策略和价值函数
# loss = update_actor_critic(buffer, actor, critic, policy_optimizer, value_optimizer)
在上述代码中,我们首先定义了两个神经网络模型,分别对应 Actor 和 Critic。接着,我们初始化了两个优化器,并提供了在仿真环境中执行策略并收集数据的伪代码。当然,具体代码实现会根据算法细节和所使用的库而有所差异。通过这样的代码实践,可以对 Actor-Critic 方法的应用有更直观的理解。
在真实的案例中,我们还可以通过表格展示在不同环境下的性能对比,或者使用图表呈现训练过程中的学习曲线,这些都有助于展示 Actor-Critic 方法的实际效果。
graph LR
A[开始] --> B[初始化 Actor 和 Critic]
B --> C[环境交互]
C --> D[存储经验]
D --> E[样本回放]
E --> F[计算优势函数]
F --> G[Actor 和 Critic 更新]
G --> H[评估性能]
H --> I{是否收敛或达到最大迭代次数?}
I -- 是 --> J[结束]
I -- 否 --> C
以上是一个 Actor-Critic 训练流程的 Mermaid 图表,它展示了该方法的迭代更新过程,从初始化模型到最终结束训练。
在下一章,我们将深入探讨经验回放缓冲区在深度强化学习中的重要作用。
简介:深度强化学习(DRL)融合了深度学习和强化学习,通过TensorFlow 2.0框架,本资源包使开发高效便捷。它提供了一系列用Python实现的DRL算法,特别是DDPG算法。资源包详细介绍了DRL基础、TensorFlow 2.0的特性、Python进化算法工具包、DDPG原理、Actor-Critic方法、经验回放缓冲区的使用,以及如何通过Python进行编程实践。包含代码、模拟器、日志和配置文件等,旨在帮助学习者深入理解并实践DRL。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐

 30
30 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)