一文详解Hibernate
Configration接口。
·
一、基础入门
- 官网:https://hibernate.net.cn/
- Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,它将POJO与数据库表建立映射关系,是一个全自动的orm框架,hibernate可以自动生成SQL语句,自动执行,使得Java程序员可以随心所欲的使用对象编程思维来操纵数据库。 Hibernate可以应用在任何使用JDBC的场合,既可以在Java的客户端程序使用,也可以在Servlet/JSP的Web应用中使用,最具革命意义的是,Hibernate可以在应用EJB的JaveEE架构中取代CMP,完成数据持久化的重任
二、Hibernate基本配置
- 核心配置文件——hibernate.cfg.xml(主要描述Hibernate的相关配置)
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<!-- 下面是三个必须要有的配置 -->
<!-- 配置连接MySQL数据库的基本参数 -->
<property name="hibernate.connection.driver_class">com.mysql.cj.jdbc.Driver</property>
<property name="hibernate.connection.url">jdbc:mysql:///hibernate_demo01</property>
<property name="hibernate.connection.username">root</property>
<property name="hibernate.connection.password">root</property>
<!-- 配置Hibernate的方言 -->
<property name="hibernate.dialect">org.hibernate.dialect.MySQLDialect</property>
<!-- 可选的配置 -->
<!-- 打印sql语句 -->
<property name="hibernate.show_sql">true</property>
<!-- 格式化sql语句 -->
<property name="hibernate.format_sql">true</property>
<!-- 自动处理表 create、update、validate(验证配置的字段和数据库字段是否匹配) -->
<property name="hibernate.hbm2ddl.auto">update</property>
<!-- 验证实体 none、true-->
<property name="javax.persistence.validation.mode">none</property>
<!-- 加载映射文件-->
<mapping resource="com/zzx/entity/hbXml/Customer.hbm.xml"/>
<mapping resource="com/zzx/entity/hbXml/User.hbm.xml"/>
</session-factory>
</hibernate-configuration>
- 映射配置文件——类名.hbm.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="com.zzx.entity"> <!-- 如果此处配置了包路径,下面class的name可以只写类名字(Customer)-->
<!-- 建立类与表的映射 -->
<class name="com.zzx.entity.Customer" table="cst_customer"> <!--table是数据库表名字 -->
<!-- 建立类中的属性与表中的主键相对应 -->
<id name="id" column="cust_id"> <!-- name实体的主键名字 column 数据库表主键名 -->
<generator class="native" /><!-- 主键的生成策略,native:本地策略-->
</id>
<!-- 建立类中的普通属性和表中的字段相对应 -->
<property name="cust_name" column="cust_name" length="32"type="int" /> <!--type可配置三种类型-->
<property name="cust_source" column="cust_source" type="string"/>
<property name="cust_industry" column="cust_industry" />
<property name="cust_level" column="cust_level" />
<property name="cust_phone" column="cust_phone" />
<property name="cust_mobile" column="cust_mobile" />
<property name="cust_sex" column="cust_sex" />
</class>
</hibernate-mapping>
- hrbm中的字段可以配置三种类型
- Java中的数据类型;
- Hibernate中的数据类型;
- SQL的数据类型。

三、Hibernate核心API
-
Configration接口
- 启动hibernate,加载配置文件(configure方法,默认读取的hibernate.cfg.xml文件)
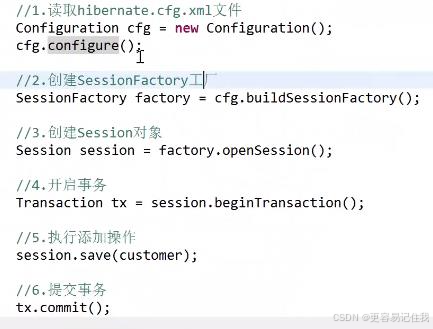
- 启动hibernate,加载配置文件(configure方法,默认读取的hibernate.cfg.xml文件)
-
SessionFactory
- 加载数据库连接、扩展参数和映射信息,通过这些映射信息创建可操作的session对象
- 通常只需要一个SesseionFactory,生产Session对象
-
Session
- 用于操作数据对象,基本的增删改查API
- 线程不安全,一个线程创建一个session操作各自数据
-
Transaction
- 事务处理
-
Query
- hql执行器
-
Criteria
- 执行基于对象的查询(QBC查询)
四、Hibernate核心注解
- 实体类注解
- 类注解
- @DynamicInsert:默认true,新增数据的时候,只新增不为null的字段
- @DynamicUpdate:默认true,更新数据的时候,只更新不为null的字段
- 字段注解
- @GenericGenerator(name = “identity”, strategy = "identity):主键生成策略(默认十四种策略)
- name:生成器的名称;strategy:具体生成器的类名;parameters:
- strategy指定的具体生成器所用到的参数
- 数据库控制:
- identity:mysql的自增
- sequence:orcale数据库的序列生成
- native:本地策略,hibernate自动根据不同数据选择不同策略
- hibernate维护:
- uuid:生成32位的16进制字符串
- increment:自增,每次插入数据,会先从数据库查询最大的id值
- 开发自己维护:
- assigend:用户必须自己手动赋值id
- @GenericGenerator(name = “identity”, strategy = "identity):主键生成策略(默认十四种策略)
- @ColumnDefault(0):字段默认值
- 类注解
五、Hibernate基本查询
- 基本对象查询
- get(立即加载)和load(延迟加载)查询
- HQL语句查询
- 全表查询: session.createQuery(“FROM user”);直接 from表即可
- 条件查询:同全表查询
- sql语句直接写完整语句
- sql使用?占位符
- where id = ?
- query.setParamter(0, “id的值”)
- sql使用:别名占位
- where id = :id
- query.setParamter(id, “id的值”)
- 分页查询
- query.setFirstResult();//设置起始行,从第几行开始,默认从0开始,通常 每页条数*(查询的页数- 1)
- query.setMaxResult();查询的条数
- 获取唯一值
- query.uniqurResult()
- 联合询:select c,name, o,phone from Custerm c left join c.orders o; //orders是Custerm的子表字段
- QBC查询(criteria):面向对象查询
- 全表查询: Criteria criteria = session.createCriteria(User.class)
- 条件:criteria.add(Restrictions.eq(“name”,“王五”))//设置查询参数 name是字段名
- 分页查询和HQL类似
- 排序:criteria.addOrder(Order.asc(“字段”))
- 聚合:
- criteria.setProjection(Projections.count(“字段名”))
- Projections,max Projections.sum 等等
- 查询特定字段
- ProjectionList list = new ProjectionList ();
- list.add(Property.forName(“字段名1”))
- list.add(Property.forName(“字段名2”))
- criteria.setProjection(list);
- 本地SQL查询:执行jdbc原始sql
- session.createSQLQuery(“sql语句”)
六、Hibernate优化策略
- 对象三种状态
- 临时状态:创建的新对象
- 通过session删除的对象会转为临时状态
- 游离状态:脱离session管理的对象
- seesion操作evict、clear和close方法,会使持久化对象转化为游离状态
- 持久状态:被session管理持久化的对象
- 通过session加载数据库获取的对象可进入持久状态
- 通过session保存或更新的对象位持久状态
- 临时状态:创建的新对象
- 一级缓存和快照机制
- 一级缓存:session对象缓存,session内部的一个Map集合
- 同一个session查询对象的时候,会先从Map集合查找对象,未找到才会查询数据库
- 快照机制:session内部的一个Map集合,用于备份数据库数据
- 用于比较一级缓存,实现持久化对象的更新
- 当获取一个持久化对象的时候,会在一级缓存和快照中保存到Map集合中
- 当持久态对象发生变化的时候,会修改一级缓存中的对象
- 当提交事务
- 执行了flush方法:会检查一级缓存和快照中的对象,若发现对象不一致,则会生成更新语句
- flush:从内存到数据库同步,发送更新语句(还未提交事务)
- 执行sql语句并提交事务
- 更新快照
- 执行了flush方法:会检查一级缓存和快照中的对象,若发现对象不一致,则会生成更新语句
- 一级缓存的管理
- clear:清除session缓存对象
- evict(object):清除指定的缓存对象
- 一级缓存:session对象缓存,session内部的一个Map集合
- 延迟加载:只有当使用到对象的时候,才会去执行查询(Lazy:false)
- load:延迟
- get:立即
- 关联级别延迟加载
- 默认子表(主表)的数据在使用的时候才会加载
- 抓取策略:优化SQL
- fetch:select;默认正常执行sql
- fetch:join;查询主表和子表的数据时候,默认执行两条sql,此方式会关联查询(无法实行懒加载)
- fetch:subselect;主表循环获取子表集合的时候,会将多个子表的查询使用联合查询
- 二级缓存:SessionFactory缓存,session之间可以公用的缓存信息
- 一级缓存默认开启且无法关闭
- 二级缓存默认关闭,并且依赖第三方组件 官网推荐并整合了ehcahe
七、其他细节
- 事务管理
- 四大特性
- 原子性:同成功同失败
- 一致性:保证数据操作后的数据一致
- 隔离性:事务之间互不干扰
- 持久性:事务最终会将数据持久化
- 事务并发问题
- 脏读:读到未提交的数据
- 幻读:读到其他事务提交的新数据
- 不可重复读:读到其他数据更新的数据
- 隔离级别
- 读已提交:防止脏读
- 读未提交:防止幻读
- 可重复读:防止脏读和幻读
- 串行化:事务按照顺序执行
- 四大特性

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐

 25
25 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)