构建网上书城系统:Struts、Hibernate与MySQL集成实践
网上书城系统旨在通过互联网技术,为用户提供一个便捷的在线购书平台。系统不仅需要展示丰富的图书资源,还需要提供搜索、购书、结账、用户管理和订单跟踪等基本功能。目标是打造一个用户体验优秀、功能齐全、稳定可靠的电子交易平台。Struts2框架提供了大量的表单标签,用于简化JSP页面中的表单元素的创建和数据绑定,例如:<s:select>等。这些标签不仅增强了页面的表现力,还能够将数据与后端的Action

简介:网上书城系统是一种在线图书销售平台,该系统通过整合Struts、Hibernate和MySQL这三种Java技术组件,实现了高效、稳定且用户友好的服务。Struts作为Web应用框架,控制应用程序流程并处理用户请求。Hibernate作为ORM框架,简化数据库交互,实现Java对象与数据库表的映射。MySQL负责数据存储,保证数据安全和快速访问。系统功能如用户注册登录、图书浏览搜索、购物车管理等模块都依赖这三个技术组件的紧密协作。开发者通过这种技术组合,可以设计和实现电子商务系统,提供良好的在线购物体验。 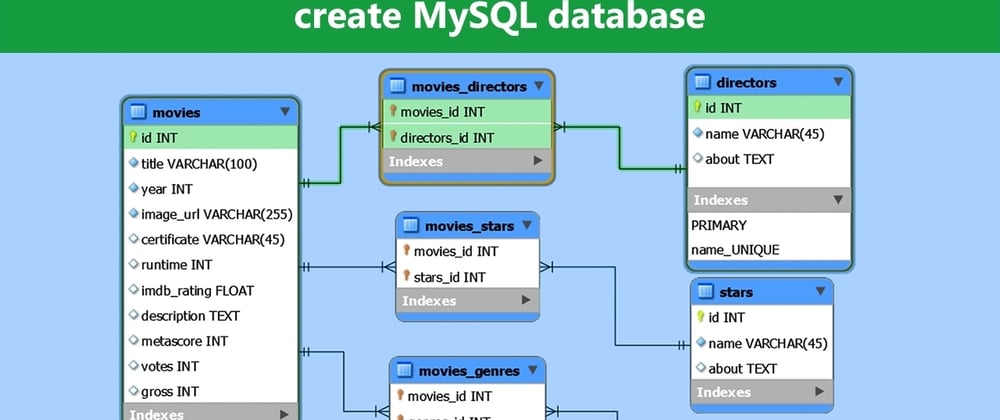
1. 网上书城系统概述
1.1 系统定位与目标
网上书城系统旨在通过互联网技术,为用户提供一个便捷的在线购书平台。系统不仅需要展示丰富的图书资源,还需要提供搜索、购书、结账、用户管理和订单跟踪等基本功能。目标是打造一个用户体验优秀、功能齐全、稳定可靠的电子交易平台。
1.2 用户需求分析
系统的主要用户群体为喜欢阅读和购买图书的人群。用户需求主要包括:
- 快速检索和浏览图书。
- 详细查看图书信息和用户评价。
- 安全地进行在线支付和订单管理。
- 方便的账户管理,包括个人信息、订单历史和购物车维护。
1.3 技术选型考量
在技术选型上,需要考虑系统的可持续发展和维护成本。因此,我们选择了Java作为主要开发语言,应用了Struts框架以实现MVC模式,利用Hibernate框架进行持久化操作,以及MySQL数据库存储数据。这些技术栈的成熟稳定性和良好的社区支持是本项目成功的关键因素。
// 示例代码:展示一个简单的用户登录逻辑
public class LoginAction {
private String username;
private String password;
public String execute() {
// 这里省略了与数据库交互的验证逻辑
if (isAuthenticated(username, password)) {
return SUCCESS;
} else {
return INPUT;
}
}
// 其他辅助方法和属性省略...
}
在后续章节中,我们将深入探讨如何利用Struts和Hibernate框架以及MySQL数据库来实现网上书城系统的各个功能模块,并通过具体代码来进一步展示如何优化和整合这些技术,以达到更好的系统性能。
2. Struts框架应用
2.1 Struts框架基础
2.1.1 Struts框架的MVC设计模式
Struts框架是基于MVC(Model-View-Controller)设计模式的应用程序框架,其中模型(Model)代表应用的数据结构,视图(View)代表数据的表现形式,而控制器(Controller)则负责接收用户的输入,并将其转换为模型的更新。
MVC设计模式将应用的不同功能分离成独立的部分,这样可以降低各部分之间的耦合度,简化系统的维护工作,并且可以对系统的不同部分进行单独的修改和扩展。
graph LR
A[用户请求] --> B[控制器]
B --> C[模型]
C --> D[视图]
D --> E[响应]
上图是一个简化的MVC处理流程,具体到Struts框架中,控制器是由ActionServlet实现,模型通常由Action类、JavaBean等实现,而视图则通过JSP技术实现。
2.1.2 Struts2的核心组件与工作流程
Struts2的组件主要包括Action、Interceptor、Result、ValueStack等。Action相当于MVC中的控制器部分,负责处理业务逻辑。Interceptor是拦截器,可以对请求进行预处理或后处理。Result定义了动作执行后如何展示结果视图。ValueStack是值栈,用于存储在Action和视图之间传递的数据。
Struts2的工作流程可概括如下:
- 用户发送请求到Web服务器。
- Web服务器将请求转发给Struts2的FilterDispatcher(Struts1中的ActionServlet)。
- FilterDispatcher根据请求找到对应的Action映射。
- 如果存在拦截器链,执行拦截器中的方法。
- 执行Action类的execute方法或其他业务逻辑方法。
- 根据返回的结果字符串(result name),配置文件中定义的Result类型将处理结果转发给相应的视图组件。
- 视图组件生成响应数据,反馈给用户。
2.2 Struts表单处理与验证
2.2.1 表单标签的使用与自定义
Struts2框架提供了大量的表单标签,用于简化JSP页面中的表单元素的创建和数据绑定,例如: <s:textfield> , <s:select> , <s:checkbox> 等。这些标签不仅增强了页面的表现力,还能够将数据与后端的Action类进行绑定。
自定义标签可以使开发者根据自己的需求创建更加专业的用户界面。在Struts2中,创建自定义标签通常需要实现 com.opensymphony.xwork2.ui.Tag 接口,并在 WEB-INF/classes 目录下创建相应的标签库描述文件(.tld文件)。
2.2.2 校验器的配置与开发
在Web应用中,表单校验是保证数据安全性和有效性的重要环节。Struts2通过校验器(validator)来实现对用户输入数据的校验,校验器可以配置在XML文件中,也可以通过实现 ValidationInterceptor 接口来自定义校验逻辑。
为了实现自定义校验器,开发者需要创建实现 com.opensymphony.xwork2.validator.Validator 接口的类,并在配置文件中进行声明和配置。校验器在拦截器栈中被调用,如果校验失败,会将错误信息返回给用户。
2.3 Struts与业务逻辑的整合
2.3.1 Action类的设计原则
Action类是Struts2框架的核心部分,它负责接收用户的请求并处理业务逻辑。Action类的设计应遵循一些原则,比如单一职责原则、开闭原则等。单个Action类应该只处理一种类型的业务逻辑,保持类的职责单一。同时,当业务逻辑发生变化时,应该扩展Action类而不是修改它,遵循开闭原则。
此外,Action类应该是一个POJO(Plain Old Java Object),不应该依赖任何框架的API,这样可以保持代码的可测试性和可维护性。
2.3.2 Action与业务组件的通信机制
Action类与业务组件之间的通信是通过ActionContext和ValueStack实现的。ActionContext是Action执行的上下文环境,存储了与Action相关的数据和业务组件等。ValueStack则是一个值栈,可以实现数据在Action和视图之间的传递。
当Action接收到一个请求时,它首先会将处理结果存放到ValueStack中,然后选择相应的结果视图进行展示。如果Action需要调用业务组件处理业务逻辑,可以将业务组件的实例放入ValueStack中,然后在Action中调用这些业务组件的方法。
代码块示例如下:
public class MyAction extends ActionSupport {
private MyService myService; // 业务组件实例
public String execute() {
myService.doBusiness(); // 调用业务组件处理业务逻辑
return SUCCESS; // 返回结果
}
// setter方法,框架通过setter注入业务组件实例
public void setMyService(MyService myService) {
this.myService = myService;
}
}
在上述代码中,MyAction类通过setter方法注入了MyService业务组件实例,然后在execute方法中调用了业务组件的doBusiness方法进行业务逻辑的处理。
3. Hibernate对象关系映射
3.1 Hibernate框架概述
3.1.1 ORM的概念及其在Hibernate中的实现
对象关系映射(ORM)是一种程序设计技术,用于实现面向对象语言中不同类型系统的数据之间的转换。ORM 把数据库中的数据映射到程序语言中定义的对象,简化了数据库编程复杂性,提高了开发效率。
Hibernate 作为一个持久层框架,它封装了复杂的SQL操作,允许开发者通过Java的高级API来操作数据库,实现了ORM的概念。Hibernate通过映射元数据来了解对象与数据库表的对应关系,并提供了数据查询和访问的方法。
在Hibernate中实现ORM,需要遵循以下步骤:
- 创建实体类:这些类对应于数据库中的表。
- 编写映射文件或使用注解:确定实体类与数据库表之间的对应关系。
- 利用Hibernate API执行CRUD操作:Hibernate提供了Session接口来执行基本的数据操作。
3.1.2 Hibernate的体系结构与组件
Hibernate的体系结构由多个层次组成,每个层次都包含了一组组件来完成特定任务,如下:
- Core层 :这是Hibernate的最底层,提供了对数据库连接的管理和事务处理的能力。核心接口包括
Session、SessionFactory和Configuration等。 - Data Access层 :这一层基于Core层之上,提供了CRUD操作的高级API,例如
Criteria、Query和Transaction接口。 -
Object Transaction Management层 :负责对象与关系数据库之间的映射(即对象持久化)。
-
Query层 :在数据访问层之上,提供了一种更为通用查询数据的方式,可以使用HQL(Hibernate Query Language)进行查询。
-
Caching层 :负责管理数据的缓存,减少数据库访问的次数,提高应用程序的性能。
3.2 Hibernate配置与会话管理
3.2.1 配置文件的编写与解析
Hibernate的配置文件(通常是 hibernate.cfg.xml ),包括了Hibernate初始化所需的所有信息,比如数据库连接信息、映射文件位置以及一些配置属性等。
配置文件的基本结构包括:
hibernate.connection.*属性,配置数据库连接信息。hibernate.dialect属性,设置特定数据库方言,用于优化生成的SQL。hibernate.hbm2ddl.auto属性,用于控制数据库模式的自动更新。<mapping>标签,指定映射文件的位置。
配置文件的一个基础例子如下:
<hibernate-configuration>
<session-factory>
<!-- Database connection settings -->
<property name="connection.driver_class">com.mysql.cj.jdbc.Driver</property>
<property name="connection.url">jdbc:mysql://localhost:3306/mydatabase</property>
<property name="connection.username">myusername</property>
<property name="connection.password">mypassword</property>
<!-- SQL dialect -->
<property name="dialect">org.hibernate.dialect.MySQLDialect</property>
<!-- Echo all executed SQL to stdout -->
<property name="show_sql">true</property>
<!-- Drop and re-create the database schema on startup -->
<property name="hbm2ddl.auto">create</property>
<!-- Mapping files -->
<mapping class="com.example.domain.User"/>
<mapping class="com.example.domain.Book"/>
</session-factory>
</hibernate-configuration>
3.2.2 Session接口的生命周期与管理
Session接口是Hibernate操作数据库的最重要接口之一。它是一个线程级别的轻量级会话,封装了JDBC连接,并提供了一系列方法来执行持久化操作。
Session的生命周期包括:
- 创建一个Session实例。
- 执行持久化操作,如保存、更新或删除实体。
- 关闭Session实例,释放底层的JDBC连接。
一个简单的Session管理示例代码如下:
Session session = null;
try {
session = sessionFactory.openSession(); // 创建Session
session.beginTransaction(); // 开始事务
User user = new User("newuser", "password");
session.save(user); // 执行保存操作
session.getTransaction().commit(); // 提交事务
} catch (Exception e) {
if (session.getTransaction() != null) {
session.getTransaction().rollback(); // 回滚事务
}
throw e;
} finally {
if (session != null) {
session.close(); // 关闭Session
}
}
3.3 Hibernate映射与数据持久化
3.3.1 实体映射技术与注解的使用
实体映射技术是将Java对象映射到数据库表的过程。在Hibernate中,可以通过XML映射文件或者注解来实现这一映射。注解方式在现代Java开发中更为流行,因为它减少了映射文件的数量,使得代码更加简洁。
使用注解的基本示例:
import javax.persistence.*;
@Entity
@Table(name="users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "username", unique = true, nullable = false)
private String username;
@Column(name = "password")
private String password;
// Getters and setters...
}
在上述代码中, @Entity 注解表明该类是一个实体类, @Table 注解指定了对应的数据库表, @Id 和 @GeneratedValue 注解定义了主键以及主键生成策略, @Column 注解用于映射字段到表的列。
3.3.2 CRUD操作的实现与优化
CRUD操作(创建、读取、更新、删除)是数据持久化的基本操作。Hibernate对这些操作提供了简洁的API,同时,通过一些优化策略可以提高操作效率。
CRUD操作实现示例:
Session session = sessionFactory.openSession();
try {
// Create
User user = new User("testUser", "testPassword");
session.save(user);
// Read
User readUser = (User) session.get(User.class, user.getId());
// Update
readUser.setPassword("newPassword");
session.update(readUser);
// Delete
session.delete(readUser);
session.getTransaction().commit();
} catch (Exception e) {
if (session.getTransaction() != null) {
session.getTransaction().rollback();
}
throw e;
} finally {
session.close();
}
CRUD操作优化:
- 使用二级缓存 :二级缓存可以由不同的应用实例共享,可以显著减少数据库访问次数。
- 优化查询语句 :使用HQL或Criteria查询,避免使用原生SQL。
- 批量操作 :对于批量操作,如删除和更新,使用Hibernate提供的批量操作API。
- 延迟加载 :适当使用延迟加载,减少不必要的数据加载。
CRUD操作的优化策略逻辑分析:
- 使用二级缓存 :Hibernate提供了两种级别的缓存,一级缓存是Session级别的,而二级缓存是应用级别的。二级缓存可以配置为分布式缓存,被多个应用服务器共享,大幅度减少了数据库的访问压力。
- 优化查询语句 :原生SQL语句可能会导致Hibernate在底层执行多条SQL语句,增加数据库的负载。使用HQL和Criteria API可以得到更加优化的执行计划,并且HQL支持语法更加接近Java,易于理解和维护。
- 批量操作 :批量操作是减少数据库交互次数的有效方法。比如,在数据库中删除大量的记录时,直接使用原生的SQL语句可能会导致多个独立的删除操作,而使用Hibernate的批量删除方法
session.createQuery("delete from User")可以将它们合并为单个操作。 - 延迟加载 :延迟加载可以延迟对象属性的加载,直到真正需要时。在Hibernate中可以通过配置实体关系的懒加载属性来实现。但是需要注意的是,错误的使用延迟加载可能会导致性能问题,比如N+1查询问题。合理的策略是,在确定不需要立即访问某些关联对象时使用延迟加载。
通过这些策略,可以有效地提高Hibernate的CRUD操作的性能,使系统更加稳定和高效。
4. MySQL数据库使用
4.1 MySQL数据库基础
4.1.1 数据库设计原则与范式
数据库设计是构建任何数据密集型应用的基石。良好的设计可确保数据的一致性、完整性和高效访问。在进行数据库设计时,需遵循一系列原则和规范,其中最重要的是数据库范式(Normal Forms)。
范式是数据表结构设计的一系列规则,用来减少数据冗余和提高数据完整性。常见的数据库范式有第一范式(1NF)、第二范式(2NF)、第三范式(3NF)和BCNF(Boyce-Codd范式)。每一级范式都比前一级更严格,致力于消除各种数据依赖关系,从而减少数据冗余。
- 第一范式(1NF) :确保列的原子性,每个字段都是不可再分的最小数据单位。
- 第二范式(2NF) :在1NF的基础上,消除对主键的部分依赖,即非主键字段完全依赖于主键。
- 第三范式(3NF) :在2NF的基础上,消除对主键的传递依赖,确保每一列都直接依赖于主键。
- BCNF :在3NF的基础上,要求每一个决定因素本身也是一个候选键。
在实际应用中,遵循这些范式可以帮助避免一些常见的设计错误,如更新异常、插入异常和删除异常。但是,过度范式化也可能导致查询性能下降,因为需要进行更多的表连接操作。因此,数据库设计时需要在数据完整性和性能之间找到平衡点。
4.1.2 MySQL的数据类型与索引优化
选择合适的数据类型对于优化性能、节省存储空间以及保证数据的准确性和完整性至关重要。MySQL提供了多种数据类型,包括整型、浮点型、字符型、日期和时间型等。
- 整型 :可以使用TINYINT、SMALLINT、MEDIUMINT、INT和BIGINT。
- 浮点型 :分为单精度浮点数(FLOAT)和双精度浮点数(DOUBLE)。
- 字符型 :用于存储字符串数据,如CHAR、VARCHAR、BINARY和VARBINARY等。
- 日期和时间型 :MySQL提供了DATE、TIME、DATETIME、TIMESTAMP和YEAR等类型。
索引是数据库优化的另一个关键方面,它能够提高查询效率,尤其是在大型数据集上。索引通过创建指向数据记录的指针来快速定位数据,但它们也会占用额外的存储空间,并可能在数据插入、更新和删除时降低性能。
MySQL支持多种索引类型,包括:
- B-Tree索引 :最常用的索引类型,支持全键值、键值范围和键值前缀搜索。
- 哈希索引 :基于哈希表实现,只适用于精确匹配。
- 全文索引 :用于文本数据的搜索,允许在多个单词间使用逻辑操作符。
- 空间索引 :用于空间数据类型,比如用于地理信息系统(GIS)数据。
在设计数据库和查询时,合理选择数据类型和索引可以显著提升系统的性能和效率。例如,为经常用于查询条件的列创建索引,以及根据查询模式选择合适的索引类型。
-- 示例:创建一个带有复合索引的表
CREATE TABLE book (
id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255) NOT NULL,
author VARCHAR(255) NOT NULL,
published_date DATE NOT NULL,
category VARCHAR(100),
INDEX idx_title_author (title, author)
);
在上述示例中, idx_title_author 是一个复合索引,它覆盖了 title 和 author 两个字段。这样的索引适用于查询时同时指定 title 和 author 的场景,可以加快这些字段的查询速度。
在使用索引时,还需考虑索引的维护成本。索引虽然能加快查询速度,但会减慢数据的插入、删除和更新操作,因为索引自身也需要被更新。此外,索引占用的磁盘空间也需要计入考量,尤其是在资源受限的环境中。
4.2 SQL语句高级应用
4.2.1 复杂查询与事务处理
SQL(Structured Query Language)是一种专门用于存储关系型数据库管理和操作的语言。高级SQL语句包括复杂的查询、事务处理、触发器和存储过程等。
事务 是SQL中的一个基本概念,它将多个操作捆绑在一起,作为一个单独的工作单元。事务确保了数据库的一致性和完整性,特别是在并发访问和错误恢复时。
事务具有以下四大特性:
- 原子性(Atomicity) :事务中的所有操作要么全部完成,要么全部不完成。
- 一致性(Consistency) :事务将数据库从一个一致性状态转换到另一个一致性状态。
- 隔离性(Isolation) :事务的执行不受其他事务的干扰。
- 持久性(Durability) :一旦事务提交,其结果就是永久的。
在SQL中,可以通过使用 BEGIN TRANSACTION 、 COMMIT 和 ROLLBACK 命令来控制事务。
-- 示例:使用事务处理
BEGIN TRANSACTION;
INSERT INTO sales (product_id, quantity) VALUES (101, 10);
UPDATE inventory SET quantity = quantity - 10 WHERE product_id = 101;
-- 如果插入和更新都成功,提交事务
COMMIT;
-- 如果有错误,回滚到事务开始的状态
-- ROLLBACK;
对于复杂查询,SQL提供了诸如 JOIN 、 UNION 、 GROUP BY 和 HAVING 等语句,允许从多个表中检索数据,并按特定条件进行分组和筛选。
-- 示例:使用JOIN来查询
SELECT orders.order_id, customers.customer_name, orders.order_date
FROM orders
JOIN customers ON orders.customer_id = customers.customer_id
WHERE orders.order_date BETWEEN '2021-01-01' AND '2021-12-31';
在使用事务和复杂查询时,需要仔细考虑查询性能,因为这些操作往往涉及多个表的连接和复杂的计算,可能会对数据库性能产生较大影响。
4.3 数据库性能调优
4.3.1 查询优化技巧
查询性能是衡量数据库系统效率的重要指标。优化查询可以减少响应时间,提高数据吞吐量。以下是一些常见的查询优化技巧:
- 使用索引 :合理创建和使用索引能够大幅提高查询效率。
- 避免全表扫描 :尽量使用索引来定位数据。
- 减少数据传输 :只检索需要的列,而不是使用
SELECT *。 - 优化子查询 :尽量将子查询转换为连接(JOIN)操作。
- 调整SQL语句结构 :避免在
WHERE子句中使用函数或计算表达式。 - 使用临时表和表变量 :对于大量数据的中间处理,可以使用临时表存储中间结果。
-- 示例:优化前的查询
SELECT * FROM sales WHERE YEAR(order_date) = 2021;
-- 优化后的查询,只选择需要的列
SELECT order_id, product_id, quantity FROM sales WHERE YEAR(order_date) = 2021;
4.3.2 SQL语句的分析与调试
在复杂的数据库应用中,SQL语句的分析和调试是不可避免的。为了提高SQL语句的效率和准确性,开发者可以使用一些工具和技巧来进行分析。
- 使用
EXPLAIN语句 :EXPLAIN可以提供关于SQL执行计划的详细信息,如如何访问表、使用了哪些索引等。 - 开启慢查询日志 :慢查询日志记录了执行时间超过设定阈值的查询语句,可以帮助识别和优化慢查询。
- 使用数据库管理工具 :现代数据库管理工具(如phpMyAdmin、MySQL Workbench)提供了查询分析器,可以直观地展示查询执行计划和性能数据。
-- 示例:使用EXPLAIN来分析查询执行计划
EXPLAIN SELECT * FROM sales WHERE YEAR(order_date) = 2021;
通过分析 EXPLAIN 输出的结果,可以了解到查询是否使用了索引、如何进行表连接、数据过滤和排序等关键信息,从而对查询进行优化。
通过深入理解和应用这些高级SQL语句和优化技巧,开发者可以显著提升数据库的性能和效率,满足高性能应用的需求。在下一章,我们将探讨如何将这些数据库技能与前端技术整合,共同实现网上书城的系统功能。
5. 网上书城系统功能实现与整合
5.1 用户注册登录功能实现
5.1.1 用户模块的需求分析与设计
在用户模块的开发过程中,需求分析是至关重要的一步。我们需要考虑用户注册与登录功能的易用性、安全性以及扩展性。
- 易用性 :界面应简洁直观,操作步骤尽可能少。
- 安全性 :密码应进行加密处理,防止SQL注入等攻击。
- 扩展性 :预留接口用于集成第三方登录服务(如社交账号登录)。
设计上,用户模块一般包含以下几个关键点:
- 用户信息表:存储用户名、密码、邮箱等基础信息。
- 用户验证机制:确保用户信息的唯一性和验证过程的安全性。
- 第三方登录接口:提供统一的认证接口,方便未来集成。
5.1.2 注册与登录流程的实现
注册流程一般包括用户提交注册信息、后端校验、保存用户信息到数据库等步骤。
// 示例伪代码,展示注册流程的核心逻辑
public class AccountService {
public boolean register(User user) {
// 校验用户名和邮箱是否已存在
if (isUsernameOrEmailExist(user)) {
return false; // 用户名或邮箱已存在,无法注册
}
// 对密码进行加密
user.setPasswordhash(hashPassword(user.getPassword()));
// 保存用户信息到数据库
return saveUserToDatabase(user);
}
}
登录流程则涉及到用户输入的凭证与数据库中存储的信息进行匹配。
// 示例伪代码,展示登录流程的核心逻辑
public class AccountService {
public boolean login(String username, String password) {
// 从数据库中查询用户信息
User user = findUserByUsername(username);
if (user != null && validatePassword(password, user.getPasswordhash())) {
// 登录成功,创建session或者token
return true;
}
return false; // 登录失败
}
}
5.2 图书浏览搜索功能实现
5.2.1 图书信息管理与展示
为了高效地管理和展示图书信息,通常会用一个或多个数据表存储图书的详细信息。
CREATE TABLE books (
id INT PRIMARY KEY AUTO_INCREMENT,
title VARCHAR(255) NOT NULL,
author VARCHAR(255) NOT NULL,
isbn VARCHAR(20),
price DECIMAL(10, 2) NOT NULL,
description TEXT,
stock INT NOT NULL
);
展示图书信息时,需要对数据进行分页和排序,以提升用户体验。
5.2.2 高效搜索功能的构建
构建高效的搜索功能,通常需要结合全文搜索引擎如Elasticsearch,或者利用数据库自身的全文搜索功能。
// 示例伪代码,展示搜索图书的核心逻辑
public List<Book> searchBooks(String query) {
// 使用全文搜索工具或数据库查询语句进行搜索
return elasticsearchService.search("title: " + query);
}
5.3 购物车管理与订单处理
5.3.1 购物车模块的设计与实现
购物车功能需要考虑的方面包括:
- 商品的添加、修改、删除
- 购物车持久化到数据库
- 购物车状态的同步更新
// 示例伪代码,展示添加商品到购物车的核心逻辑
public class ShoppingCart {
private List<CartItem> items = new ArrayList<>();
public void addItem(CartItem item) {
// 检查购物车中是否已经有此商品
for (CartItem existingItem : items) {
if (existingItem.getProductId().equals(item.getProductId())) {
// 增加商品数量
existingItem.setQuantity(existingItem.getQuantity() + item.getQuantity());
return;
}
}
// 添加新商品
items.add(item);
}
}
5.3.2 订单处理流程及其实现细节
订单处理通常包括创建订单、生成订单详情、支付确认以及订单状态的更新。
// 示例伪代码,展示创建订单的核心逻辑
public class OrderService {
public Order createOrder(User user, ShoppingCart cart) {
Order order = new Order();
order.setUser(user);
order.setStatus("NEW");
// 将购物车商品添加到订单详情
for (CartItem item : cart.getItems()) {
order.addOrderDetail(item);
}
// 保存订单到数据库
saveOrderToDatabase(order);
return order;
}
}
5.4 系统整合技术与实践
5.4.1 Struts与Hibernate的整合技术
整合Struts和Hibernate时,需要关注如何将Struts的Action类与Hibernate的Session交互。
// 示例伪代码,展示Struts Action与Hibernate Session的交互
public class BookAction extends ActionSupport {
private HibernateTemplate hibernateTemplate;
public String execute() {
// 使用HibernateTemplate进行数据库操作
hibernateTemplate.saveOrUpdate(book);
return SUCCESS;
}
}
5.4.2 Hibernate与MySQL的整合优化
优化整合的过程中,可以使用连接池来提高数据库操作的效率,同时合理设置Hibernate的缓存策略。
<!-- Hibernate配置文件片段,展示连接池的配置 -->
<property name="hibernate.connection.pool_size">10</property>
5.5 系统的高可扩展性与稳定性
5.5.1 系统架构的分层与模块化
通过分层设计,比如将表示层、业务逻辑层和数据访问层分离,可以提升系统的可维护性和可扩展性。
5.5.2 系统性能监控与稳定性保障
监控系统性能对于确保稳定性至关重要。可以通过集成监控工具来追踪异常和性能瓶颈。
graph LR
A[用户请求] -->|HTTP请求| B(Struts Action)
B --> C(Hibernate Session)
C --> D(MySQL数据库)
D -->|数据响应| C
C -->|操作结果| B
B -->|渲染视图| A
以上图表展示了用户请求通过各个层次直至数据库的流程,每个层次的处理结果都将影响到最终的用户体验。
简介:网上书城系统是一种在线图书销售平台,该系统通过整合Struts、Hibernate和MySQL这三种Java技术组件,实现了高效、稳定且用户友好的服务。Struts作为Web应用框架,控制应用程序流程并处理用户请求。Hibernate作为ORM框架,简化数据库交互,实现Java对象与数据库表的映射。MySQL负责数据存储,保证数据安全和快速访问。系统功能如用户注册登录、图书浏览搜索、购物车管理等模块都依赖这三个技术组件的紧密协作。开发者通过这种技术组合,可以设计和实现电子商务系统,提供良好的在线购物体验。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 20
20 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)