Task01-2【datawhale组队学习】DeepLearning
损失函数的作用:构建一个函数LbwL(b, w)Lbw,输入是模型的未知参数bbbwww,输出是“当参数取这些值时,预测结果好不好”的量化指标。简单说,就是用损失函数判断“当前模型参数下,预测值和真实值的差距有多大”。实例计算演示先给参数赋值(如b500b = 500b500w1w = 1w1),得到具体预测函数y500x1y500x1;
机器学习基础
机器学习:让机器具备找一个函数的能力。
语音识别:机器听一段声音,产生这段声音对应的文字。我们需要的是一个函数,该函数的输入是声音信号,输出是这段声音信号的内容。这个函数显然非常复杂,人类难以把它写出来,因此想通过机器的力量把这个函数自动找出来。还有好多的任务需要找一个很复杂的函数,以图像识别为例,图像识别函数的输入是一张图片,输出是这个图片里面的内容。
随着要找的函数不同,机器学习有不同的类别。
- 回归(regression):找输出为标量数值的函数,输入是与预测目标相关指标,如预测未来某时间PM2.5数值,输入关联指数,输出为该时间PM2.5数值 。
- 分类(classification):让机器做选择题,从设定类别里选一个输出,像检测邮件是否为垃圾邮件、AlphaGo下围棋选落子位置(19×19个选项选其一 ),类别数量可多可少 。
- 结构化学习(structured learning):机器生成有结构物体,如绘图、写文章,不局限于输出数值或选类别,需产出复杂结构化结果 。
案例学习
通过视频平台赚钱需关注频道流量(观看次数等)根据频道后台已有信息(点赞人数、订阅人数、历史观看次数等),找一个函数,实现 “输入后台信息,输出隔天频道总观看次数的预测值” 。这是机器学习典型的 “预测任务” 场景,明确要解决的核心问题是构建预测函数。
机器学习找函数的三个流程
步骤1:构建带未知参数的模型(函数)
- 函数形式:先写出含未知参数的函数 y = b + w x 1 y = b + wx_1 y=b+wx1,作为预测未来观看次数的“模型”。其中:
- y y y是预测目标(如某天频道总观看次数);
- x 1 x_1 x1 是“特征”,来自后台已知信息(如前一天频道总观看次数,是模型的输入依据 );
- b b b(偏置)、 w w w(权重)是未知参数,需后续通过数据确定 。
- 参数的初始猜测:未知参数 b b b、 w w w 初始靠“领域知识”模糊猜测(比如基于“今天观看次数和昨天可能有关联”的经验,假设用“昨天次数×权重 + 偏置”的形式建模 )。这种猜测不一定正确,后续会修正,但体现了“领域知识对模型构建的引导作用”——机器学习不是完全无依据瞎猜,需要结合实际问题的理解。
- 模型的定义:“带有未知参数的函数就是模型”,建立“模型 - 特征 - 参数(权重、偏置)”的概念关联,让读者理解机器学习中“模型”的基本构成。
步骤2:定义损失函数,衡量预测优劣
- 损失函数的作用:构建一个函数 L ( b , w ) L(b, w) L(b,w),输入是模型的未知参数 b b b、 w w w ,输出是“当参数取这些值时,预测结果好不好”的量化指标 。简单说,就是用损失函数判断“当前模型参数下,预测值和真实值的差距有多大” 。
- 实例计算演示:
- 先给参数赋值(如 b = 500 b = 500 b=500, w = 1 w = 1 w=1),得到具体预测函数 y = 500 + x 1 y = 500 + x_1 y=500+x1;
- 用“频道过去观看次数”当训练数据(如2017 - 2020年的历史数据 ),代入函数计算:
- 以2017年1月1日数据为例, x 1 = 4800 x_1 = 4800 x1=4800(前一天观看次数 ),预测值 y ^ = 5300 \hat{y} = 5300 y^=5300,真实值(标签) y = 4900 y = 4900 y=4900,计算误差 e 1 = ∣ y − y ^ ∣ = 400 e_1 = |y - \hat{y}| = 400 e1=∣y−y^∣=400;
- 再以1月2日预测1月3日为例,继续计算误差 e 2 e_2 e2 ,展示“用不同历史数据验证模型”的过程 。
- 最终,把所有天的误差求和取平均,得到整体损失 L = 1 N ∑ n e n L = \frac{1}{N}\sum_{n} e_n L=N1∑nen ,让读者明白“损失函数是通过大量数据计算误差,再统计整体误差的方式,衡量模型预测能力” 。
其他损失函数:
- 平均绝对误差(MAE):
误差计算用预测值与真实值的绝对差 e = ∣ y ^ − y ∣ e = |\hat{y} - y| e=∣y^−y∣,再对所有训练数据误差取平均得到损失 L L L 。 L L L 越大,参数越差; L L L 越小,参数越好 。 - 均方误差(MSE):
误差计算用预测值与真实值的平方差 e = ( y ^ − y ) 2 e = (\hat{y} - y)^2 e=(y^−y)2,同样对训练数据误差取平均得到损失 。 - 交叉熵(拓展):
当 y y y 和 y ^ \hat{y} y^ 是概率分布时(如分类任务),可用交叉熵作为损失函数,是机器学习第二步(定义损失)的常见形式 。
误差表面:可视化参数与损失的关系
- 概念与绘制:
调整不同的参数组合(如 w w w 和 b b b ),计算对应损失,将参数作为坐标轴、损失作为颜色/高度,画出的等高线图(或曲面图)就是误差表面 。比如视频点击预测案例中,不同 w w w、 b b b 组合对应不同损失,红色系代表损失大(参数差),蓝色系代表损失小(参数好 )。 - 实例验证:
文中用真实频道数据测试,发现 w = 0.75 , b = 500 w = 0.75, b = 500 w=0.75,b=500时预测较精准;若 w w w 接近1、 b b b较小(如100多 ),预测最精准,符合“前一天与隔天点击次数接近”的实际预期,体现误差表面能直观反映参数优劣 。
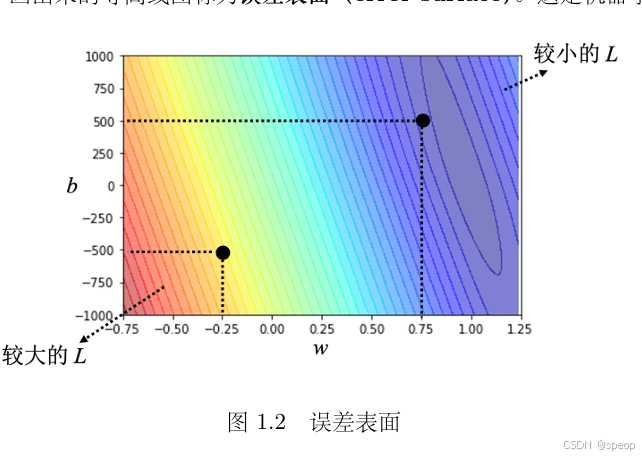
误差表面维度取决于参数个数
步骤3:用梯度下降优化参数(核心!)
1. 优化目标:找使损失最小的参数 w ∗ w^* w∗, b ∗ b^* b∗
要找到一组参数 w w w 和 b b b,让损失 L L L 最小,这组最优参数记为 w ∗ w^* w∗ 和 b ∗ b^* b∗ 。梯度下降是实现这一目标的常用优化方法 。
2. 梯度下降的单参数简化理解(先假设 b b b 已知,仅优化 w w w )
- 初始点与导数计算:
随机选初始参数 w 0 w^0 w0,计算损失函数在 w 0 w^0 w0 处的导数 ∂ L ∂ w ∣ w = w 0 \frac{\partial L}{\partial w}\big|_{w=w^0} ∂w∂L w=w0(即误差表面在该点的切线斜率 )。 【计算损失关于参数的偏导数】- 若斜率为负:说明右侧损失更低,增大 w w w 可减小损失; 若导数为负:说明 “往 w 增大的方向走,损失会减小”(因为 w 增加一点点,损失的变化量是负的,即损失变小 )。此时,梯度方向是 “w 减小的方向”(因为导数是负的,梯度向量指向山下的反方向 ),所以要逆梯度方向(增大 w )走,才能让损失减小。
- 若斜率为正:说明左侧损失更低,减小 w w w 可减小损失 。
- 要让损失减小,参数 w 的更新方向始终是 “逆导数方向”
- 参数更新规则:
新参数 w 1 = w 0 − η ⋅ ∂ L ∂ w ∣ w = w 0 w^1 = w^0 - \eta \cdot \frac{\partial L}{\partial w}\big|_{w=w^0} w1=w0−η⋅∂w∂L w=w0
其中 η \eta η 是学习率(超参数,需人工设定 )。
学习率决定参数更新“步长”: η \eta η 大,步长大,学习快但可能“跳过”最优解;() η \eta η 小,步长小,学习慢但更稳定 。 (斜率(导数绝对值)大,说明 “山坡陡”,步长可以大一点(下山快)), 斜率(导数绝对值)小,说明 “山坡缓”,步长可以小一点(下山稳)。
超参数:在机器学习过程中,需要人工提前设定、不是模型通过数据自动学习得到的参数,比如学习率 η \eta η - 迭代优化:
反复计算导数、更新参数( w 0 → w 1 → w 2 → … w^0 \to w^1 \to w^2 \to \dots w0→w1→w2→… ),直到满足停止条件(如参数更新次数达上限,或导数为0 )。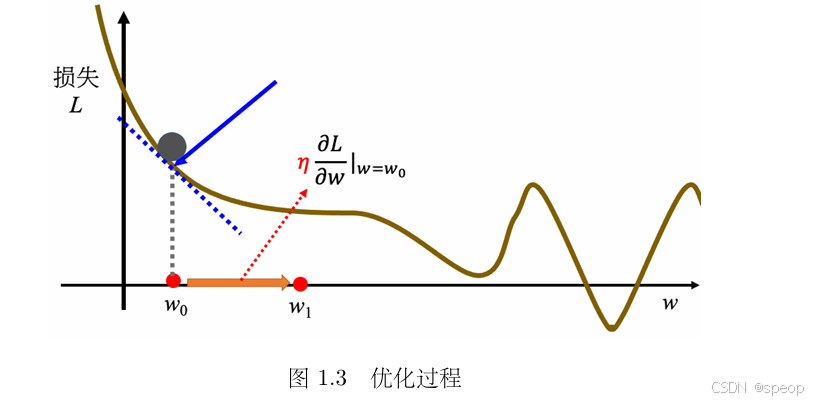
为什么损失可以是负的?
- 损失函数的自定义性:损失函数由使用者自行定义,不同的定义方式会导致损失值有不同的表现。若定义损失函数为 “估测值与正确值的绝对值再减 100”,就可能出现损失为负的情况 。
- 损失的非真实性(在特定自定义下):当自定义的损失函数不符合真实任务逻辑时(如上述不合理的减法操作 ),其对应的损失曲线不是真实任务的误差表面,形状可以是任意的,但在实际有意义的机器学习任务中,损失函数的定义要贴合任务目标,反映预测值与真实值的合理差距 。
3. 梯度下降的停止条件
- 人工设定更新次数上限:
比如最多更新100万次,达到后停止,“更新次数”也是超参数 。 - 导数为0(理想情况):
当导数为0时,参数更新量为0(因 w t + 1 = w t − η ⋅ 0 = w t w^{t+1} = w^t - \eta \cdot 0 = w^t wt+1=wt−η⋅0=wt ),参数不再变化,理论上此时找到“极值点” 。
4. 梯度下降的问题:局部最小值与全局最小值
- 概念区分:
- 全局最小值:误差表面的最低点,对应使损失最小的最优参数;
- 局部最小值:误差表面某区域的最低点,但不是全局最低,梯度下降可能陷入此处无法找到全局最优 。
- 实际难点:
梯度下降易因初始参数随机,陷入局部最小值(如案例中 w T w^T wT 位置),导致无法找到真正使损失最小的全局最优解 。不过文中也提到,“局部最小值是假问题”,实际更复杂的是多参数优化时的挑战,但单参数逻辑可推广到多参数 。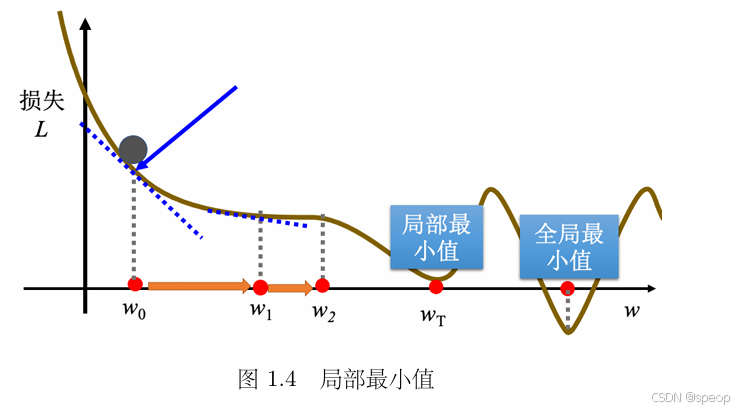
5. 多参数梯度下降(推广到 w w w 和 b b b 同时优化 )
- 导数计算与更新规则:
随机初始化 w 0 , b 0 w^0, b^0 w0,b0,分别计算损失对 w w w 和 b b b 的偏导数 ∂ L ∂ w ∣ w = w 0 , b = b 0 \frac{\partial L}{\partial w}\big|_{w=w^0, b=b^0} ∂w∂L w=w0,b=b0、 ∂ L ∂ b ∣ w = w 0 , b = b 0 \frac{\partial L}{\partial b}\big|_{w=w^0, b=b^0} ∂b∂L w=w0,b=b0 ,然后按以下规则更新:
w 1 ← w 0 − η ⋅ ∂ L ∂ w ∣ w = w 0 , b = b 0 b 1 ← b 0 − η ⋅ ∂ L ∂ b ∣ w = w 0 , b = b 0 \begin{align*} w^1 &\leftarrow w^0 - \eta \cdot \frac{\partial L}{\partial w}\big|_{w=w^0, b=b^0} \\ b^1 &\leftarrow b^0 - \eta \cdot \frac{\partial L}{\partial b}\big|_{w=w^0, b=b^0} \\ \end{align*} w1b1←w0−η⋅∂w∂L w=w0,b=b0←b0−η⋅∂b∂L w=w0,b=b0- 把 w 0 w_0 w0 减掉学习率乘上微分的结果得到 w 1 w_1 w1
- 把 b 0 b_0 b0 减掉学习率乘上微分的结果得到 b 1 b_1 b1。
参数更新流程:反复计算损失函数对参数 w w w、 b b b 的偏导数,依据偏导数确定更新方向( − η ⋅ ∂ L ∂ w -\eta \cdot \frac{\partial L}{\partial w} −η⋅∂w∂L、 − η ⋅ ∂ L ∂ b -\eta \cdot \frac{\partial L}{\partial b} −η⋅∂b∂L ),不断迭代更新参数,期望找到最优的 w ∗ w^* w∗ 和 b ∗ b^* b∗ 。 如下图
- 深度学习框架的作用:
如PyTorch等框架可自动计算偏导数(即“自动微分” ),简化梯度下降实现,只需定义损失函数和参数,框架会完成导数计算与参数更新 。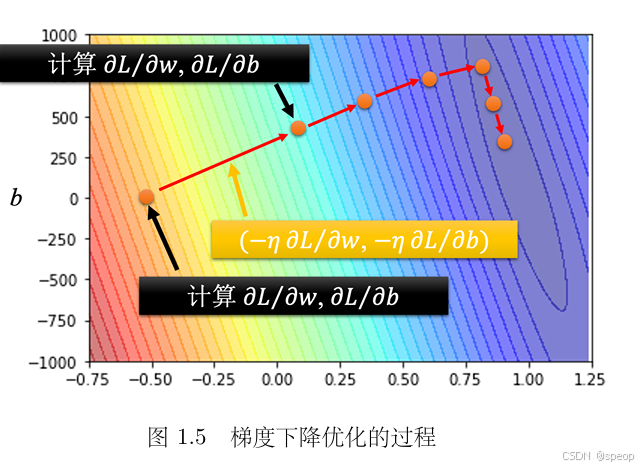
线性模型
这部分内容围绕视频观看次数预测模型的迭代优化展开,需注意以下要点:
一、模型预测与误差表现
-
训练集与测试集误差差异:
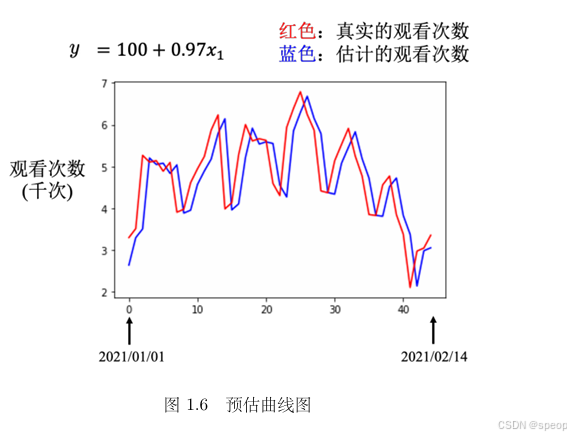
- 在已知的2017 - 2020年训练数据上,模型(如 y = 100 + 0.97 x 1 y = 100 + 0.97x_1 y=100+0.97x1)损失小( L = 480 L = 480 L=480);但在2021年未知数据上预测时,误差变大(平均约580人 ),体现模型在训练集和测试集上的泛化能力差异,需关注模型是否过拟合。
- 后续改进模型(考虑7天、28天、56天数据)后,训练集损失逐步降低(如7天模型训练集损失380 ),但测试集(2021年数据)损失下降幅度有限,说明增加特征(历史天数)能提升训练拟合度,但对未知数据的泛化提升有瓶颈。
-
预测曲线的合理性与问题:
- 简单模型(仅用前1天数据)的预测曲线(蓝色)几乎是真实曲线(红色)右移一天,符合“用前一天预测后一天”的逻辑,但无法捕捉数据的周期性规律(如每周五、周六观看量特别低 ),导致未知数据预测误差大。 如果一个模型参考前7天的数据,把7天前的数据,直接复制到拿来当作预测的结果,也许预测的会更准也说不定,所以我们就要修改一下模型。通常一个模型的修改,往往来自于对这个问题的理解,即领域知识。
二、模型改进的逻辑与方法
-
领域知识的作用:
- 发现数据“每隔7天有周期性(周五、周六观看量低)”这一领域知识后,改进模型,从“仅用前1天数据”扩展到“用前7天数据”,体现“模型改进需结合对问题本质的理解”,领域知识能指导特征工程(如加入历史多天数据)。
-
线性模型的扩展与特征工程:
- 改进后的模型是线性模型( y = b + ∑ w j x j y = b + \sum w_j x_j y=b+∑wjxj ),通过增加输入特征( x j x_j xj代表前 j j j 天的观看次数 ),用不同权重 w j w_j wj组合历史数据做预测。
- 扩展特征时,从“前7天”到“前28天”“前56天”,训练集损失持续降低,但测试集损失未同步大幅下降,说明特征数量增加存在边际效应,过度增加可能导致计算成本上升、泛化能力停滞。
三、模型结果与参数分析
-
参数的含义与规律:
- 7天模型的参数中, w 1 ∗ = 0.79 w_1^* = 0.79 w1∗=0.79(前1天权重正,关联大 ), w 2 ∗ , w 4 ∗ , w 5 ∗ w_2^*, w_4^*, w_5^* w2∗,w4∗,w5∗为负(前2、4、5天与预测值成反比 ), w 3 ∗ , w 6 ∗ , w 7 ∗ w_3^*, w_6^*, w_7^* w3∗,w6∗,w7∗为正(前3、6、7天关联为正 ),体现模型学习到“不同历史天数对次日观看量的影响有正有负”,反映数据内在关联。
-
线性模型的本质:
- 所有改进的模型都属于线性模型,结构为“输入特征 x j x_j xj 乘权重 w j w_j wj 加偏置 b b b)”,这是后续优化模型(如提升非线性拟合能力)的基础,需注意线性模型对复杂非线性关系的拟合局限性。
分段线性曲线
通过引入分段线性曲线,利用多个简单分段函数的组合,实现对复杂非线性关系的拟合。
线性模型的固有局限:线性模型( y = b + w x 1 y = b + wx_1 y=b+wx1 )只能描述线性关系,即 x 1 x_1 x1 与 y y y 呈直线关联( x 1 x_1 x1增大, y y y单调增大 )。但现实中 x 1 x_1 x1 和 y y y 可能有复杂非线性关系(如 x 1 x_1 x1过大时 y y y反而减小 ),线性模型无法拟合这类关系,此为模型偏差,是模型结构导致的先天限制 。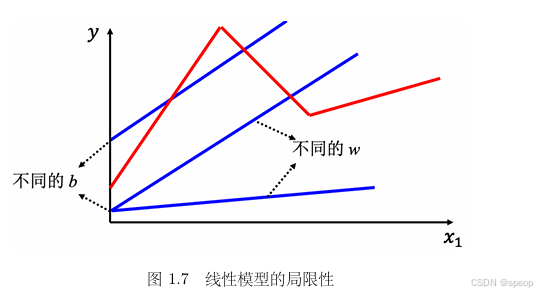
红色的线可以看作是一个常数项加一大堆的蓝色函数(Hard Sigmoid)。
HardSigmoid函数特性:当 x 轴的值小于某一个阈值(某个定值)的时候,大于另外一个定值阈值的时候,中间有一个斜坡。所以它是先水平的,再斜坡,再水平的。
Hard Sigmoid 函数是分段线性的 “阶梯 - 斜坡 - 阶梯” 形状:
- 当输入 x 小于 “低阈值”:输出水平(斜率为 0 );
- 当输入 x 在 “低阈值 - 高阈值” 之间:输出斜坡(斜率固定 );
- 当输入 x 大于 “高阈值”:输出水平(斜率为 0 )。
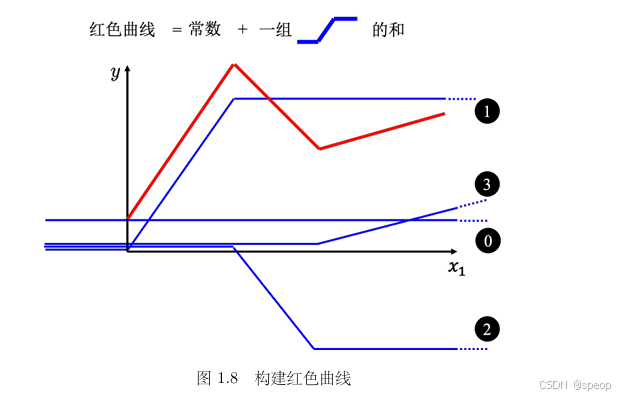
用多个简单、可控的 Hard Sigmoid 函数,通过 “分段覆盖曲线区间 + 匹配对应段斜率” 的方式,叠加出复杂的红色曲线。
假设红色曲线有 3 个转折点,需用 3 个 Hard Sigmoid 函数 拼接,步骤如下:
- 第 1 个蓝色函数(覆盖曲线最左侧)
斜坡起点:对齐红色曲线的 “起始斜坡点”;
斜坡斜率:与红色曲线最左侧斜坡的斜率完全相同;
叠加效果:常数(红色曲线与 x 轴交点 )+ 第 1 个蓝色函数 → 拼出红色曲线最左侧线(0+1)。 - 第 2 个蓝色函数(覆盖曲线中间段)
斜坡起点:对齐红色曲线的 “第 1 个转折点”;
斜坡斜率:与红色曲线中间段斜坡的斜率完全相同;
叠加效果:常数 + 第 1 个蓝色函数 + 第 2 个蓝色函数 → 拼出红色曲线左侧 + 中间线段(0+1+2)。 - 第 3 个蓝色函数(覆盖曲线最右侧)
斜坡起点:对齐红色曲线的 “第 2 个转折点”;
斜坡斜率:与红色曲线最右侧斜坡的斜率完全相同;
叠加效果:常数 + 3 个蓝色函数 → 拼出完整红色曲线(0+1+2+3)。
分段线性曲线的构建逻辑:用“常数 + 多个 Hard Sigmoid 函数(蓝色函数)”组合出分段线性曲线(红色曲线 )。每个 Hard Sigmoid 函数负责拟合曲线的一段,通过调整其斜坡起点、终点和斜率,让多个蓝色函数叠加后,拼接出复杂的分段线性关系。曲线越复杂(转折点越多 ),需要的蓝色函数数量越多 。
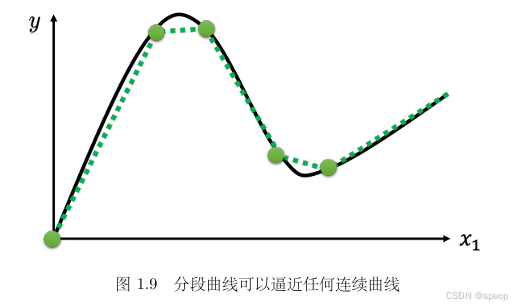
分段线性曲线逼近任意连续曲线:如图1.9所示的曲线。分段线性曲线可通过 “取点 - 连线” 的方式,逼近任意连续曲线。只要取点足够多、位置合适,分段线性曲线就能近似有角度、弧度的连续曲线,体现了 “简单分段函数叠加可模拟复杂非线性” 的思想。只要有足够的蓝色函数把它加起来,就可以变成任何连续的曲线。
-
Hard Sigmoid(硬 sigmoid):
形状是 “水平 → 斜坡 → 水平” (像一个带斜坡的台阶 ),特点是“分段线性、突变明显”,但数学表达式复杂(直接写出来很麻烦 )。
y hard = { 0 , x 1 ≤ a k ( x 1 − a ) , a < x 1 < b c , x 1 ≥ b y_{\text{hard}} = \begin{cases} 0, & x_1 \leq a \\ k(x_1 - a), & a < x_1 < b \\ c, & x_1 \geq b \end{cases} yhard=⎩ ⎨ ⎧0,k(x1−a),c,x1≤aa<x1<bx1≥b
(( a, b ) 是阈值,( k ) 是斜坡斜率 ) -
Sigmoid(常规 sigmoid):
形状是 “平滑的 S 型曲线” ,数学表达式简单 y = c ⋅ 1 1 + e − ( b + w x 1 ) y = c \cdot \frac{1}{1 + e^{-(b + wx_1)}} y=c⋅1+e−(b+wx1)1,特点是“连续可导、易计算”,但形状是平滑的,不是硬台阶。 其横轴输入是x1,输出是y,c为常数。-
当 x 1 → + ∞ x_1 \to +\infty x1→+∞:
− ( b + w x 1 ) → − ∞ -(b + w x_1) \to -\infty −(b+wx1)→−∞,所以 e − ( b + w x 1 ) → 0 e^{-(b + w x_1)} \to 0 e−(b+wx1)→0,因此 y → c ⋅ 1 1 + 0 = c y \to c \cdot \frac{1}{1 + 0} = c y→c⋅1+01=c(趋近于水平高值 c c c )。 -
当 x 1 → − ∞ x_1 \to -\infty x1→−∞:
− ( b + w x 1 ) → + ∞ -(b + w x_1) \to +\infty −(b+wx1)→+∞,所以 e − ( b + w x 1 ) → + ∞ e^{-(b + w x_1)} \to +\infty e−(b+wx1)→+∞,因此 y → c ⋅ 1 1 + ∞ = 0 y \to c \cdot \frac{1}{1 + \infty} = 0 y→c⋅1+∞1=0(趋近于水平低值 0 )。 -
当 x 1 x_1 x1 适中时:
y y y 在 0 和 c c c 之间平滑过渡,形成 S 型曲线。
-
- Hard Sigmoid 是“理想的分段线性模块”,但不好计算;
- Sigmoid 是“近似的平滑模块”,好计算、易优化;
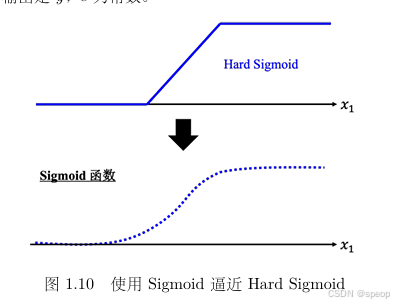
sigmoid函数逼近Hard Sigmoid——逼近的具体逻辑
-
形状近似:
当 x 1 x_1 x1 很大时,Sigmoid 函数会趋近于 c c c(水平 );当 x 1 x_1 x1 很小时,趋近于 0(水平 );中间是平滑过渡的斜坡。这和 Hard Sigmoid 的“水平 → 斜坡 → 水平”形状趋势一致,所以能用 Sigmoid 近似 Hard Sigmoid。 -
参数调整:
通过调整 Sigmoid 函数的参数 b b b(左右平移 )、 w w w(调整斜坡陡峭度 )、 c c c(调整水平高度 ),可以让 Sigmoid 曲线无限接近 Hard Sigmoid 的形状。虽然不能完全一模一样,但实际应用中,这种近似足够用,还能简化计算。
简化公式 y = c σ ( b + w x 1 ) y = c \sigma(b + w x_1) y=cσ(b+wx1)
这里的 σ \sigma σ其实是 “阶梯函数的简化近似” ,更准确地说,是把 Sigmoid 的指数部分用线性函数近似(在特定条件下,指数函数可被线性近似替代,简化计算 )。
举个例子:当 b + w x 1 b + w x_1 b+wx1 的绝对值很大时,Sigmoid 接近 Hard Sigmoid 的水平段;当 b + w x 1 b + w x_1 b+wx1接近 0 时,Sigmoid 的斜率最大,近似 Hard Sigmoid 的斜坡段。
Sigmoid 函数的参数控制(基础变形)
-
参数 ( w ) 的作用:
调整 ( w ) 会改变 Sigmoid 曲线的斜率(斜坡陡峭度) 。( w ) 越大,曲线中间的斜坡越陡,越接近“硬阶跃”;( w ) 越小,斜坡越平缓。 -
参数 ( b ) 的作用:
调整 ( b ) 会让 Sigmoid 曲线左右平移 。( b ) 增大,曲线整体右移;( b ) 减小,曲线整体左移。 -
参数 ( c ) 的作用:
调整 ( c ) 会改变 Sigmoid 曲线的最大高度 。( c ) 越大,曲线顶端越接近 ( c );( c ) 越小,顶端越低。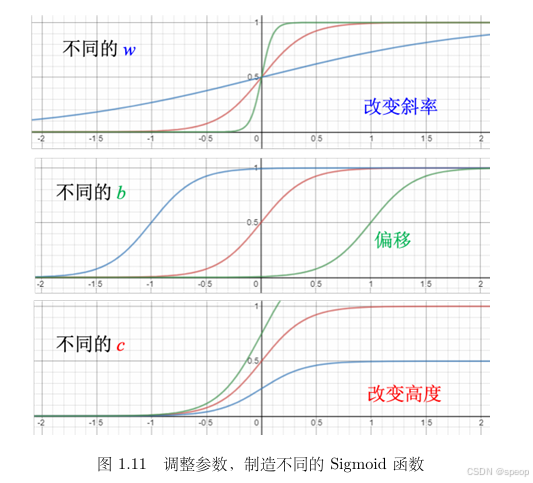
Sigmoid 叠加:从简单到复杂模型
如图1.12 所示,红色这条线就是0加1+2+3,而 1 、 2 、 3 1、2、3 1、2、3都是蓝色的函数,其都可写成 ( b + w x 1 ) (b+wx1) (b+wx1),去做 Sigmoid 再乘上 c i 1 c_i1 ci1,只是 1、2、3 的 w 、 b 、 c w、b、c w、b、c不同。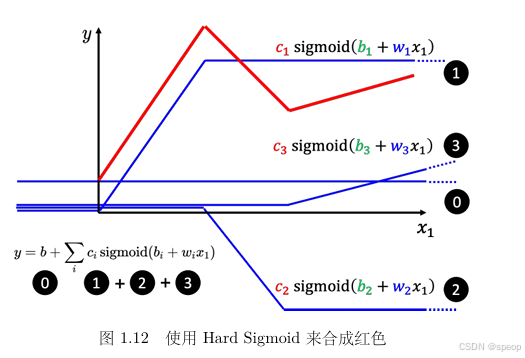
-
叠加逻辑:
多个不同参数( w , b , c w, b, c w,b,c )的 Sigmoid 函数叠加( y = b + ∑ c i σ ( b i + w i x 1 ) y = b + \sum c_i \sigma(b_i + w_i x_1) y=b+∑ciσ(bi+wix1)),可组合出任意分段线性曲线 。每个 Sigmoid 负责拟合曲线的一段,叠加后还原复杂形状。 -
与连续曲线的关系:
分段线性曲线可逼近任意连续曲线,因此多个 Sigmoid 叠加 → 分段线性曲线 → 逼近连续曲线 ,这是神经网络拟合复杂关系的底层逻辑。
引入多特征
不止用单个特征 x 1 x_1 x1,而是引入多个特征(如 x 1 , x 2 , x 3 x_1, x_2, x_3 x1,x2,x3 代表前1、2、3天的观看次数 ),让每个 Sigmoid 函数的输入变为多特征的线性组合 r i = b i + ∑ w i j x j r_i = b_i + \sum w_{ij} x_j ri=bi+∑wijxj,大幅提升模型对复杂关系的捕捉能力。
多特征的线性组合可简化为矩阵乘法 r = b + W x \boldsymbol{r} = \boldsymbol{b} + \boldsymbol{W}\boldsymbol{x} r=b+Wx,这是深度学习中“线性变换 + 非线性激活”的标准形式,体现了模型从“单特征”到“多特征”的扩展。
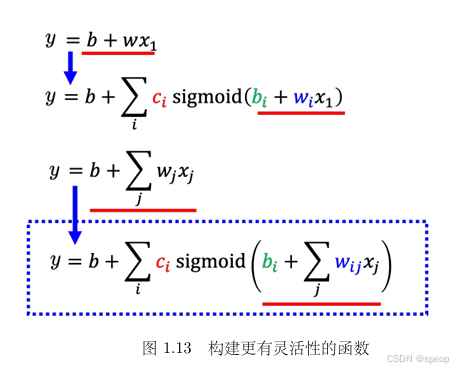
优化方法的选择:
穷举法的局限性:
当参数极少时(如仅 w , b w, b w,b) ),可穷举所有可能值找最优;但参数极多时(如多特征 + 多 Sigmoid ),穷举法不可行,必须用梯度下降等优化算法。
2. 损失函数的泛化:
损失函数的计算逻辑不变(预测值与真实值的误差总和 ),但优化对象从少数参数变为高维参数向量 θ \boldsymbol{\theta} θ,需用梯度下降迭代更新。
可学习参数和超参数:
-
可学习参数:
w i j , b i , c i w_{ij}, b_i, c_i wij,bi,ci 是模型的可学习参数,通过数据训练优化,让模型拟合输入输出关系。 -
超参数(隐含):
Sigmoid 函数的数量是超参数(需人工设定,数量越多模型越灵活,但训练成本越高 ),属于模型结构设计的一部分。
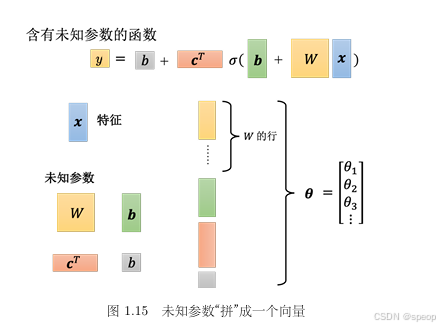
参数向量化:
所有未知参数( W , b , c , b \boldsymbol{W}, \boldsymbol{b}, \boldsymbol{c}, b W,b,c,b )被统一表示为向量 θ \boldsymbol{\theta} θ,简化了损失函数的书写(从 L ( w , b ) L(w, b) L(w,b) 变为 L ( θ L(\boldsymbol{\theta} L(θ) ),让模型训练更聚焦“参数向量优化”
模型灵活性:多特征输入+多sigmoid叠加+可学习参数+超参数调节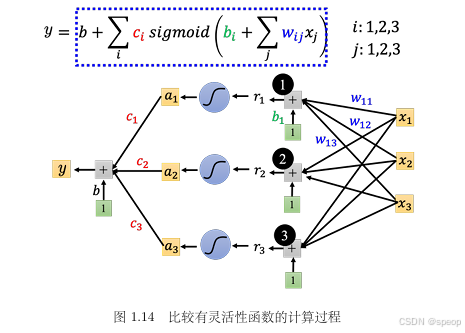
用向量化参数简化优化目标,用批量训练平衡计算效率与稳定性
梯度下降的核心流程
-
梯度的意义:
梯度 g = ∇ L ( θ ) \boldsymbol{g} = \nabla L(\boldsymbol{\theta}) g=∇L(θ)是损失函数对参数的偏导数向量,指示“参数往哪个方向调整,损失下降最快” 。参数越多,梯度向量维度越高(如1000个参数对应1000维梯度 )。 -
参数更新公式:
每次用梯度更新参数: θ t + 1 ← θ t − η g \boldsymbol{\theta}_{t+1} \leftarrow \boldsymbol{\theta}_t - \eta \boldsymbol{g} θt+1←θt−ηg ,其中 η \eta η 是学习率,控制更新步长。核心逻辑是“沿梯度反方向调整参数,逐步减小损失” 。
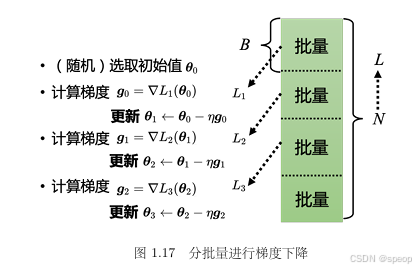
批量梯度下降(Batch GD)
-
批量(Batch)的作用:
实际训练时,不会用全部数据算损失(计算量太大 ),而是随机分组(批量) ,用每个批量的损失 L i L_i Li近似整体损失 L L L。批量大小 B B B是超参数,影响训练效率和稳定性。 -
回合(Epoch)与更新的区别:
- 更新:用一个批量的梯度更新一次参数,称为一次更新;
- 回合:所有批量都被使用一次(遍历全部数据 ),称为一个回合。
一个回合包含多次更新(更新次数 = 总数据量 / 批量大小 ),需注意两者的差异。
超参数与训练细节
-
超参数的新增:
批量大小 B B B 是超参数,需人工设定。不同 B B B 影响训练速度(大 B B B 计算慢但稳定,小 B B B计算快但波动大 )。 -
梯度下降的终止条件:
通常不会等到梯度为0(工程上难实现 ),而是设定“回合数”“损失阈值”或“梯度变化量”,达到条件即停止训练。
模型变形
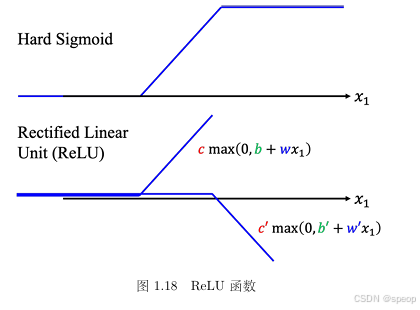
不一定要把Hard Sigmoid 换成 Soft Sigmoid。Hard Sigmoid 可以看作是两个修正线性单元(Rectified Linear Unit,ReLU)的加总。。要合成 i 个 Hard Sigmoid,需要i个Sigmoid,如果 ReLU 要做到一样的事情,则需要2i个ReLU。
激活函数的选择
- Sigmoid 和 ReLU 是最常见的激活函数,但 ReLU 在实验中表现更好。
- ReLU 的数学表达式:
c ⋅ max ( 0 , b + w x 1 ) c \cdot \max(0, b + w x_1) c⋅max(0,b+wx1)- 当 b + w x 1 > 0 b + w x_1 > 0 b+wx1>0,输出 b + w x 1 b + w x_1 b+wx1(线性增长)。
- 当 b + w x 1 ≤ 0 b + w x_1 \leq 0 b+wx1≤0,输出 0(抑制负值)。
- Hard Sigmoid 可由 2 个 ReLU 叠加 构成,但 ReLU 更灵活,计算效率更高。
模型复杂度与拟合能力
- 线性模型(1层) 拟合能力有限,训练损失较高(320),测试损失更高(460)。
- 增加 ReLU 数量 可提高模型表达能力:
- 10 ReLU:训练损失 ≈ 线性模型(320 → 320),测试损失略降(460 → 450)。
- 100 ReLU:训练损失显著降低(320 → 280),测试损失改善(460 → 430)。
- 1000 ReLU:训练损失进一步降低(280 → 270),但测试损失未变(430 → 430),可能出现过拟合。
多层神经网络(深度学习)
-
增加隐藏层 可提升模型性能,但需平衡深度与过拟合风险:
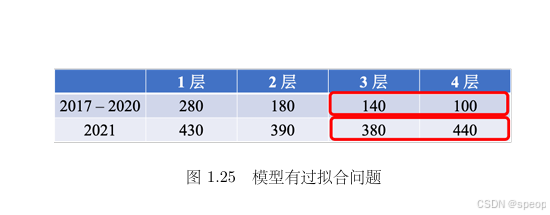
- 1 层:训练损失 280,测试损失 430。
- 2 层:训练损失 180,测试损失 390。
- 3 层:训练损失 140,测试损失 380(最佳泛化)。
- 4 层:训练损失 100,但测试损失上升至 440(过拟合)。
-
过拟合现象:模型在训练数据上表现极佳,但在未见数据上性能下降(如 4 层网络)。
- 图1.25显示,随着模型层数增加(1层到4层),某些年份(如2021年)的指标异常升高,可能表明过拟合(模型在训练数据上表现过好,泛化能力下降)。
- 需注意平衡模型复杂度与泛化性能,避免过拟合。
实验观察与优化
- ReLU 的折线特性:100 ReLU 可生成 100 段折线,比线性模型更灵活。
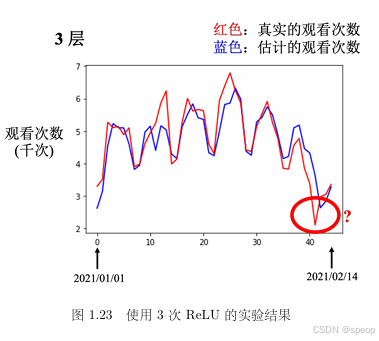
- 时间序列预测案例(图 1.23):
- 模型能捕捉周期性低谷(如节假日),但可能滞后(如除夕预测晚 1 天)。
- 输入仅依赖前 56 天数据,无法利用外部信息(如节日日期)。
- 反向传播(BackPropagation, BP):用于高效计算梯度,优化深层网络参数。
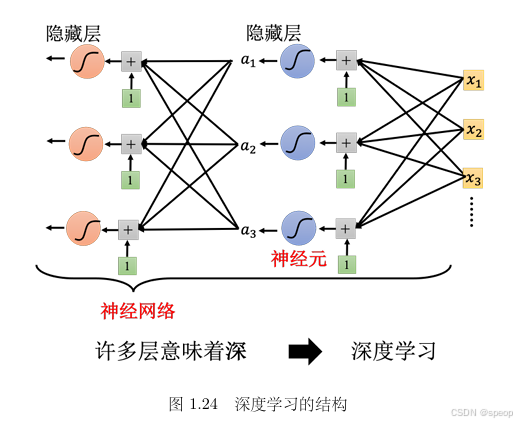
Sigmoid 或 ReLU 称为神经元(neuron),很多的神经元称为神经网络(neural network)。每一排称为一层,称为隐藏层(hidden layer),很多的隐藏层就“深”,这套技术称为深度学习。
神经网络与深度学习
- 深度学习的特点是具有多个隐藏层(如图1.24所示),层数越多网络越“深”。
- 图中标注了输入层( x 1 , x 2 , x 3 x_1, x_2, x_3 x1,x2,x3)、隐藏层( a 1 , a 2 , a 3 a_1, a_2, a_3 a1,a2,a3)及其层级结构。
深度学习的发展
- 历史背景:神经网络 80-90 年代已存在,近年因算力提升和深层架构(如 ResNet)复兴。
- 层数增加的影响:
- AlexNet(8 层)→ VGG(19 层)→ GoogleNet(22 层)→ ResNet(152 层),错误率持续下降。
- 但实验显示,并非层数越多越好(4 层比 3 层测试损失更高)。
- 超参数调整:需谨慎选择层数、神经元数量、激活函数等,避免过拟合
机器学习框架
机器学习框架的基本流程
- 训练数据包含输入 x x x 和对应的标签 y y y,形式为 { ( x 1 , y 1 ) , … , ( x N , y N ) } \{ (x^1, y^1), \ldots, (x^N, y^N) \} {(x1,y1),…,(xN,yN)}。
- 测试数据仅包含输入 x x x,形式为 { x N + 1 , … , x N + M } \{ x^{N+1}, \ldots, x^{N+M} \} {xN+1,…,xN+M}。
模型训练的3个关键步骤
- 步骤1:定义带未知参数 θ \theta θ 的函数 f θ ( x ) f_\theta(x) fθ(x), θ \theta θ表示模型的所有待学习参数。
- 步骤2:定义损失函数 L ( θ ) L(\theta) L(θ),用于评估参数 θ \theta θ 的性能。
- 步骤3:通过优化找到最小化损失的参数 θ ∗ \theta^* θ∗,即 θ ∗ = arg min θ L \theta^* = \arg \min_{\theta} L θ∗=argminθL。
测试阶段
-
将优化得到的 θ ∗ \theta^* θ∗ 应用于测试集,生成预测结果并提交
- 其他注意事项
- 确保训练数据和测试数据的分布一致,避免因数据偏差导致性能下降。
- 损失函数的选择需与任务类型匹配(如分类用交叉熵,回归用均方误差)。
- 深度学习模型需谨慎调整超参数(如学习率、层数)以优化性能。
公式
- 多特征线性组合: r = b + W x \boldsymbol{r} = \boldsymbol{b} + \boldsymbol{W}\boldsymbol{x} r=b+Wx
- 非线性激活(Sigmoid ): a = σ ( r \boldsymbol{a} = \sigma(\boldsymbol{r} a=σ(r)
- 输出计算: y = b + c T a y = b + \boldsymbol{c}^\text{T}\boldsymbol{a} y=b+cTa
- 损失函数: L ( θ ) = ∑ ( y ^ − y ) 2 L(\boldsymbol{\theta}) = \sum (\hat{y} - y)^2 L(θ)=∑(y^−y)2(误差总和 ) (批量损失则为 L i L_i Li )
- 梯度计算: g = ∇ L ( θ ) \boldsymbol{g} = \nabla L(\boldsymbol{\theta}) g=∇L(θ)
- 参数更新: θ t + 1 = θ t − η g \boldsymbol{\theta}_{t+1} = \boldsymbol{\theta}_t - \eta \boldsymbol{g} θt+1=θt−ηg
- 批量训练:用 L i L_i Li 替代 L L L ,遍历所有批量完成一个回合。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)