后端工程师睡前必读的故事:从宕机恐慌到自愈 - Docker 和 Kubernetes
凌晨两点,后端工程师小李的手机再次震动,熟悉的报警声划破夜空——服务器宕机了。困倦中,他的大脑像被重置了一样,涌现出杂乱的意识流:“为什么又是我?为什么总在半夜出事?” 服务器就像一只难以驯服的野兽,在关键时刻抛下他独自狂奔。每一次服务崩溃,他都心跳加速、冷汗直流,仿佛看见无数用户愤怒的目光在黑暗中闪烁。宕机意味着用户流失、领导责问,还有自己越来越浓的自我怀疑。那一夜,小李扶着额头盯着屏幕,代码在
这是一篇写给所有“写过 Docker 却还没睡好觉”的程序员的故事,也是一个从“手动部署”到“自愈系统”的进化过程。
- 为什么 Docker 不等于高可用?
- Kubernetes 到底解决了什么?
- Pod、Service、Deployment 到底该怎么理解?
我把这一切都写进了这个故事里,一边讲清楚技术,一边顺手治好了焦虑。

凌晨的宕机噩梦
凌晨两点,后端工程师小李的手机再次震动,熟悉的报警声划破夜空——服务器宕机了。困倦中,他的大脑像被重置了一样,涌现出杂乱的意识流:“为什么又是我?为什么总在半夜出事?” 服务器就像一只难以驯服的野兽,在关键时刻抛下他独自狂奔。每一次服务崩溃,他都心跳加速、冷汗直流,仿佛看见无数用户愤怒的目光在黑暗中闪烁。宕机意味着用户流失、领导责问,还有自己越来越浓的自我怀疑。
那一夜,小李扶着额头盯着屏幕,代码在昏黄台灯下格外刺眼。他的思绪开始飘离现实:仿佛身处一间杂乱的厨房,各种版本的运行环境散落一地,MySQL、Python、Redis像油盐酱醋般掺杂在一起,一旦火候不对便炸锅。“难道没有一种万能的容器,可以把这一切都装起来,打包成标准化的‘外卖’送到任何地方吗?”他苦笑着自言自语。这一刻的灵光一现,为他日后的转机埋下了伏笔。
容器(Container):装载应用的外卖盒
疲惫不堪的小李在网上搜索解决方案时,第一次遇见了 “容器” 技术。资料上写着:Docker 是“应用集装箱”,就像货轮用标准集装箱运输货物,可以把应用程序及其依赖环境打包进一个轻量可携带的“箱子”,在任何电脑上都能秒级运行。这一句话击中了他的痛点——如果应用和环境都封装在一个“箱子”里,不就再也没有“在我电脑上好好的,上线就崩”的悲剧了吗?外卖盒里的菜到了哪儿都一个味,容器里的应用到哪儿都一键开箱即用。
小李脑中浮现出昨天凌晨的幻象:一个外卖小哥拎着贴有“Docker”标签的餐盒飞奔而来,盒子里是他精心烹制的应用和调配好的环境佐料(代码、数据库、依赖库)。没有冗长的安装和配置过程,只需“啪”地撕开封条,应用就运行起来了。正如资料所说,传统方式需要每台服务器重新装系统、配环境(往往耗时数小时),而使用容器只需下载镜像、运行容器,不到十秒钟就能部署好一个新环境!想到平日里在新服务器上折腾环境的自己,他不禁感慨:以前像在每间新厨房里重头装修,现在则是把已经调试好的整套厨房直接打包带走。容器让部署新服务器的速度从“小时级”飞跃到了“秒级”。
更妙的是,容器之间相互隔离,彼此独立运行,宛如一栋公寓里分隔明确的房间,各住各的互不打扰。这意味着再也不会发生“PHP 7.4 和 PHP 8.0 无法共存”的窘境——不同版本、不同类型的应用可以安心待在各自容器里,各用各的依赖,而宿主机的资源由操作系统统一调度,利用率大幅提升。小李仿佛看见自己服务器上曾经为了避免冲突而小心翼翼安放的各种服务,如今被装进一个个彼此隔绝的盒子里,各显其能却又井然有序。
容器的出现开始治愈他的“宕机焦虑”。起码环境不一致的问题有了解决方案:测试环境怎样,生产环境也一样,再也不会因为“这台机器没装某某库”或“系统版本不兼容”而半夜背锅。小李迫不及待地想试一试。他决定用 Docker 把自己的应用封装起来。
镜像(Image)与 Dockerfile:厨房蓝图与食谱
说干就干。要使用 Docker,首先需要制作一个镜像(Image),它就像容器的底层模版或“蓝图”。网上的类比让他恍然大悟:镜像好比详细绘制的厨房设计图纸,里面规划了炉灶、冰箱等所有配置;而容器则是根据图纸建成的现实厨房,供厨师(应用)在里面烹饪。换言之,镜像是静态的文件组合,容器是镜像运行后的动态进程。
如何制作这样一份“厨房蓝图”呢?这就要编写 Dockerfile 了。Dockerfile 就像烹饪菜肴的食谱:一步步规定了如何从基础食材(基础镜像)开始,加入哪些调料(依赖库)、烹调哪些菜肴(复制代码、安装依赖),最终出锅一道完整的应用镜像。小李打开编辑器,写下人生中第一份 Dockerfile:
# 选择基础镜像,比如 Python 3.9
FROM python:3.9
# 将当前目录下代码拷贝进镜像的 /app 目录
COPY . /app
WORKDIR /app
# 安装所需依赖
RUN pip install -r requirements.txt
# 容器启动时运行应用
CMD ["python", "app.py"]几行简洁的指令,描述了如何组装出一个包含他应用的一切所需的镜像。“就像把调试好的‘Python环境+MySQL数据库+代码’打包冻结成镜像”,小李将这个镜像命名为 myapp:v1。完成Dockerfile后,他运行命令构建镜像:
docker build -t myapp:v1 .不一会儿,myapp:v1 镜像构建成功。小李的心情有些激动,仿佛手里拿到了一张厨房蓝图。接下来就是见证奇迹的时刻:用这张蓝图去“建造”容器。只需一条命令:
docker run -d -p 5000:5000 myapp:v1伴随着风扇的轻吟,容器实例启动了!他的应用在隔离的容器中运行起来,映射到宿主机的 5000 端口。当浏览器打开熟悉的界面时,小李感受到前所未有的踏实:在测试员的电脑上运行相同的镜像,立刻就生成了一个独立容器,应用秒开即用。原本需要复杂部署的外卖系统,现在犹如被装进集装箱的移动厨房,“5秒开箱营业”!这样的情景令他忍不住露出一丝久违的笑容——困扰许久的环境问题,如今被一个小小容器轻松拿下。
Docker Compose:一次搞定一桌菜
容器用起来越来越顺手,小李很快发现了新的可能:不仅可以打包应用本身,还能把数据库、缓存等依赖也分别封装进容器。比如将 MySQL 数据库打包成一个镜像、Redis 缓存打包成一个镜像,然后让应用容器与这些容器协同工作。如此一来,每个服务都是一个独立的“菜品”,组合在一起就是一桌丰盛的全席。
可是在开发和测试时,同时管理多个容器变得繁琐:要记住启动顺序、端口映射、容器链接……手工一个个命令启动既枯燥又易错。正在他发愁时,他遇到了 Docker 提供的另一位好帮手:Docker Compose。官方将其定义为“用于定义和运行多容器 Docker 应用的工具”,通过一份YML配置文件,把应用需要的所有服务定义好,然后一条命令即可根据配置启动全部服务。这听起来像极了乐队的指挥:谱子(YAML 文件)写好后,只要指挥棒一挥,乐手(各容器)就各就各位开始演奏。
小李尝试编写一个简单的 docker-compose.yml 来编排他的应用容器和数据库容器:
version: '3'
services:
web:
image: myapp:v1 # 使用刚做好的应用镜像
ports:
- "5000:5000" # 映射端口
depends_on:
- db # 等待 db 服务先就绪
db:
image: mysql:5.7 # MySQL 官方镜像
environment:
- MYSQL_ROOT_PASSWORD=example通过 Compose,他将应用(web)和数据库(db)两个服务的配置写在一处:需要用哪个镜像、开放哪些端口、服务间依赖关系一目了然。接着他运行命令:
docker-compose up -d奇迹再次发生——Compose 自动拉起两个容器,数据库容器先启动,紧接着应用容器也运行起来并成功连接到了数据库。一系列繁琐的操作被 Compose 优雅地整合在一起,让小李有种“一键启动全家桶”的畅快。
他想起以前每次部署一套测试环境,要安装数据库、配置环境变量、启动应用,像上菜前要在厨房忙个不停。而现在,Compose 仿佛一名经验丰富的厨师长,按照菜单一下子备齐了所有菜肴:应用服务器、数据库、缓存……各司其职却又协同上桌。小李望着屏幕上一串绿色的运行状态,恍惚觉得这些容器仿佛有了生命,各自跳动的日志正是它们沟通的语言。
Docker 和容器技术已经初步缓解了他对宕机的焦虑:环境统一了,部署加速了,多服务协作也更从容了。然而,他也清楚单靠一个容器运行的服务仍然脆弱——万一这台运行容器的机器挂了,服务依旧会中断。如何进一步实现服务的高可用,真正做到“自愈”呢? 这时,命运的下一站Kubernetes正向他招手。
初识 Kubernetes:从容器到 Pod 的奇幻之旅
某天下班后,公司运维大佬神秘地拍了拍小李的肩膀:“听说你最近Docker用得飞起,有没有兴趣试试Kubernetes?” 小李早有所闻,Kubernetes(常简称 K8s)据说是容器编排领域的王者,可以管理成百上千的容器,让应用自动扩展、自动恢复,简直像科幻电影里的自主运行系统。
第一次打开 Kubernetes 的文档时,小李有些眼花缭乱:Pod、Deployment、Service、ConfigMap、Namespace……新名词一个接一个扑面而来。不过很快他理清了思路:Kubernetes 本质上是一个用于部署、扩展和管理容器化应用的编排系统。它就像一个智能容器调度中心,专门接管成群的容器,在后台帮你安排好一切。而在 Kubernetes 的世界里,容器并不是直接裸奔的——它们被套上一层特殊的“外衣”,那就是 Pod。
Pod:一艘载着容器的太空舱

小李把 Kubernetes 比喻成浩瀚太空中的一艘母舰,那么 Pod 就是一艘艘小型太空舱。每个 Pod 里可以容纳一到多个紧密协作的容器,共享网络和存储,就像太空舱里的宇航员共享氧气和通讯系统。官方的解释更为直接:Pod 是 Kubernetes 中最小的可部署单元,代表一个应用实例。如果说容器是一个进程的封装,那么 Pod 则是一组进程的编组,一个 Pod 可以包含一个主应用容器加上少量辅助容器,共同完成某项功能。
最常见的情况是 “每个 Pod 包含一个容器”——相当于单人宇航舱;但在需要时,你也可以在一个 Pod 里放入多个容器,让它们共享同一个 IP 地址、使用 localhost 就能彼此通信。这就好比一艘太空舱里有两名宇航员,他们呼吸同样的空气(网络命名空间)、听到同样的广播(IPC命名空间)、看见同样的星空(UTS主机名)。而对于外界来说,这艘舱就是一个整体,无论里面坐了几个人,舱体只有一个对外编号(IP)。Pod 提供了这样一个更高层的抽象,把多个容器捆绑成一个调度单位,让 Kubernetes 可以整体管理它们。
为了更直观地理解,小李编写了自己的第一个 Pod 定义 YAML。比如他希望在集群中运行一个 Nginx 服务,可以创建如下 Pod 清单:
apiVersion: v1
kind: Pod
metadata:
name: my-nginx-pod
spec:
containers:
- name: nginx-container
image: nginx:latest
ports:
- containerPort: 80这份 YAML 清单描述了一个名为 my-nginx-pod 的 Pod,其中运行着一个名为 nginx-container 的容器,使用 Nginx 官方镜像并开放80端口。透过它,小李第一次亲手定义了 Kubernetes 对象。在 Kubernetes 中,一切皆声明式配置:通过 YAML 文件以声明式语法定义资源的目标状态,而不是具体步骤。写好 YAML,执行 kubectl apply -f pod.yaml,Kubernetes 就会按照声明自动创建出目标 Pod。几秒钟后,他查询集群状态,看到了那个熟悉的 Nginx 欢迎页,从 Pod 这个新“太空舱”中呈现出来。
Deployment:自愈的力量
然而,仅仅将应用放进 Pod 并不能彻底消除小李的焦虑。如果某个 Pod 挂掉了怎么办?难道又要半夜爬起来手动重启吗?Kubernetes 给出的答案是 Deployment,它扮演着“集群管理员”的角色,负责维持 Pod 集合的期望状态,并具备自愈能力。
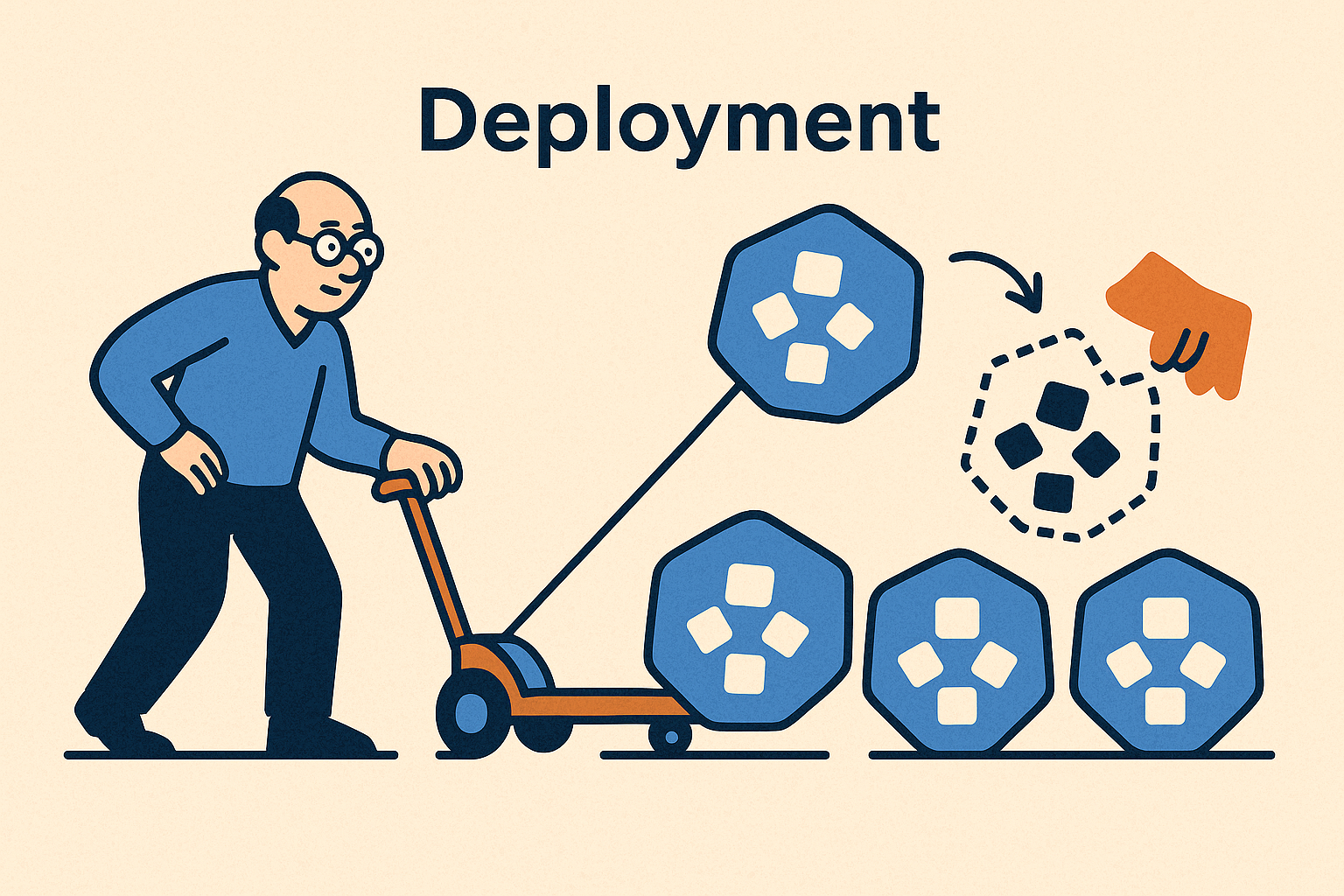
小李了解到,Deployment 可以管理一组 Pod 副本(通常是无状态的应用实例),确保实际运行的 Pod 数量与期望的副本数一致。他设想如果自己的应用跑 3 个副本,即使宕掉一个,剩下两个也能提供服务,而 Kubernetes 会立刻安排一个新的 Pod 补上,从而始终维持 3 个副本在线。这听起来几乎是科幻般的自动愈合:系统自己发现损伤并修补,就像人体的免疫系统自动发现并治愈伤口。
为了验证 Deployment 的魔力,小李编写了一个 Deployment YAML,部署 3 个 my-nginx 副本:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: my-nginx # 选择具有 app=my-nginx 标签的 Pod
template: # Pod 模板
metadata:
labels:
app: my-nginx # 新建 Pod 将自动带上这个标签
spec:
containers:
- name: nginx
image: nginx:1.21
ports:
- containerPort: 80应用这个 Deployment 后,Kubernetes 自动创建了3个 Pod 副本,并将它们调度到不同的节点上运行。小李好奇地删除了其中一个 Pod(模拟故障),几秒钟后他惊喜地发现 Deployment 马上创建了一个新的 Pod 来替补,副本总数又恢复到了3个!Deployment 如同一位尽职的守护者时刻关注着 Pod 的阵容,当发现有“队员”掉线,立即自动拉起一个新的顶上。这一刻,小李内心深处仿佛有什么坚冰融化了。他第一次真切体会到“服务自愈”的意义:系统不再脆弱地依赖人工干预,而是具备了自我修复的肌理。
更棒的是,Deployment 还为应用发布提供了滚动升级能力。比如要更新镜像版本,只需修改 Deployment 的镜像标签,Kubernetes 就会优雅地一次一个替换 Pod,旧版逐步退场,新版平滑接班,整个过程服务不停。仿佛船队在大洋中更换船员,既保持航行又完成了换代。小李意识到,曾经让他焦虑不已的宕机问题,正在演变成一种可被预期和管理的常规事件。在 Kubernetes 的世界里,容器像牛群而非宠物——生老病死是自然规律,重要的是牧场主如何确保整体健康和规模稳定。
Service:让服务被看见
有了 Deployment 帮忙维持3个 Pod 副本,小李的应用不再单点故障。但新的问题随之出现:客户端该如何访问这多个 Pod? Pod 会被动态创建和销毁,每个 Pod 的 IP 地址不固定,直接连 Pod IP 显然不现实。如果客户端盯上某个 Pod IP,结果那个 Pod 重启换了地址,岂不是“人去楼空”?
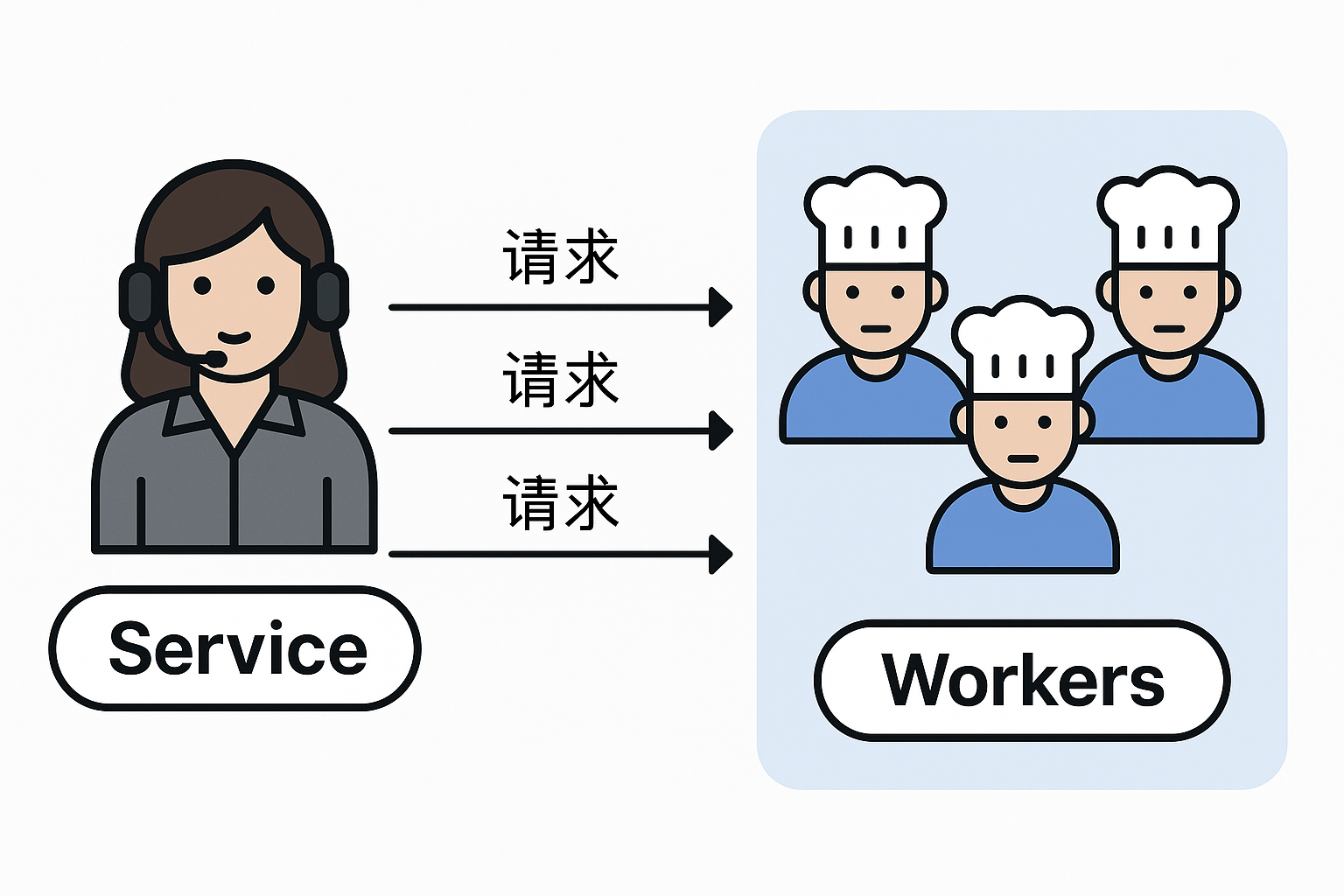
Kubernetes 为此提供了抽象的网络门面——Service。Service 像集群内的一个固定门牌号,无论后面有多少Pod实例,门牌号不变,来访者只要认准门牌就行。根据官方解释,Service通过分配一个集群内部的固定虚拟IP(ClusterIP)来屏蔽后端Pod实例的动态变化,并提供负载均衡。打个比方,Service 就像一家餐厅的总服务台号码,后厨里也许有多位厨师(Pod副本)在同时做菜,但顾客只需拨打服务台电话(Service IP),就会有空闲的厨师接单,上菜过程对顾客来说是透明的。
小李为应用创建了对应的 Service YAML:
apiVersion: v1
kind: Service
metadata:
name: my-nginx-service
spec:
type: ClusterIP
selector:
app: my-nginx # 匹配拥有 app=my-nginx 标签的 Pod,作为后端实例
ports:
- port: 80 # 服务暴露端口
targetPort: 80 # Pod容器端口这个 Service 起名为 my-nginx-service,它通过标签选择器锁定 Deployment 创造的那些 Pod(凡是 app=my-nginx 的 Pod 都自动在后端名单里)。Kubernetes 会为 Service 分配一个虚拟IP,集群内其它组件访问这个IP:80,就会被Service透明地转发给某个实际运行的 Pod 上的80端口处理。这样,不管 Pod 如何增删、IP 如何变化,服务的入口点始终稳定可用。
配置好 Service 后,小李再也不用关心具体请求由哪个 Pod 处理——Service 已经帮他做好了负载均衡。哪怕某个 Pod 临时“请假”了,Service 也会自动把流量导向仍然健在的Pod们。宕机的阴影进一步淡去:用户只看到服务依然健壮在线,根本不会意识到幕后发生过短暂的容器轮换。小李暗自想,Service真像一个尽职的前台接待,无论后面的员工轮班换岗,前台号码始终在线,客户服务不中断。
不仅如此,Kubernetes 内部还自带了服务发现机制,每创建一个 Service,都会自动生成对应的 DNS 名称。因此,应用程序内部可以通过 my-nginx-service.default.svc.cluster.local 这样的域名来访问服务(假设在默认命名空间)。这一切让分布式服务的交互变得像调用本地服务一样简单。
ConfigMap:配置弹性拆分
随着系统愈发稳定,小李开始关注另一个问题:配置管理。以往他经常需要修改应用的配置参数(比如数据库连接字符串、第三方API密钥、应用模式等)。传统做法可能是写在配置文件里或作为环境变量硬编码在容器镜像中。但这不够灵活——改个配置还得重建镜像、多次部署,效率低且风险高。有没有办法把配置和应用解耦,使配置修改不会干扰应用本身呢?
Kubernetes 提供的解决方案是 ConfigMap。官方定义清晰明了:ConfigMap 是一种 API 对象,用来将非机密性的数据以键值对的形式保存。Pod 使用 ConfigMap 时,可以将其中的数据以环境变量、命令行参数或挂载配置文件的方式注入容器。简而言之,ConfigMap 就像一张专门存放配置项清单的小纸条,应用程序运行时再把纸条内容读进去。应用的镜像里不再硬编码环境配置,而是运行时由环境提供,这样镜像可以在不同场景重复使用,而配置可以因环境而异。
小李很快上手创建了一个 ConfigMap,把应用的几个重要参数放了进去。例如,他将应用的模式(开发/生产)和欢迎标语做成一个 ConfigMap:
apiVersion: v1
kind: ConfigMap
metadata:
name: myapp-config
data:
MODE: "production"
WELCOME_MSG: "Hello, Kubernetes!"这个 ConfigMap 取名 myapp-config,里面有两对键值:MODE=production、WELCOME_MSG="Hello, Kubernetes!"。接下来,他更新部署的 Deployment,使 Pod 中的应用容器读取这些配置:
spec:
containers:
- name: myapp
image: myapp:v2
env:
- name: MODE
valueFrom:
configMapKeyRef:
name: myapp-config # 引用 ConfigMap 名称
key: MODE
- name: WELCOME_MSG
valueFrom:
configMapKeyRef:
name: myapp-config
key: WELCOME_MSG通过上述设置,容器启动时会自动收到两个环境变量,其值正是来自 ConfigMap 中的配置数据。应用程序读取环境变量即可获取配置。这种方式将环境配置与容器镜像解耦,使应用配置修改更加弹性便捷。比如需要更改欢迎标语,只要修改 ConfigMap 并让 Pod 加载新的配置即可,无需重新构建镜像。
在小李眼中,ConfigMap 就像餐厅里的每日特价黑板:菜谱(应用镜像)是固定的,但厨师会根据黑板上的配置调整当天的口味和搭配。对于应用而言,ConfigMap 提供了灵活的开关,可以在不同部署环境下快速切换参数,而不必改动应用本身的代码或镜像。这让系统更具适应力:无论是测试环境使用调试开关,还是生产环境接入真实外部服务,都可以通过 ConfigMap 轻松实现。
Namespace:井井有条的容器王国
故事讲到这里,小李已经用上了 Kubernetes 的大部分核心功能,他的服务运行在一个稳定、自愈且易于配置的容器集群中。他终于能在夜深人静时安心地睡去,而不是时时担心服务器会不会突然“出走”。然而,随着团队的协作和项目的增多,如何规划管理大量的资源对象又成为一个新课题。
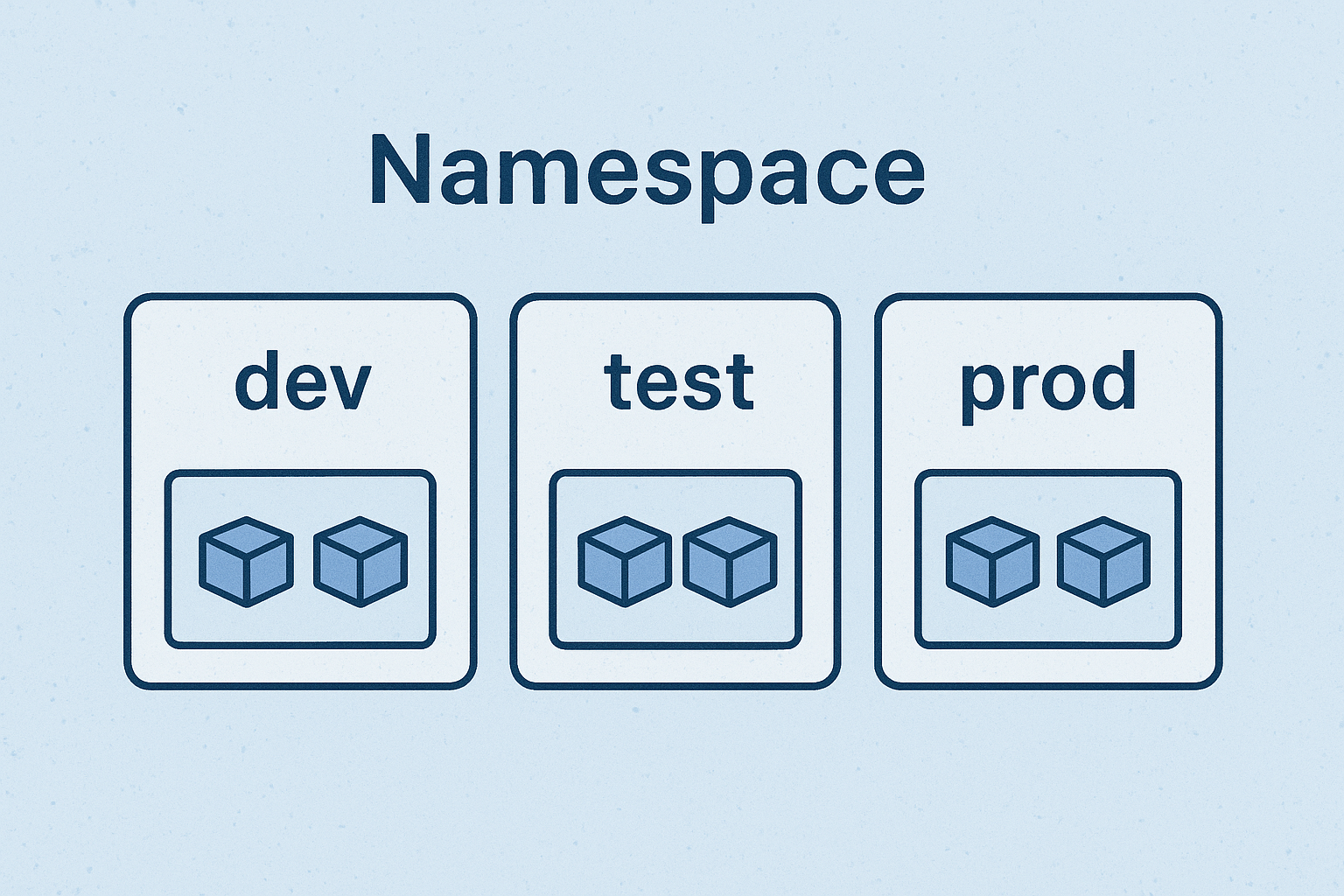
Kubernetes 的答案是 Namespace(命名空间)。Namespace 相当于在同一集群内划分出的多个逻辑上隔离的空间,用于将资源分组和隔离。正如官方所言,K8s 用命名空间将资源隔离开;默认情况下,相同命名空间里的服务可以互相通信,不同命名空间则彼此隔离。可以把 Namespace 想象成一个大型仓库里的不同区域:每个区域有各自的货架和物品标签,互不干扰但井井有条。
小李决定利用 Namespace 将不同环境和项目分开管理。例如,他为测试环境创建了一个 test 命名空间,为生产环境创建了一个 prod 命名空间。这样一来,即使两个环境中有名称相同的 Service 或 Pod(比如都叫 my-nginx-service),也不会冲突——它们分别存在于 test 和 prod 命名空间下,各自成划分。要创建一个命名空间很简单,可以直接在 YAML 中定义:
apiVersion: v1
kind: Namespace
metadata:
name: prod应用后,一个名为 prod 的命名空间就诞生了。接着,小李在部署和 Service 等 YAML 配置中加上 metadata.namespace: prod,即可将资源创建到该命名空间中。同理,测试环境的资源放在 test 命名空间里。Namespace 让集群成为多租户的容器王国:不同团队、不同环境各居其所,既共享同一套集群的物理资源,又在逻辑上隔离,互不侵犯。
有了 Namespace,小李甚至可以放心地让开发、测试人员在同一套集群上各玩各的“沙盒”,而不用担心互相踩到对方的资源。命名空间之隔,恍如平行宇宙,每个宇宙里的命名都独立存在。例如,开发人员在 dev 名空间中调试新版本服务,不会影响 prod 名空间中稳定运行的旧版本服务。Kubernetes 世界因此变得秩序井然,也为未来大规模扩展打下基础。
尾声:自愈之光与心态蜕变
终于,小李迎来了久违的平静夜晚。某个深夜,当集群中的一个节点意外宕机时,Kubernetes 自动将受影响的Pod调度到其他节点,服务丝毫没有间断。而此刻的小李并不知道这次故障,因为他正睡得香甜——系统在默默自我修复,仿佛深夜里的城市自动调节着红绿灯,让交通继续顺畅。翌日清晨查看日志,他才发现夜里发生过波澜,但一切早已恢复正常。

他站在窗前,回想起这段从“宕机焦虑”走向“自愈架构”的心路历程,不禁露出了笑容。那个曾经杯弓蛇影、一崩溃就神经紧绷的自己,随着Docker和Kubernetes的引入,心态发生了奇妙的转变。从前他把服务器当作需要精心照料的宠物,生怕它生病;现在他把容器当作可以批量放养的牲畜,坏掉一两个不影响整个牧场安宁。正所谓“不破不立”,服务的健壮不在于永不失败,而在于能否快速地从失败中恢复。Docker 和 Kubernetes 教会他的,正是这一点。
窗外初升的阳光洒在键盘上,小李觉得那些冰冷的技术名词背后竟透出一丝温暖和哲思:容器让应用栖息其上,彼此独立却共享内核;编排系统赋予集群生命,自愈扩展,周而复始。这不正如现实世界的万物运行规律?个体终有凋零,但整体生生不息。小李深吸一口气,仿佛嗅到了咖啡飘香中混杂的一缕代码的味道。
他打开了团队通讯软件,在技术分享频道里写下:“昨夜做了一个梦,梦见我的系统变成了一座永不打烊的城市,每一次灯火熄灭都能自行重新点亮。” 这或许就是他与 Docker、Kubernetes 的故事馈赠——在追求高可用的征途上,他收获的不仅是技术的升级,还有对系统架构更深层次的理解与敬畏。从此宕机不再是梦魇,而更像是提醒他精进的良师;自愈不再只是愿景,而成为他掌控的现实。
服务自愈之光已然点亮,小李合上笔记本,踏出了办公室的大门。朝阳映照下,他的背影少了几分疲惫,多了一份笃定。今后的日子里,无论面对何种系统挑战,他都将坦然一笑:“交给容器,交给 Kubernetes 吧。”

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐

 25
25 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)