MGeo与dify集成指南:打造可视化地址匹配工作流
MGeo 并非简单的字符串编辑距离计算工具,而是采用BERT-like 结构 + 对比学习(Contrastive Learning)输入:两个中文地址文本(如“杭州市西湖区文三路159号” vs “杭州西湖文三路159”)输出:[0,1] 区间内的相似度分数,数值越高表示越可能是同一地点其优势在于:- ✅ 能理解“省市区镇村”层级结构- ✅ 对同义词(“路”≈“道”)、简称(“浙大”≈“浙江大学
MGeo与Dify集成指南:打造可视化地址匹配工作流
引言:为什么需要智能地址匹配?
在电商、物流、城市治理等场景中,地址数据的标准化与实体对齐是构建高质量地理信息系统的前提。然而,中文地址存在大量别名、缩写、错字和结构差异(如“北京市朝阳区” vs “朝阳, 北京”),传统模糊匹配方法准确率低、维护成本高。
MGeo 是阿里云开源的一款专注于中文地址相似度识别的深度学习模型,基于大规模真实地址语料训练,在复杂变体、跨区域表达上表现出色。结合 Dify 这一低代码 AI 应用开发平台,我们可以快速搭建一个可视化、可交互的地址匹配工作流系统,实现从原始地址输入到相似度打分再到结果展示的全流程自动化。
本文将带你完成 MGeo 本地部署 + Dify 集成调用的完整实践,最终形成一个可通过 Web 界面操作的地址匹配工具。
一、MGeo 模型简介:专为中文地址设计的语义匹配引擎
核心能力解析
MGeo 并非简单的字符串编辑距离计算工具,而是采用 BERT-like 结构 + 对比学习(Contrastive Learning) 的深度语义模型:
- 输入:两个中文地址文本(如“杭州市西湖区文三路159号” vs “杭州西湖文三路159”)
- 输出:[0,1] 区间内的相似度分数,数值越高表示越可能是同一地点
其优势在于: - ✅ 能理解“省市区镇村”层级结构 - ✅ 对同义词(“路”≈“道”)、简称(“浙大”≈“浙江大学”)敏感 - ✅ 支持噪声容忍(错别字、多余描述)
技术类比:就像两个人看两个地址描述后判断是否指向同一个地方,MGeo 就是经过“千万次练习”的专家。
二、环境准备与 MGeo 本地部署
本节指导你在具备 NVIDIA 4090D 显卡的服务器上完成 MGeo 推理环境搭建。
1. 启动容器并进入 Jupyter 环境
假设你已通过 Docker 或 Kubernetes 成功拉取包含 MGeo 镜像的运行环境:
# 示例:启动容器(具体命令依实际部署方式而定)
docker run -it --gpus all -p 8888:8888 mgeo:v1.0
打开浏览器访问 http://<your-server-ip>:8888,进入 Jupyter Lab 页面。
2. 激活 Conda 环境
在终端中执行:
conda activate py37testmaas
该环境预装了 PyTorch、Transformers、FastAPI 等依赖库,支持 GPU 加速推理。
3. 复制推理脚本至工作区(推荐)
便于后续修改和调试:
cp /root/推理.py /root/workspace
现在你可以在 Jupyter 中打开 /root/workspace/推理.py 进行编辑。
三、MGeo 推理脚本详解
以下是 推理.py 的核心代码片段及其解析:
# 推理.py
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# 加载 tokenizer 和模型
model_path = "/root/mgeo-model" # 假设模型文件存放于此
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForSequenceClassification.from_pretrained(model_path)
# 移动到 GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
def compute_similarity(addr1: str, addr2: str) -> float:
"""计算两个地址的相似度"""
inputs = tokenizer(
addr1, addr2,
padding=True,
truncation=True,
max_length=128,
return_tensors="pt"
).to(device)
with torch.no_grad():
outputs = model(**inputs)
probs = torch.nn.functional.softmax(outputs.logits, dim=-1)
similarity_score = probs[0][1].item() # 假设 label=1 表示相似
return round(similarity_score, 4)
# 测试示例
if __name__ == "__main__":
a1 = "北京市海淀区中关村大街1号"
a2 = "北京海淀中关村大街1号海龙大厦"
score = compute_similarity(a1, a2)
print(f"相似度: {score}")
关键点说明:
| 组件 | 作用 | |------|------| | AutoTokenizer | 将地址对编码为 BERT 可处理的 token ID 序列 | | max_length=128 | 地址通常较短,128 足够覆盖绝大多数情况 | | softmax(logits) | 将分类输出转为概率分布(0:不相似, 1:相似) | | probs[0][1] | 提取“相似”类别的置信度作为最终得分 |
提示:若需批量处理,可使用
batch_encode_plus实现向量化推理,提升吞吐量。
四、封装为 REST API 服务
为了让 Dify 能调用 MGeo,我们需要将其封装为 HTTP 接口。
创建 app.py
# app.py
from fastapi import FastAPI
from pydantic import BaseModel
import uvicorn
app = FastAPI(title="MGeo Address Matcher")
class MatchRequest(BaseModel):
address1: str
address2: str
@app.post("/match")
def match_addresses(req: MatchRequest):
score = compute_similarity(req.address1, req.address2)
return {"similarity": score}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
启动服务
python app.py
此时访问 http://localhost:8000/docs 可查看自动生成的 Swagger 文档,接口路径为 POST /match。
五、Dify 工作流设计:构建可视化地址匹配应用
Dify 是一个可视化编排 AI 工作流的平台,支持连接外部 API、LLM、数据库等组件。
步骤 1:创建新应用
登录 Dify 控制台 → 新建“空白应用” → 类型选择“对话型”或“Agent”。
步骤 2:添加“HTTP 请求”节点
我们将使用 Dify 的 External Tool(HTTP Request) 功能调用本地 MGeo 服务。
配置参数如下:
| 字段 | 值 | |------|----| | 名称 | Address Similarity Checker | | URL | http://<server-ip>:8000/match | | 方法 | POST | | Headers | Content-Type: application/json | | Body | {"address1": "{{input1}}", "address2": "{{input2}}"} |
注意:确保 Dify 所在网络能访问你的 MGeo 服务器 IP。
步骤 3:设计用户交互流程
使用 Dify 的 Prompt 编排器引导用户输入两段地址:
请提供需要比对的两个地址:
第一地址:{{#sys.query#}}
第二地址:{{#tool.Address Similarity Checker.input2#}}
正在为您计算相似度...
→ 相似度得分:{{#tool.Address Similarity Checker.similarity#}}
📌 判定建议:
{% if tool['Address Similarity Checker']['similarity'] > 0.8 %}
这两个地址极有可能指向同一位置。
{% elif tool['Address Similarity Checker']['similarity'] > 0.6 %}
存在一定相似性,建议人工复核。
{% else %}
基本可以判定为不同地址。
{% endif %}
步骤 4:发布为 Web 应用
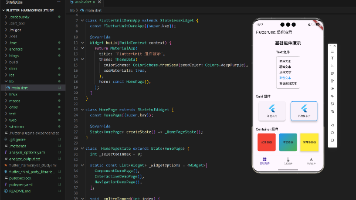
点击“发布”,生成可分享的链接或嵌入 iframe 到内部系统。最终效果如下:
【用户输入】
地址A:上海市浦东新区张江高科技园区科苑路88号
地址B:上海张江科苑路88号腾讯大厦
【系统输出】
→ 相似度得分:0.9321
📌 判定建议:这两个地址极有可能指向同一位置。
六、进阶优化建议
1. 性能优化:批处理与缓存
对于高频查询场景,可在 MGeo 层增加 Redis 缓存:
import hashlib
cache = {}
def get_cache_key(a1, a2):
return hashlib.md5(f"{a1}_{a2}".encode()).hexdigest()
def cached_similarity(a1, a2):
key = get_cache_key(a1, a2)
if key in cache:
return cache[key]
score = compute_similarity(a1, a2)
cache[key] = score
return score
2. 安全加固:API 认证
生产环境中应为 FastAPI 添加 JWT 或 Token 验证:
from fastapi.security import APIKeyHeader
api_key_header = APIKeyHeader(name="X-API-Key")
@app.post("/match")
def match_addresses(req: MatchRequest, api_key: str = Depends(api_key_header)):
if api_key != "your-secret-token":
raise HTTPException(status_code=403, detail="Invalid API Key")
...
3. 错误兜底机制
当 MGeo 服务不可用时,Dify 可配置 fallback 策略:
- 使用轻量级规则引擎(如 Levenshtein 距离)临时替代
- 返回“服务暂不可用,请稍后再试”
七、典型应用场景
| 场景 | 价值 | |------|------| | 电商平台订单清洗 | 合并同一用户的重复收货地址,提升配送效率 | | 政务数据治理 | 对接多部门地址库,实现“一地一码”统一管理 | | 地图 POI 合并 | 自动识别“肯德基(西单店)”与“肯德基北京西单餐厅”为同一实体 | | 反欺诈风控 | 检测虚假注册中使用的相似但不同的地址伪装行为 |
总结:构建可持续演进的地址智能体系
通过本次实践,我们完成了 MGeo + Dify 的端到端集成,实现了:
✅ 中文地址语义级精准匹配
✅ 可视化交互界面快速交付
✅ 模块化架构便于扩展维护
这套方案不仅适用于当前需求,更具备良好的延展性——未来可接入更多 NLP 模型(如地址结构化解析、归属地预测),逐步构建企业级地理语义理解中台。
最佳实践建议: 1. 在正式上线前,使用真实业务数据集进行 A/B 测试,验证 MGeo 相比旧方案的准确率提升; 2. 将 Dify 应用嵌入现有 CRM/ERP 系统,作为标准组件供业务人员直接调用; 3. 定期收集人工复核反馈,用于迭代优化模型阈值或训练新版本。
立即动手部署,让你的数据地址“看得懂、连得通、用得好”。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐

 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)