

对于许多刚接触大数据领域的朋友来说,Apache Hadoop无疑是一个既响亮又有些令人生畏的名字。它那强大的分布式处理能力让人向往,但传统的Hadoop集群搭建和配置过程却常常因为其复杂性而劝退了不少初学者。幸运的是,随着容器化技术的兴起,我们现在有了更简单、更快捷的方式来体验Hadoop——那就是使用Docker!
这篇博文将手把手带你了解如何在你的机器上使用Docker和Docker Compose快速部署一个Hadoop集群,并运行一个简单的MapReduce任务。无需复杂的环境配置,让我们开始这段轻松的大数据之旅吧!
你需要了解的基础概念
在开始之前,我们先快速了解几个核心概念:
- Hadoop: 一个开源框架,用于分布式存储和分布式处理海量数据集。其核心组件包括HDFS(用于存储)和YARN(用于资源管理和作业调度),以及MapReduce(用于数据处理)。
- Docker: 一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux机器或Windows机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。
- Docker镜像 (Image): 一个轻量级、可执行的独立软件包,包含运行某个软件所需的一切:代码、运行时、库、环境变量和配置文件。
- Docker容器 (Container): 镜像是模板,容器是镜像的运行实例。你可以创建、启动、停止、移动或删除容器。
- Docker Compose: 一个用于定义和运行多容器Docker应用程序的工具。通过一个YAML文件来配置应用服务,然后使用一个命令,就可以从配置中创建并启动所有服务。
- Namenode: Hadoop HDFS(Hadoop分布式文件系统)中的主节点,负责管理文件系统的命名空间(目录树、文件元数据)和控制客户端对文件的访问。
- Datanode: Hadoop HDFS中的从节点,负责存储实际的数据块。
- ResourceManager: Hadoop YARN(Yet Another Resource Negotiator)中的主节点,负责集群中所有资源的统一管理和调度。
- MapReduce: Hadoop中的一个编程模型和计算框架,用于大规模数据集的并行处理。它包含Map(映射)和Reduce(规约)两个主要阶段。
准备工作
- 安装Docker: 请确保你的系统已经安装了Docker。具体安装方法可以参考Docker官方文档。
- 安装Docker Compose: Docker Compose通常随Docker Desktop (Windows/Mac) 一起安装。对于Linux系统,你可能需要单独安装。确保它是可用的。
实战步骤
第一步:拉取Hadoop的Docker镜像
我们首先需要一个包含Hadoop环境的Docker镜像。这里我们假设使用一个预先配置好的Hadoop镜像,例如 bde2020/hadoop-base:2.0.0-hadoop3.2.1-java8 或类似的公共镜像。在你的终端中执行:
Bash
小提示:Docker Hub (hub.docker.com) 上有许多预构建的Hadoop镜像可供选择。选择一个下载量大、更新及时的通常比较可靠。

第二步:确保Docker Compose可用并准备配置文件
Docker Compose使用一个名为 docker-compose.yml 的YAML文件来定义服务、网络和卷。你需要一个配置好了Hadoop集群(包括Namenode, Datanode, ResourceManager等服务)的 docker-compose.yml 文件。
很多Hadoop Docker项目会在Git仓库中提供这个文件。如果你的 docker-compose.yml 文件是从Git仓库获取的,你需要先安装Git。
如果Git不可用,在基于RPM的Linux发行版(如CentOS)上,可以使用以下命令安装:
Bash
然后,克隆包含 docker-compose.yml 文件的Git仓库。假设仓库地址为 https://github.com/example/hadoop-docker-compose.git:
Bash
关键点:
docker-compose.yml文件是核心。它定义了Hadoop集群的架构,例如:YAML
version: '3'
services: namenode: image: your-hadoop-namenode-image ports: - "9870:9870" # Namenode Web UI # ...其他配置 datanode: image: your-hadoop-datanode-image # ...其他配置 resourcemanager: image: your-hadoop-resourcemanager-image ports: - "8088:8088" # ResourceManager Web UI # ...其他配置
你需要根据你实际使用的 `docker-compose.yml` 文件内容来理解服务是如何配置的。


第三步:启动Hadoop集群
有了 docker-compose.yml 文件后,在包含该文件的目录中打开终端,运行以下命令来启动Hadoop集群:
Bash
up: 创建并启动容器。-d: 表示在后台(detached mode)运行容器。
第四步:查看Docker容器和访问Hadoop服务
等待命令执行完毕,几分钟后,你的Hadoop集群就应该运行起来了。我们可以通过以下命令查看正在运行的Docker容器:
Bash
你应该能看到类似 namenode, datanode, resourcemanager 等容器正在运行。

进入Namenode容器并查看HDFS
我们可以进入Namenode容器的shell环境来执行Hadoop相关的命令:
Bash
docker exec: 在运行的容器中执行命令。-it: 分配一个伪TTY并保持STDIN打开,允许交互。namenode: 这是你在docker-compose.yml中定义的Namenode服务的名称(或者是容器的实际名称/ID)。/bin/bash: 启动bash shell。
进入shell后,尝试查看HDFS的根目录内容:
Bash
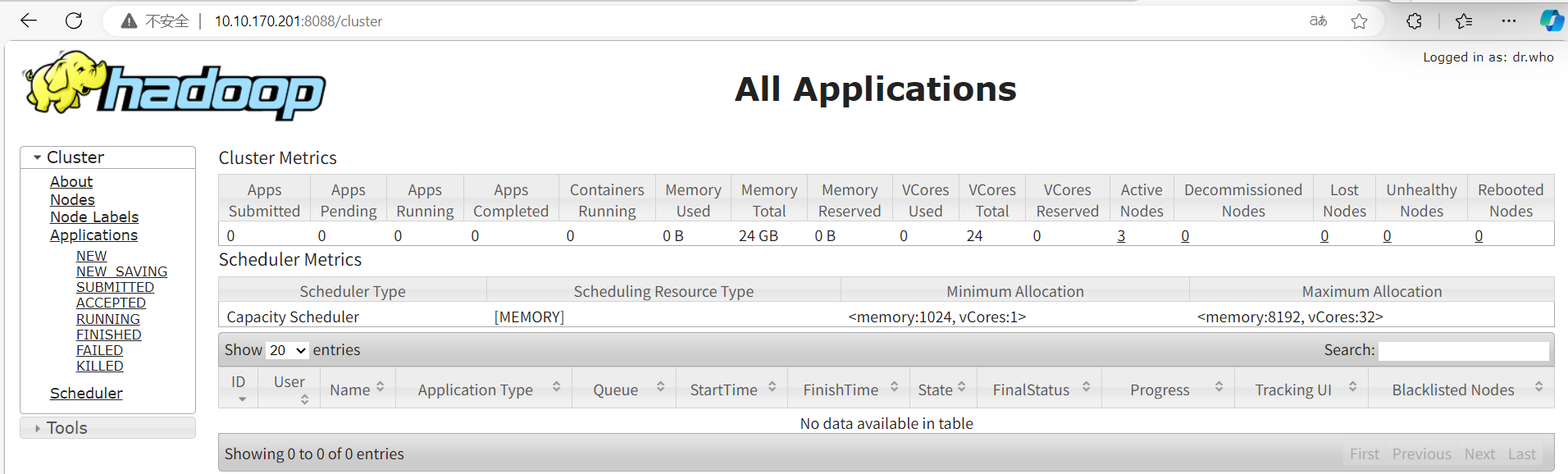
通过浏览器访问Hadoop Web UI
Hadoop通常会暴露Web界面,方便我们监控集群状态:
- Namenode UI: 通常是
http://localhost:9870(具体端口取决于docker-compose.yml中的端口映射)。 - ResourceManager UI: 通常是
http://localhost:8088(具体端口取决于docker-compose.yml中的端口映射)。
打开你的浏览器访问这些地址,你应该能看到Hadoop集群的相关信息。
第五步:下载MapReduce任务包文件 (示例)
为了运行一个MapReduce任务,我们通常需要一个包含任务逻辑的JAR(Java Archive)文件。Hadoop发行版通常自带一些示例程序。假设我们要使用 hadoop-mapreduce-examples.jar。
如果你的Docker镜像中不包含这个文件,或者你想使用特定的JAR,你需要先下载它。
Bash
然后,将这个JAR文件传输到正在运行的Namenode容器中。假设你已将JAR文件下载到当前目录,并且Namenode容器内的Hadoop安装路径是 /opt/hadoop/:
Bash
第六步:创建数据处理的样本文件
我们需要一些数据来让MapReduce任务处理。在你的宿主机上创建一个简单的文本文件,例如 input1.txt:
你可以随意添加更多内容。
第七步:将数据文件传入到容器中
将创建的 input1.txt 文件也复制到Namenode容器中,例如放到 /tmp/ 目录下:
Bash

第八步:将容器中的样本文件上传到HDFS目录中
现在,我们需要将Namenode容器中的 /tmp/input1.txt 文件上传到HDFS中,以便MapReduce任务可以访问它。
首先,在Namenode容器的shell中(如果你退出了,请重新 docker exec -it namenode /bin/bash),在HDFS上创建一个输入目录:
Bash
然后,将 /tmp/input1.txt 上传到HDFS的 /user/root/input 目录中:
Bash
你可以通过以下命令验证文件是否上传成功:
Bash
第九步:运行MapReduce任务 (WordCount示例)
一切准备就绪!现在我们可以在Namenode容器内运行一个经典的WordCount(单词计数)MapReduce任务。这个任务会统计输入文件中每个单词出现的次数。
Bash
hadoop jar <jar_file>: 运行JAR文件中的Hadoop作业。wordcount: 指定要运行的程序(WordCount)。/user/root/input: HDFS上的输入数据路径。/user/root/output: HDFS上用于存放结果的输出路径(这个目录不能预先存在,Hadoop会自动创建)。
任务运行可能需要一些时间。成功后,你可以在HDFS的 /user/root/output 目录中查看到结果:
Bash
你应该能看到类似这样的输出:
第十步:关闭并清理Docker Compose环境
当你完成实验后,可以使用以下命令来停止并移除由 docker-compose.yml 定义的所有容器、网络和卷(如果你定义了匿名卷):
Bash
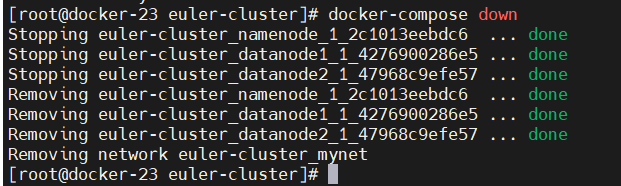
第十一步:验证容器已关闭
再次运行 docker container ls,你会发现之前运行的Hadoop相关容器都已经被关闭和移除了。
Bash
输出应该为空,或者不包含Hadoop集群的容器了。
总结与展望
恭喜你!通过本教程,你已经成功地使用Docker和Docker Compose快速搭建了一个本地的Hadoop集群,并且运行了一个基础的MapReduce作业。这展示了容器化技术在简化复杂环境部署方面的强大能力。
回顾一下,我们完成了:
- 了解了Docker和Hadoop的基础概念。
- 使用
docker-compose启动了一个多节点的Hadoop集群。 - 与运行中的Hadoop容器进行了交互。
- 将数据上传到HDFS。
- 成功运行了一个MapReduce示例任务。
- 学习了如何清理环境。
下一步学习建议:
- 深入理解HDFS和YARN: 探索它们的架构和更多命令。
- 编写自己的MapReduce程序: 尝试用Java或其他语言(如Python通过Hadoop Streaming)编写更复杂的MapReduce应用。
- 探索Hadoop生态系统: 了解Hive(数据仓库)、HBase(NoSQL数据库)、Spark(更快的通用处理引擎)等与Hadoop集成的项目。
- 学习更多Docker和Docker Compose知识: 例如,如何编写自己的
Dockerfile来定制镜像,以及docker-compose.yml的更多高级配置。
使用Docker搭建Hadoop仅仅是大数据学习的开始。希望这篇博文能为你打开一扇门,激发你探索更多大数据技术的兴趣!
如果你在实践过程中遇到任何问题,或者有任何心得体会,欢迎在下方留言交流




 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)