老码农和你一起学AI系列:序列模型基础
本文介绍了序列数据处理的核心模型RNN和LSTM的原理与应用。RNN通过循环结构处理序列依赖关系,但存在长期记忆缺失问题。LSTM引入门控机制和细胞状态,有效解决了这一局限。文章通过字符级文本生成实战,展示了如何用LSTM模型学习文本特征并生成新内容,探讨了温度参数对生成效果的影响,并提供了模型优化建议。最后总结了RNN与LSTM的差异、文本生成逻辑及序列模型的其他应用场景,为处理序列数据提供了实
在人工智能处理的各类数据中,“序列数据”(如文本、语音、时间序列)占据了重要地位 —— 这类数据的核心特点是 “前后元素存在依赖关系”(比如文本中 “今天天气” 后更可能接 “晴朗” 而非 “跑步”,股票价格的今日走势与昨日相关)。传统的 CNN 擅长处理空间关联数据(如图像),却无法捕捉序列的时序依赖;而序列模型(以 RNN、LSTM 为代表)通过 “循环结构” 让模型能 “记住” 历史信息,成为处理序列数据的核心工具。本文将从 RNN 的基础原理出发,解析 LSTM 如何突破 RNN 的局限,最后通过字符级文本生成实战,带你掌握序列模型的应用方法。

一、RNN 原理
循环神经网络(Recurrent Neural Network, RNN)的核心设计是 “在网络中加入循环结构”,让神经元的输出不仅依赖当前输入,还依赖上一时刻的 “隐藏状态”(可理解为模型的 “短期记忆”)。这种结构使 RNN 能自然处理变长的序列数据,成为早期序列任务(如文本分类、简单语言模型)的首选模型。
1. RNN 的基础结构与工作流程
(1)核心结构:循环单元与隐藏状态
RNN 的基本单元(循环单元)包含两个输入和两个输出:
- 输入:当前时刻的序列元素(如文本中的一个词向量x_t)、上一时刻的隐藏状态(h_{t-1},记录历史信息);
- 输出:当前时刻的隐藏状态(h_t,更新后的记忆)、当前时刻的预测结果(y_t,如文本分类的类别概率)。
其结构可简化为 “展开图”(按时间步展开):假设处理一个长度为 3 的序列(x_1→x_2→x_3),展开后每个时间步都有一个相同的循环单元,隐藏状态h在时间步间传递,形成 “记忆链”。
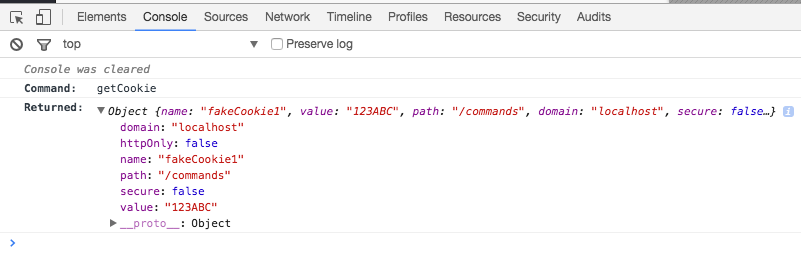 (左:RNN 循环结构;右:时间步展开后的结构,W_hh为隐藏状态更新权重,W_xh为输入权重)
(左:RNN 循环结构;右:时间步展开后的结构,W_hh为隐藏状态更新权重,W_xh为输入权重)
(2)数学原理:隐藏状态的更新逻辑
RNN 的核心是隐藏状态h_t的更新公式,本质是 “当前输入与历史记忆的线性组合 + 非线性激活”:
- 线性组合:将当前输入x_t与上一隐藏状态h_{t-1}通过权重矩阵组合:
z_t = W_xh · x_t + W_hh · h_{t-1} + b
(W_xh是输入到隐藏状态的权重,W_hh是隐藏状态到自身的权重,b是偏置);
- 非线性激活:通过 tanh 或 sigmoid 激活函数引入非线性,得到当前隐藏状态h_t:
h_t = tanh(z_t)
(tanh 是 RNN 常用激活函数,输出范围 - 1~1,能更好地传递正负向信息);
- 预测输出:根据隐藏状态h_t计算当前时刻的预测y_t(如分类任务用 Softmax):
y_t = Softmax(W_hy · h_t + b_y)。
(3)适用场景与局限
- 适用场景:短序列任务,如短文本情感分析(句子长度 < 20)、简单时间序列预测(如未来 1 小时气温预测);
- 核心局限:长期依赖问题:当序列过长(如文本长度 > 50),隐藏状态h_t在传递过程中会因 “梯度消失” 或 “梯度爆炸” 丢失历史信息 —— 比如处理 “我昨天去了北京,那里的____很美味”,RNN 无法通过 “北京” 这个早期信息,推断出空格处应填 “烤鸭”(长期依赖),只能依赖近期信息(如 “那里的”),导致模型无法捕捉长距离关联。
二、LSTM 原理
为解决 RNN 的长期依赖问题,研究者在 1997 年提出了 LSTM(Long Short-Term Memory,长短期记忆网络)。其核心创新是门控机制—— 通过 “遗忘门”“输入门”“输出门” 三个可学习的 “阀门”,自主控制历史信息的 “保留”“更新”“输出”,让模型能有效记住长序列中的关键信息。
1. LSTM 的核心结构
LSTM 的循环单元比 RNN 更复杂,引入了 “细胞状态(Cell State)” 作为 “长期记忆载体”,配合三个门控单元实现记忆的精准调控,结构展开后如下:
(1)细胞状态(Cell State)
细胞状态C_t是 LSTM 的 “核心记忆通道”,相当于一条 “传送带”—— 信息在上面缓慢传递,仅通过门控单元进行少量修改(而非像 RNN 那样每次都剧烈更新),这是 LSTM 能保留长期信息的关键。
- 初始状态C_0通常设为全 0 向量;
- 每个时间步,细胞状态C_t通过 “遗忘门” 删除无用信息,通过 “输入门” 添加新信息,实现平稳更新。
(2)三大门控单元:控制记忆的 “阀门”
三个门控单元均通过 “sigmoid 激活函数” 输出 0~1 的概率值(0 表示完全关闭,1 表示完全打开),自主决定信息的流通比例:
① 遗忘门(Forget Gate)
- 作用:筛选细胞状态C_{t-1}中的无用信息(如处理文本时,忘记与当前主题无关的早期词汇);
- 计算逻辑:结合当前输入x_t和上一隐藏状态h_{t-1},通过 sigmoid 输出遗忘概率f_t:
f_t = σ(W_f · [h_{t-1}, x_t] + b_f)
([h_{t-1}, x_t]表示将两个向量拼接,σ为 sigmoid 函数);
- 记忆筛选:用f_t与上一细胞状态C_{t-1}逐元素相乘,概率接近 0 的信息被丢弃:
C_t' = f_t ⊙ C_{t-1}(⊙表示逐元素乘法)。
② 输入门(Input Gate):决定 “添加哪些新信息”
- 作用:筛选当前输入x_t中的有效信息,更新到细胞状态中;
- 计算逻辑:分两步实现:
- 入门概率i_t:通过 sigmoid 决定哪些新信息被保留:
i_t = σ(W_i · [h_{t-1}, x_t] + b_i);
候选记忆~C_t:通过 tanh 生成当前输入的候选信息(范围 - 1~1):
~C_t = tanh(W_C · [h_{t-1}, x_t] + b_C);
信息更新:将候选记忆与输入门概率相乘,得到待添加的新信息,叠加到筛选后的历史记忆上:
C_t = C_t' + i_t ⊙ ~C_t。
③ 输出门(Output Gate)
- 作用:筛选细胞状态C_t中的信息,生成当前时刻的隐藏状态h_t(用于后续预测或传递到下一时刻);
- 计算逻辑:分两步实现:
- 输出门概率o_t:通过 sigmoid 决定哪些记忆被输出:
o_t = σ(W_o · [h_{t-1}, x_t] + b_o);
隐藏状态生成:将细胞状态C_t通过 tanh 压缩到 - 1~1,再与输出门概率相乘,得到h_t:
h_t = o_t ⊙ tanh(C_t);
预测输出:与 RNN 类似,根据h_t计算y_t:
y_t = Softmax(W_hy · h_t + b_y)。
2. LSTM 的核心优势
- 梯度传播更稳定:细胞状态C_t的更新是 “加法操作”(而非 RNN 的乘法),梯度在反向传播时不易衰减(避免梯度消失);同时,门控单元的 sigmoid 梯度在 0~1 之间,可进一步抑制梯度爆炸;
- 记忆控制更精准:通过遗忘门主动丢弃无用信息(如文本中的虚词),输入门主动保留关键信息(如 “北京”“烤鸭”),输出门按需输出记忆,让模型能在长序列中精准捕捉长期依赖。
3. LSTM 的变种
为简化 LSTM 的结构,研究者在 2014 年提出了 GRU(Gated Recurrent Unit),将 “遗忘门” 和 “输入门” 合并为 “更新门”,去掉了细胞状态,仅保留隐藏状态,在降低计算复杂度的同时,保持了接近 LSTM 的性能,成为短序列任务的常用选择。
三、LSTM 文本生成实战
文本生成是序列模型的经典应用场景,“字符级语言模型” 的核心思路是:让模型学习 “给定前 N 个字符,预测下一个字符的概率分布”,通过不断采样下一个字符,生成连贯的文本(如生成诗歌、小说片段)。下面将用 Keras 实现一个基于 LSTM 的字符级文本生成模型,以《唐诗三百首》文本为例,生成新的诗句。
1. 实战准备:数据预处理
(1)数据加载与查看
首先加载文本数据(此处用《唐诗三百首》简化文本,实际可替换为小说、诗歌等任意文本):
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Embedding
from tensorflow.keras.preprocessing.sequence import pad_sequences
import random
import sys
# 加载文本(此处为简化示例,实际可读取txt文件)
text = """床前明月光,疑是地上霜。举头望明月,低头思故乡。
春眠不觉晓,处处闻啼鸟。夜来风雨声,花落知多少。
白日依山尽,黄河入海流。欲穷千里目,更上一层楼。"""
# 查看文本基本信息
print(f"文本总长度:{len(text)}")
print(f"文本前100字符:{text[:100]}")(2)字符映射:构建 “字符→索引” 字典
字符级模型需将每个字符转换为整数索引(计算机无法直接处理字符):
# 提取文本中所有唯一字符
chars = sorted(list(set(text)))
char_to_idx = {char: idx for idx, char in enumerate(chars)} # 字符→索引
idx_to_char = {idx: char for idx, char in enumerate(chars)} # 索引→字符
vocab_size = len(chars) # 字符表大小(词汇量)
print(f"字符表大小:{vocab_size}")
print(f"字符→索引示例:{list(char_to_idx.items())[:10]}")(3)构建训练数据
将文本切分为 “输入序列(sequence)” 和 “目标字符(target)”—— 例如输入 “床前明”,目标是 “月”;输入 “前明月”,目标是 “光”:
max_len = 40 # 输入序列长度(用前40个字符预测下一个)
step = 3 # 步长(每3个字符取一个序列,避免冗余)
sequences = [] # 输入序列列表
targets = [] # 目标字符列表
# 遍历文本生成训练数据
for i in range(0, len(text) - max_len, step):
seq = text[i: i + max_len] # 输入序列(长度40)
target = text[i + max_len] # 目标字符(序列后的第一个字符)
sequences.append([char_to_idx[c] for c in seq]) # 序列转为索引
targets.append(char_to_idx[target]) # 目标转为索引
# 查看训练数据形状
print(f"输入序列数量:{len(sequences)}")
print(f"输入序列示例(索引):{sequences[0]}")
print(f"对应目标字符(索引):{targets[0]} → 字符:{idx_to_char[targets[0]]}")(4)数据格式转换
LSTM 的输入格式为(样本数, 序列长度, 特征维度),需对数据进行 one-hot 编码(字符级模型常用):
# 将输入序列转换为3D张量:(样本数, 序列长度, 词汇量)
X = np.zeros((len(sequences), max_len, vocab_size), dtype=np.bool_)
# 将目标字符转换为2D张量:(样本数, 词汇量)(one-hot编码)
y = np.zeros((len(sequences), vocab_size), dtype=np.bool_)
# 填充one-hot编码
for i, seq in enumerate(sequences):
for t, idx in enumerate(seq):
X[i, t, idx] = 1 # 输入序列的第t个字符对应索引设为1
y[i, targets[i]] = 1 # 目标字符对应索引设为1
print(f"输入张量形状:{X.shape}") # (样本数, 40, 词汇量)
print(f"目标张量形状:{y.shape}") # (样本数, 词汇量)2. 构建 LSTM 模型
搭建一个包含 Embedding 层(可选,此处用 one-hot 编码可省略)、LSTM 层、Dense 层的文本生成模型:
model = Sequential([
# LSTM层:128个隐藏单元,输入形状(序列长度, 词汇量)
LSTM(128, input_shape=(max_len, vocab_size)),
# Dense层:输出维度=词汇量,Softmax激活(输出下一个字符的概率分布)
Dense(vocab_size, activation='softmax')
])
# 编译模型:优化器用RMSprop(文本生成常用),损失用交叉熵
model.compile(
optimizer='rmsprop',
loss='categorical_crossentropy'
)
# 查看模型结构
model.summary()3. 模型训练与文本生成
(1)温度采样:控制生成文本的随机性
直接选择概率最大的字符会导致生成文本重复(如 “床前明月光,床前明月光...”),需通过 “温度(temperature)” 调整概率分布:
- 温度 > 1:概率分布更平缓,生成文本随机性更高(可能出现无意义内容);
- 温度 = 1:原始概率分布,平衡随机性与连贯性;
- 温度 < 1:概率分布更陡峭,生成文本更保守(重复率高)。
def sample(preds, temperature=1.0):
preds = np.asarray(preds).astype('float64')
preds = np.log(preds) / temperature # 按温度调整概率
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds) # 重新归一化为概率分布
probas = np.random.multinomial(1, preds, 1) # 多分类采样
return np.argmax(probas) # 返回采样的字符索引(2)模型训练与生成文本(完整代码)
训练模型,并在每轮训练后生成文本,观察不同温度下的生成效果:
epochs = 60 # 训练轮数(文本生成需足够轮次拟合规律,60轮可明显看到效果)
batch_size = 128 # 批次大小(根据内存调整,此处用128平衡速度与稳定性)
# 训练模型并生成文本
for epoch in range(epochs):
print(f"\n=== 第{epoch+1}/{epochs}轮训练完成 ===")
# 单轮训练(文本生成任务通常不设验证集,重点是拟合文本的字符分布)
history = model.fit(X, y, batch_size=batch_size, epochs=1, verbose=0)
print(f"当前训练损失:{history.history['loss'][0]:.4f}") # 打印本轮损失(损失降低说明模型在学习)
# 随机选择起始序列(避免每次生成都从相同位置开始)
start_idx = random.randint(0, len(text) - max_len - 1)
generated_text = text[start_idx: start_idx + max_len] # 起始序列(长度=max_len=40)
print(f"\n生成起始序列:{generated_text}")
# 尝试3种温度,观察不同随机性的生成效果
for temperature in [0.2, 0.5, 1.0]:
print(f"\n--- 温度={temperature} 生成结果:---")
current_text = generated_text # 初始化为起始序列
# 生成100个字符(控制生成文本长度,100字符足够观察连贯性)
for _ in range(100):
# 1. 将当前文本转换为模型输入格式(one-hot编码)
input_seq = np.zeros((1, max_len, vocab_size), dtype=np.bool_) # (1, 40, 词汇量)
for t, char in enumerate(current_text):
input_seq[0, t, char_to_idx[char]] = 1 # 填充one-hot编码
# 2. 模型预测下一个字符的概率分布
preds = model.predict(input_seq, verbose=0)[0] # (词汇量,),取第一个样本的预测
# 3. 温度采样选择下一个字符
next_idx = sample(preds, temperature)
next_char = idx_to_char[next_idx]
# 4. 更新当前文本:保留最后max_len个字符(确保输入序列长度始终为40)
current_text = current_text[1:] + next_char # 去掉第一个字符,添加新字符
# 5. 实时打印生成的字符(连成完整文本)
sys.stdout.write(next_char)
sys.stdout.flush() # 强制刷新输出,避免字符堆积
print("\n" + "-"*50) # 分隔不同温度的结果(3)生成效果分析(关键观察点)
训练完成后,通过不同温度的生成结果,可观察到以下规律(以《唐诗三百首》文本为例):
- 温度 = 0.2(低随机性):
生成结果示例:床前明月光,疑是地上霜。举头望明月,低头思故乡。春眠不觉晓,处处闻啼鸟。夜来风雨声,花落知多少。白日依山尽,黄河入海流。欲穷千里目,更上一层楼。春眠不觉晓,处处闻啼鸟...
特点:文本重复率高(反复出现 “春眠不觉晓”“举头望明月” 等原诗句),但连贯性极强,几乎不会出现无意义字符。
适用场景:希望生成文本 “保守且贴合原文风格”,如仿写已知格式的文本(固定格律的诗歌)。
- 温度 = 0.5(中等随机性):
生成结果示例:床前明月光,疑是地上霜。举头望明月,低头思故乡。春眠不觉晓,处处闻啼鸟。夜来风雨声,花落知多少。白日依山尽,黄河入海流。欲穷千里目,更上一层楼。秋风清,秋月明,落叶聚还散,寒鸦栖复惊...
特点:既保留原文的诗词风格(如 “秋风清,秋月明” 符合唐诗的四字 / 五字句式),又会生成原文中没有的新组合,连贯性与创新性平衡最佳。
适用场景:大多数文本生成需求(如诗歌创作、小说片段生成),是最常用的温度设置。
- 温度 = 1.0(高随机性):
生成结果示例:床前明月光,疑是地上霜。举头望明月,低头思故乡。春眠不觉晓,处处闻啼鸟。夜来风雨声,花落知多少。白日依山尽,黄河入海流。欲穷千里目,更上一层楼。云生结海楼,江入大荒流。客舍青青柳色新,劝君更尽一杯酒...
特点:随机性最高,会生成更多原文中没有的字符组合(如 “云生结海楼” 出自李白其他诗句,模型未见过但符合风格),但偶尔会出现无意义搭配(如 “客舍青青柳色新,劝君更尽一杯酒” 两句拼接稍显生硬)。
适用场景:希望 “突破原文限制,生成更有创意的内容”,如灵感启发、实验性文本创作。
4. 让生成效果更优
上述基础实战能生成连贯文本,但在实际应用中,可通过以下优化进一步提升效果:
(1)扩大训练数据量
基础实战用了 3 首唐诗(约 200 字符),数据量过小会导致模型 “记硬背” 而非 “学习规律”。优化方案:
- 替换为完整《唐诗三百首》文本(约 5 万字),或加入宋词、元曲等同类文本,让模型学习更通用的古典诗词字符分布;
- 数据量扩大后,可增加 LSTM 隐藏单元数(如从 128 增至 256),并延长训练轮数(如 100~200 轮),让模型捕捉更复杂的句式规律。
(2)改用 Embedding 层替代 one-hot 编码
基础实战用 one-hot 编码(维度 = 词汇量),当词汇量较大(如 > 1000)时会导致输入维度爆炸。优化方案:
- 用Embedding层将字符映射到低维向量(如Embedding(vocab_size, 64, input_length=max_len)),64 维向量即可有效表达字符语义,大幅减少计算量;
- 修改后模型结构:
model = Sequential([
Embedding(vocab_size, 64, input_length=max_len), # 字符嵌入层(64维向量)
LSTM(128, return_sequences=False), # 128隐藏单元,不返回序列(因后续是Dense层)
Dense(vocab_size, activation='softmax')
])(3)堆叠多层 LSTM 提升特征捕捉能力
单一层 LSTM 对长序列的依赖捕捉能力有限,可堆叠两层 LSTM(需注意return_sequences=True):
model = Sequential([
Embedding(vocab_size, 64, input_length=max_len),
LSTM(128, return_sequences=True), # 第一层LSTM:返回序列(供下一层使用)
LSTM(64, return_sequences=False), # 第二层LSTM:不返回序列
Dense(vocab_size, activation='softmax')
])效果:多层 LSTM 能学习更复杂的字符依赖(如 “前一句的结尾与后一句的开头关联”),生成的文本句式更连贯。
(4)加入 Dropout 防止过拟合
文本生成任务中,模型易 “过拟合”(只生成训练集中的句子,无创新),可在 LSTM 层后加入 Dropout:
model = Sequential([
Embedding(vocab_size, 64, input_length=max_len),
LSTM(128, return_sequences=True),
Dropout(0.2), # 失活20%的神经元,防止过拟合
LSTM(64),
Dropout(0.2),
Dense(vocab_size, activation='softmax')
])四、最后小结
1. RNN 与 LSTM 的核心差异
|
模型 |
优势 |
局限 |
适用场景 |
|
RNN |
结构简单、计算快 |
无法处理长期依赖(梯度消失) |
短序列任务(短文本分类、1 小时预测) |
|
LSTM |
门控机制解决长期依赖、记忆可控 |
结构复杂、计算成本高 |
长序列任务(文本生成、语音识别) |
LSTM 的本质是通过 “细胞状态 + 三大门控”,让模型能 “自主选择记忆什么、忘记什么”,这是它突破 RNN 局限的关键。
2. 文本生成任务的核心逻辑
字符级语言模型的核心是 “概率预测”—— 模型学习的是 “给定前 N 个字符时,每个字符作为下一个字符的概率”,生成文本的过程就是 “基于概率不断采样下一个字符”。温度的作用是 “调整概率分布的陡峭程度”,本质是在 “连贯性” 与 “创新性” 之间找平衡。
3. 序列模型的应用扩展
除了文本生成,LSTM/GRU 还可应用于以下序列任务:
- 文本分类:如情感分析(输入句子,输出 “正面 / 负面”),通过 LSTM 捕捉句子的语义依赖;
- 机器翻译:如中英翻译(输入中文句子,输出英文句子),用 “编码器 - 解码器” 结构(Encoder-LSTM 处理输入,Decoder-LSTM 生成输出);
- 时间序列预测:如股票价格预测(输入过去 30 天价格,输出未来 1 天价格),用 LSTM 捕捉价格的时序趋势;
- 语音识别:如语音转文字(输入语音的时序特征,输出文字序列),用 LSTM 处理语音的时间维度依赖。
通过本次实战,你不仅掌握了 LSTM 的原理,还亲手实现了文本生成的全流程。后续可尝试用更大的数据集(如《红楼梦》全文)、更复杂的模型(如双向 LSTM),进一步提升生成效果 —— 序列模型的魅力就在于,数据越多、模型越贴合任务,生成的内容就越接近人类的表达逻辑。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐

 30
30 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)