⭐ 深度学习入门体系(第 14 篇): BN / LN / GN:为什么深度网络离不开“归一化”?
本文深入浅出地解释了深度学习中归一化技术的重要性。文章通过生活化类比(如健身房哑铃训练)说明归一化能解决网络训练中的"内部协变量偏移"问题。重点对比分析了三种主流归一化方法:BatchNorm(BN)适用于大batch图像任务,LayerNorm(LN)是NLP/Transformer的首选,GroupNorm(GN)则在小batch视觉任务中表现优异。文章指出归一化是深度学习的"稳定剂",能加快
⭐ 深度学习入门体系(第 14 篇): BN / LN / GN:为什么深度网络离不开“归一化”?
——用最生活化的方式讲懂深度学习的“稳定剂”
深度学习中有一个非常神奇的现象:
只要给网络加上“归一化(Normalization)”,训练马上稳定、收敛速度提升、性能更好。
去掉它?训练直接发疯。
为什么会这样?
为什么深度学习离不开 BN、LN、GN?
为什么不同的任务要用不同的归一化?
这一篇把它讲清楚。
文章目录
🧨 一、为什么深度网络需要“归一化”?
为了理解这个问题,我们先做一个生活化类比:
想象你去健身房举哑铃。
常规哑铃:
- 重量固定
- 力量可控
- 你能稳定完成训练
突然有人每次给你递来不同重量的哑铃,一会 2kg、一会 20kg、一会 50kg。
你能练得动吗?
根本不行,会被乱节奏搞崩。
深度网络也一样:
- 每层输出的“数值规模”会不断变化
- 这一层输出变大 → 下一层输入就不稳定
- 梯度也跟着乱跳
- 导致训练效果极差
这就是深度学习里臭名昭著的:
内部协变量偏移(Internal Covariate Shift)
而归一化就是给网络“固定哑铃重量”的机制,让每层接收到的信号都处于可控范围。
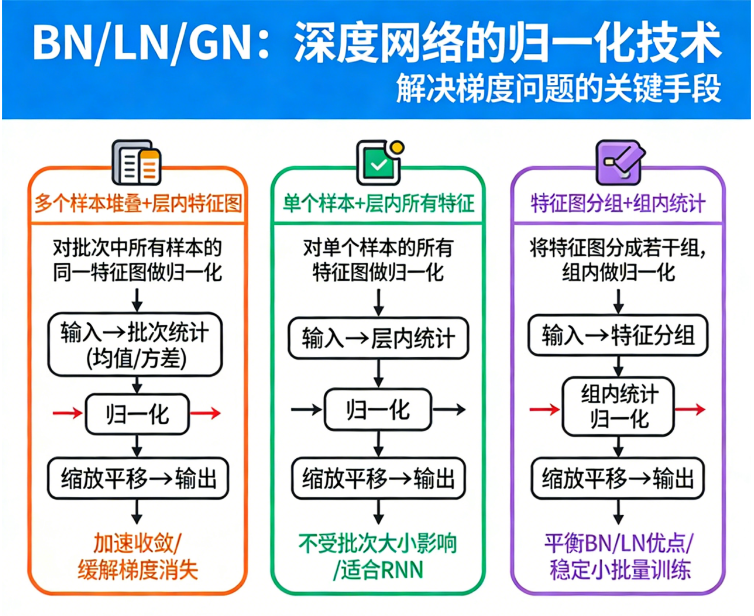
🧯 二、BatchNorm(BN):深度学习史上的稳定剂
BN 是最经典的归一化方式,被 ResNet、VGG 改造版、YOLO 等大量网络使用。
核心逻辑非常简单:
对一个 batch 中相同通道的特征,做:
减均值 → 除方差 → 拉回统一尺度。
公式不用背,本质就是:
- 让每一层输出“变得像标准正态分布”
- 然后再给一个可学习的缩放与平移(γ、β)
为什么 BN 有效?
1)让网络每层看到“稳定分布”的数据
→ 就像健身房里固定哑铃重量
→ 优化器容易找到下降方向
2)防止梯度爆炸 / 消失
→ 数值稳定,链式法则不会被无限放大或缩小
3)可以使用更大的学习率
→ 训练速度更快
4)自然带一点正则化效果
→ 因为 batch 统计有噪声
BN 的缺点
- 依赖 batch size(小 batch 效果差)
- 在 NLP 等序列任务中效果不理想
- 分布会受 batch 不稳定影响(尤其在分布式训练中会遇到问题)
这就是后续 LN、GN 出现的原因。
📘 三、LayerNorm(LN):为 NLP/Transformer 而生
BN 在图像任务表现优秀,但在 NLP 中效果不好,原因是:
NLP 的 batch size 通常很小,经常是一个句子一条样本。
那 batch 统计就完全不准。
于是 LN 出现了。
LN 的核心思想:
不在 batch 上归一化,
而是在每个样本自身的 所有通道维度 上归一化。
一句话总结:
- BN:同一通道,不同样本归一化
- LN:同一样本,不同通道归一化
生活化类比
BN 的做法像:
每个人的成绩和全班的平均水平比较
LN 的做法像:
自己的每门科目都对齐自己的水平,让成绩“更平衡”
LN 的优势:
1)与 batch size 无关
2)对 Transformer 这类模型极其稳定
3)适合序列建模、语言任务
这就是为什么 BERT、GPT、Transformer 全家桶统统用 LN。
🎽 四、GroupNorm(GN):CV 中的“折中方案”
GN 的出现源于一个痛点:
图像任务里,BN 受 batch size 限制。
而很多任务(如检测、分割)batch size 通常很小(2、4、8)。
GN 的思路更像一个“折中”:
将通道分成几组,在组内归一化。
例如,有 32 个 channel,分成 4 组,每组归一化。
GN 的优势:
- 不依赖 batch size
- 比 LN 更适合 CNN
- 收敛稳定性优于 BN(在小 batch 场景)
在 Mask R-CNN、FPN、各种高分辨率网络中 GN 都是标准配置。
🔍 五、BN / LN / GN 的本质区别(最通俗总结)
| 方法 | 在哪里归一化? | 适用场景 |
|---|---|---|
| BN | 同通道、不同样本 | 图像分类、Detection,大 batch |
| LN | 同样本、所有通道 | NLP、Transformer |
| GN | 同样本、分组通道 | 小 batch 的视觉任务 |
一句话总结:
图片用 BN(大 batch),小 batch 用 GN,NLP 用 LN。
🧪 六、极简 PyTorch 实现(理解用)
BatchNorm2d
nn.BatchNorm2d(num_features)
LayerNorm
nn.LayerNorm(normalized_shape)
GroupNorm
nn.GroupNorm(num_groups, num_channels)
工程中就是这么直接。
🧠 七、为什么“归一化”如此核心?
归一化的本质作用就是:
- 稳定数据分布
- 加快训练收敛
- 防止梯度问题
- 让参数更新更高效
- 增强泛化能力
它几乎等于“深度学习的稳定器”。
如果不归一化,深度网络就像是:
- 开车没有刹车
- 做饭没有温度控制
- 投球没有准星
- 哑铃随便变重量
能训练起来才怪。
🎯 八、总结:Normalization 是现代深度学习的“核心设施”
如果深度学习是高楼大厦:
- 卷积是地基
- 激活函数是水电
- 优化器是施工队
- 归一化就是稳固建筑的钢筋结构
没有它,楼会塌;有它,楼才能建到更高。
🔜 下一篇
《深度学习入门体系(第 15 篇):从 RNN 到 LSTM:为什么网络需要“记忆能力”?》

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)