改进灰狼优化算法性能测试:探索更优路径
12.改进灰狼优化算法性能测试改进策略:改进的tent混沌初始化;非线性控制参数;用随机游走策略更新α灰狼,用螺旋更新机制更新β灰狼,用随机数更新灰狼;自适应更新权重详细注释在优化算法的领域中,灰狼优化算法(Grey Wolf Optimizer,GWO)凭借其独特的仿生原理和不错的优化效果,吸引了众多研究者的目光。然而,如同大多数算法一样,它也存在进一步优化的空间。今天,咱们就来深入探讨一下改进
12.改进灰狼优化算法性能测试 改进策略:改进的tent混沌初始化;非线性控制参数;用随机游走策略更新α灰狼,用螺旋更新机制更新β灰狼,用随机数更新灰狼;自适应更新权重 详细注释
在优化算法的领域中,灰狼优化算法(Grey Wolf Optimizer,GWO)凭借其独特的仿生原理和不错的优化效果,吸引了众多研究者的目光。然而,如同大多数算法一样,它也存在进一步优化的空间。今天,咱们就来深入探讨一下改进灰狼优化算法的性能测试,看看这些改进策略到底能带来怎样的提升。
改进策略剖析
1. 改进的tent混沌初始化
传统的初始化方式可能导致种群分布不够均匀,容易陷入局部最优。而混沌序列具有随机性、遍历性和规律性等特点,可以让初始种群更均匀地分布在搜索空间中,为后续的搜索打下良好基础。
下面是简单的tent混沌映射代码示例:
import numpy as np
def tent_map(x0, n):
x = np.zeros(n)
x[0] = x0
for i in range(1, n):
if 0 <= x[i - 1] < 0.5:
x[i] = 2 * x[i - 1]
else:
x[i] = 2 * (1 - x[i - 1])
return x
# 假设我们要初始化种群规模为10的位置,范围在[0, 1]
pop_size = 10
x0 = 0.3 # 初始值
n = pop_size
chaotic_sequence = tent_map(x0, n)
# 将混沌序列映射到我们需要的搜索空间,这里简单假设搜索空间为[0, 10]
search_space = 10
initial_positions = chaotic_sequence * search_space
print(initial_positions)分析:在这段代码中,我们首先定义了 tent_map 函数来生成tent混沌序列。通过设置初始值 x0 和序列长度 n,循环计算出混沌序列。然后,将生成的混沌序列映射到特定的搜索空间,作为种群的初始位置。这样可以使得初始种群在搜索空间中分布得更加随机且均匀,有助于算法在初期更好地探索搜索空间。
2. 非线性控制参数
在灰狼优化算法中,控制参数对算法的搜索能力和收敛速度起着关键作用。传统的线性控制参数变化较为单一,难以在全局搜索和局部搜索之间达到较好的平衡。采用非线性控制参数,可以让算法在迭代初期具有较强的全局搜索能力,随着迭代进行,逐渐增强局部搜索能力。
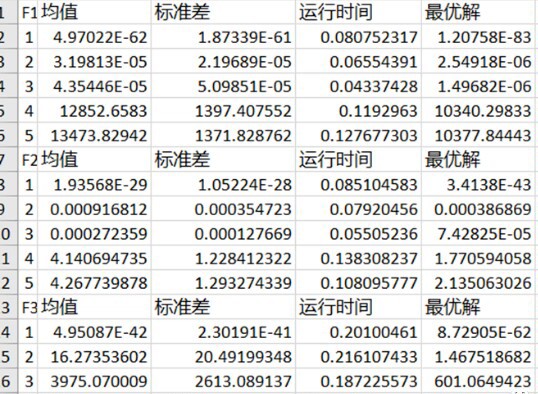
12.改进灰狼优化算法性能测试 改进策略:改进的tent混沌初始化;非线性控制参数;用随机游走策略更新α灰狼,用螺旋更新机制更新β灰狼,用随机数更新灰狼;自适应更新权重 详细注释
比如,我们可以对控制参数 a 采用如下非线性变化方式:
import numpy as np
def get_nonlinear_a(max_iter, iter_count):
a = 2 - iter_count * (2 / max_iter) ** 2
return a
max_iter = 100
for iter_count in range(max_iter):
a = get_nonlinear_a(max_iter, iter_count)
print(f"Iteration {iter_count}: a = {a}")分析:上述代码定义了 getnonlineara 函数,根据当前迭代次数 itercount 和最大迭代次数 maxiter 来计算非线性变化的 a 值。从公式 a = 2 - itercount (2 / maxiter) * 2 可以看出,随着迭代次数的增加,a 值逐渐减小,且减小的速率是非线性的。这种非线性变化使得算法在前期 a 值较大,有利于全局搜索,后期 a 值较小,更倾向于局部搜索。
3. 差异化更新策略
- 用随机游走策略更新α灰狼:α灰狼在算法中代表着最优解,传统的更新方式可能使得其更新过于保守,容易陷入局部最优。采用随机游走策略,可以增加其搜索的随机性,帮助跳出局部最优。
import numpy as np
def update_alpha_random_walk(alpha_position, step_size):
dim = len(alpha_position)
random_direction = np.random.randn(dim)
new_alpha_position = alpha_position + step_size * random_direction
return new_alpha_position
# 假设当前α灰狼位置
alpha_position = np.array([1.0, 2.0, 3.0])
step_size = 0.1
new_alpha = update_alpha_random_walk(alpha_position, step_size)
print(new_alpha)分析:updatealpharandomwalk 函数接收当前α灰狼的位置 alphaposition 和步长 stepsize。通过生成一个与位置维度相同的随机方向 randomdirection,然后按照步长与随机方向更新α灰狼的位置。这样使得α灰狼的更新不再局限于传统的方式,增加了搜索的多样性。
- 用螺旋更新机制更新β灰狼:β灰狼是仅次于α灰狼的次优解,螺旋更新机制可以模拟自然界中动物的螺旋运动方式,使β灰狼在向α灰狼靠近的同时,也能探索周围的空间。
import numpy as np
def update_beta_spiral(alpha_position, beta_position, a, b):
dim = len(alpha_position)
r1 = np.random.rand()
r2 = np.random.rand()
l = (np.random.rand() - 0.5) * 2
d_alpha = np.abs(a * r1 * alpha_position - beta_position)
beta_new = d_alpha * np.exp(b * l) * np.cos(2 * np.pi * l) + alpha_position
return beta_new
# 假设当前α和β灰狼位置
alpha_position = np.array([1.0, 2.0, 3.0])
beta_position = np.array([0.8, 1.9, 2.8])
a = 1.5
b = 1
new_beta = update_beta_spiral(alpha_position, beta_position, a, b)
print(new_beta)分析:在 updatebetaspiral 函数中,通过一系列的计算来模拟螺旋运动。首先生成随机数 r1 和 r2,用于增加更新的随机性。l 是一个与螺旋形状相关的随机变量。通过计算 d_alpha 得到β灰狼与α灰狼的距离,再结合指数和余弦函数得到螺旋更新后的β灰狼位置。这种更新方式让β灰狼在向α灰狼靠近的过程中,能够探索到更广泛的区域。
- 用随机数更新其他灰狼:对于其他灰狼个体,采用随机数更新可以进一步增加种群的多样性,避免算法过早收敛。
import numpy as np
def update_other_wolves(wolf_position, search_space):
dim = len(wolf_position)
random_update = np.random.rand(dim) * search_space
new_wolf_position = wolf_position + random_update
return new_wolf_position
# 假设当前某只灰狼位置和搜索空间
wolf_position = np.array([2.0, 3.0, 4.0])
search_space = 5
new_wolf = update_other_wolves(wolf_position, search_space)
print(new_wolf)分析:updateotherwolves 函数接收当前灰狼的位置 wolfposition 和搜索空间范围 searchspace。通过生成与位置维度相同的随机数 random_update,并将其乘以搜索空间范围,然后与当前灰狼位置相加,实现了随机更新。这种方式使得其他灰狼个体能够在搜索空间内更随机地移动,保持种群的多样性。
4. 自适应更新权重
权重在算法中影响着不同搜索方向的重要程度。自适应更新权重可以根据算法的迭代情况,动态调整权重,使得算法在不同阶段能够更好地平衡全局搜索和局部搜索。
import numpy as np
def get_adaptive_weight(max_iter, iter_count):
w = 0.9 - iter_count * (0.9 - 0.4) / max_iter
return w
max_iter = 100
for iter_count in range(max_iter):
w = get_adaptive_weight(max_iter, iter_count)
print(f"Iteration {iter_count}: w = {w}")分析:getadaptiveweight 函数根据当前迭代次数 itercount 和最大迭代次数 maxiter 计算自适应权重 w。从公式 w = 0.9 - itercount * (0.9 - 0.4) / maxiter 可知,随着迭代次数增加,权重 w 从0.9逐渐减小到0.4。在迭代初期,较大的权重有利于全局搜索,后期较小的权重则更注重局部搜索,从而实现了根据迭代进程自适应地调整搜索策略。
通过这些改进策略,我们有望显著提升灰狼优化算法的性能,使其在复杂的优化问题中能够更高效地找到全局最优解。当然,实际应用中还需要根据具体问题对这些策略进行进一步的调优和验证。希望今天的分享能为大家在优化算法的研究和应用中带来一些新的思路和启发!

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐

 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)