记录一次k8s集群worker节点NotReady的处理案例
因为最近有段时间没有使用虚拟机,再次登录k8s集群的时候发现状态异常,情况如下。
1📣问题背景
很早之前我在自己本地的虚拟机上面使用kubeadm方式搭建了3个节点的k8s集群,相关信息如下:
[root@k8s-master][~/back]
$kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane,master 2y214d v1.23.0
k8s-node1 Ready <none> 2y214d v1.23.0
k8s-node2 Ready <none> 2y214d v1.23.0
因为最近有段时间没有使用虚拟机,再次登录k8s集群的时候发现状态异常,情况如下
[root@k8s-master][~]
$kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane,master 2y214d v1.23.0
k8s-node1 NotReady <none> 2y214d v1.23.0
k8s-node2 NotReady <none> 2y214d v1.23.0
2📌问题定位
#1 查看node节点信息
kubectl describe node k8s-node1
Warning listen tcp4 :30332: bind: address already in use 160d kube-proxy can't open port "nodePort for kube-system/ratel:container-1-web-1" (:30332/tcp4), skipping it
Warning listen tcp4 :32718: bind: address already in use 160d kube-proxy can't open port "nodePort for monitoring/grafana:http" (:32718/tcp4), skipping it
Warning listen tcp4 :32145: bind: address already in use 160d kube-proxy can't open port "nodePort for monitoring/prometheus-k8s:web" (:32145/tcp4), skipping it
Warning listen tcp4 :30221: bind: address already in use 160d kube-proxy can't open port "nodePort for test/my-testservice" (:30221/tcp4), skipping it
Warning listen tcp4 :30202: bind: address already in use 160d kube-proxy can't open port "nodePort for logging/prometheus" (:30202/tcp4), skipping it
Warning listen tcp4 :31992: bind: address already in use 160d kube-proxy can't open port "nodePort for public-service/rmq-cluster-lb:http" (:31992/tcp4), skipping it
Warning listen tcp4 :30080: bind: address already in use 160d kube-proxy can't open port "nodePort for tomcat-test/tomcat-svc:tomcat-port" (:30080/tcp4), skipping it
Warning listen tcp4 :30638: bind: address already in use 160d kube-proxy can't open port "nodePort for public-service/rmq-cluster-lb:amqp" (:30638/tcp4), skipping it
Normal Starting 160d kube-proxy
Warning listen tcp4 :30865: bind: address already in use 160d kube-proxy can't open port "nodePort for monitoring/prometheus-k8s:reloader-web" (:30865/tcp4), skipping it
Normal NodeHasSufficientMemory 160d kubelet Node k8s-node1 status is now: NodeHasSufficientMemory
Normal Starting 160d kubelet Starting kubelet.
Normal NodeHasSufficientPID 160d kubelet Node k8s-node1 status is now: NodeHasSufficientPID
Normal NodeHasNoDiskPressure 160d kubelet Node k8s-node1 status is now: NodeHasNoDiskPressure
Warning Rebooted 160d kubelet Node k8s-node1 has been rebooted, boot id: 78d6ec78-c492-48aa-894c-4f9ffed2776c
Normal NodeAllocatableEnforced 160d kubelet Updated Node Allocatable limit across pods
Normal NodeReady 160d kubelet Node k8s-node1 status is now: NodeReady
Normal NodeNotReady 160d kubelet Node k8s-node1 status is now: NodeNotReady
#2 根据上述信息,一开始以为是端口被占用,登录node节点查看端口情况,发现端口正常
ss -antpl
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 10 127.0.0.1:25 *:* users:(("sendmail",pid=2317,fd=4))
LISTEN 0 64 *:2049 *:*
LISTEN 0 128 *:32933 *:* users:(("rpc.statd",pid=1064,fd=9))
LISTEN 0 128 *:111 *:* users:(("rpcbind",pid=823,fd=8))
LISTEN 0 64 *:43056 *:*
LISTEN 0 128 *:20048 *:* users:(("rpc.mountd",pid=1096,fd=8))
LISTEN 0 128 *:22 *:* users:(("sshd",pid=1055,fd=3))
LISTEN 0 128 [::]:53113 [::]:* users:(("rpc.statd",pid=1064,fd=11))
LISTEN 0 64 [::]:2049 [::]:*
LISTEN 0 128 [::]:111 [::]:* users:(("rpcbind",pid=823,fd=11))
LISTEN 0 64 [::]:42896 [::]:*
LISTEN 0 128 [::]:20048 [::]:* users:(("rpc.mountd",pid=1096,fd=10))
LISTEN 0 128 [::]:22 [::]:* users:(("sshd",pid=1055,fd=4))
#3 查看kubelet服务情况
systemctl status kubelet
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; vendor preset: disabled)
Drop-In: /usr/lib/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: activating (auto-restart) (Result: exit-code) since Wed 2025-10-15 11:19:06 CST; 3s ago
Docs: https://kubernetes.io/docs/
Process: 3346 ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS (code=exited, status=1/FAILURE)
Main PID: 3346 (code=exited, status=1/FAILURE)
#4 查看kubelet日志信息
journalctl -x -u kubelet
Oct 15 10:59:35 k8s-node2 kubelet[1058]: Flag --network-plugin has been deprecated, will be removed along with dockershim.
Oct 15 10:59:35 k8s-node2 kubelet[1058]: Flag --feature-gates has been deprecated, This parameter should be set via the config file specif
Oct 15 10:59:35 k8s-node2 kubelet[1058]: Flag --network-plugin has been deprecated, will be removed along with dockershim.
Oct 15 10:59:35 k8s-node2 kubelet[1058]: Flag --feature-gates has been deprecated, This parameter should be set via the config file specif
Oct 15 10:59:35 k8s-node2 kubelet[1058]: I1015 10:59:35.473879 1058 server.go:446] "Kubelet version" kubeletVersion="v1.23.0"
Oct 15 10:59:35 k8s-node2 kubelet[1058]: I1015 10:59:35.474331 1058 server.go:874] "Client rotation is on, will bootstrap in background
Oct 15 10:59:35 k8s-node2 kubelet[1058]: E1015 10:59:35.629498 1058 bootstrap.go:265] part of the existing bootstrap client certificate
Oct 15 10:59:35 k8s-node2 kubelet[1058]: E1015 10:59:35.630963 1058 server.go:302] "Failed to run kubelet" err="failed to run Kubelet:unable to load bootstrap kubeconfig: stat /etc/kubernetes/bootstrap-kubelet.conf: no such file or directory"
3🔍 问题分析
#从以下报错信息可以看出来问题所在
“Failed to run kubelet” err=“failed to run Kubelet:unable to load bootstrap kubeconfig: stat /etc/kubernetes/bootstrap-kubelet.conf: no such file or directory”
kubelet 启动时无法找到 /etc/kubernetes/bootstrap-kubelet.conf 文件。这个文件是 kubelet 启动时用于引导的 kubeconfig 文件,通常用于在 TLS 引导过程中获取初始凭证。
可能的原因和解决方法:
- 检查文件是否存在:首先确认
/etc/kubernetes/bootstrap-kubelet.conf文件是否确实不存在。如果不存在,需要创建或重新生成。 - 如果使用 kubeadm 部署:
- 如果这个节点是刚刚加入集群的,可以尝试重新运行 kubeadm join 命令(如果还在有效期内,token 通常24小时有效)。
- 如果节点已经加入集群,但 bootstrap-kubelet.conf 文件被误删,可以尝试从其他相同节点复制一个过来(但注意每个节点的证书可能不同,不推荐)或者重新生成。
- 重新生成 bootstrap-kubelet.conf:
- 如果集群还在,并且你拥有集群的访问权限,可以尝试重新生成 bootstrap-kubelet.conf 文件。通常,这个文件是在节点加入集群时由 kubeadm 生成的。如果节点已经加入,kubelet 应该已经生成了自己的 kubeconfig 文件(通常是
/etc/kubernetes/kubelet.conf),那么 bootstrap-kubelet.conf 文件就不是必须的了。
- 如果集群还在,并且你拥有集群的访问权限,可以尝试重新生成 bootstrap-kubelet.conf 文件。通常,这个文件是在节点加入集群时由 kubeadm 生成的。如果节点已经加入,kubelet 应该已经生成了自己的 kubeconfig 文件(通常是
- 检查 kubelet 服务配置:
- 查看 kubelet 的启动参数(例如通过
systemctl cat kubelet或查看/etc/systemd/system/kubelet.service.d/10-kubeadm.conf等配置文件)中是否指定了--bootstrap-kubeconfig参数,并且指向了/etc/kubernetes/bootstrap-kubelet.conf。如果这个文件不存在,而且 kubelet 已经完成引导,可以考虑修改启动参数,去掉这个引导配置,而是使用正式的 kubeconfig 文件(即--kubeconfig参数指定的文件,通常是/etc/kubernetes/kubelet.conf)。
- 查看 kubelet 的启动参数(例如通过
- 已经完成引导的节点:
- 如果节点已经成功加入集群,那么 kubelet 应该已经使用 bootstrap-kubelet.conf 获取了初始凭证,并生成了正式的 kubelet.conf(包含节点自己的证书和密钥)。此时,bootstrap-kubelet.conf 就不再需要了。你可以尝试修改 kubelet 的启动参数,移除
--bootstrap-kubeconfig参数,只保留--kubeconfig参数,然后重启 kubelet。
- 如果节点已经成功加入集群,那么 kubelet 应该已经使用 bootstrap-kubelet.conf 获取了初始凭证,并生成了正式的 kubelet.conf(包含节点自己的证书和密钥)。此时,bootstrap-kubelet.conf 就不再需要了。你可以尝试修改 kubelet 的启动参数,移除
4🛠️ 解决方案
方案一:重新生成引导配置文件(推荐)
-
检查 kubeadm 配置
# 查看 kubeadm 配置 kubeadm config view -
重新生成引导文件
# 在控制平面节点执行 kubeadm init phase kubeconfig kubelet --apiserver-advertise-address <API-SERVER-IP> # 将生成的配置文件复制到问题节点 scp /etc/kubernetes/bootstrap-kubelet.conf root@<问题节点IP>:/etc/kubernetes/ scp /etc/kubernetes/kubelet.conf root@<问题节点IP>:/etc/kubernetes/
方案二:手动创建引导配置文件
本次使用方案二
如果上述方法不可行,可以手动创建:
-
在控制平面节点获取引导信息(master节点)
# 获取引导令牌和 CA 证书哈希 kubeadm token list kubeadm token create openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //' -
在问题节点创建引导配置文件
# 创建配置文件 cat > /etc/kubernetes/bootstrap-kubelet.conf << EOF apiVersion: v1 clusters: - cluster: certificate-authority-data: #$(cat /etc/kubernetes/pki/ca.crt | base64 | tr -d '\n') server: https://<API-SERVER-IP>:6443 name: bootstrap contexts: - context: cluster: bootstrap user: kubelet-bootstrap name: bootstrap current-context: bootstrap kind: Config preferences: {} users: - name: kubelet-bootstrap user: token: #<刚才使用kubeadm token create新创建的引导令牌> EOF
方案三:从其他正常节点复制
如果集群中有其他正常工作的节点:
-
从正常节点复制文件
# 在正常节点执行 scp /etc/kubernetes/bootstrap-kubelet.conf root@<问题节点IP>:/etc/kubernetes/ scp /etc/kubernetes/kubelet.conf root@<问题节点IP>:/etc/kubernetes/ -
调整权限
chmod 600 /etc/kubernetes/bootstrap-kubelet.conf chmod 600 /etc/kubernetes/kubelet.conf chown root:root /etc/kubernetes/bootstrap-kubelet.conf chown root:root /etc/kubernetes/kubelet.conf
方案四:检查并修复 kubelet 配置
-
检查 kubelet 配置文件
# 查看 kubelet 配置参数 cat /etc/systemd/system/kubelet.service.d/10-kubeadm.conf # 或者查看 kubelet 配置 cat /var/lib/kubelet/config.yaml -
确保配置正确指向引导文件
# 检查 kubelet 启动参数 ps aux | grep kubelet确保包含:
--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf
方案五:重新加入节点
如果以上方法都无效,考虑重新加入节点:
-
在控制平面节点执行
# 驱逐节点上的 Pod(如果节点还在集群中) kubectl drain <节点名称> --delete-local-data --force --ignore-daemonsets # 删除节点 kubectl delete node <节点名称> -
在问题节点执行
# 清理 kubelet kubeadm reset -f rm -rf /etc/kubernetes/* rm -rf /var/lib/kubelet/* # 重新加入集群(使用原始的 kubeadm join 命令) kubeadm join <API-SERVER-IP>:6443 --token <token> \ --discovery-token-ca-cert-hash sha256:<hash>
5📋 验证步骤
#1 查看kubelet
systemctl status kubelet
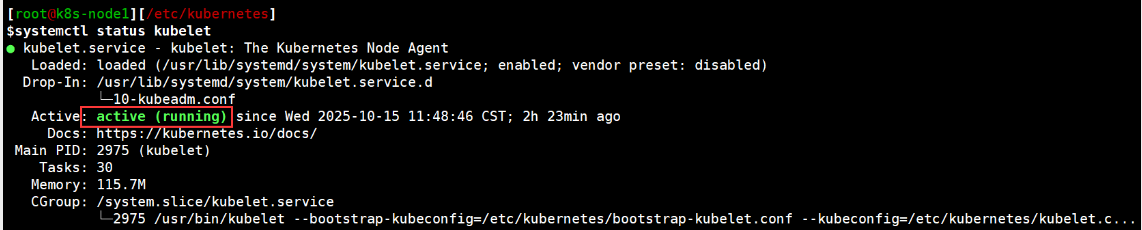
#2 k8s查看集群状态
kubectl get node
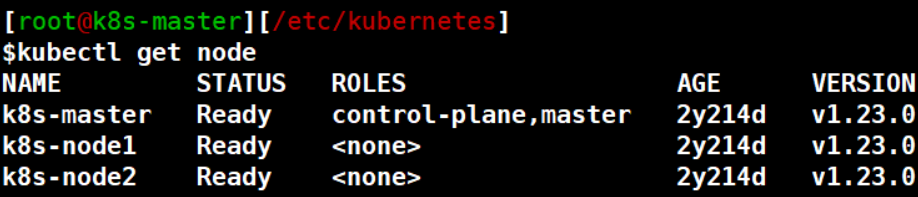
#3 查看pod运行情况
kubectl get pod -A|grep -v Running

6💡 预防措施
因为我的环境是测试环境,所以没有弄下面的操作,生产情况建议还是加上
- 定期备份关键配置文件
- 使用配置管理工具(如 Ansible)确保配置文件一致性
- 建立监控告警,监控关键文件的存在性
本文来源于我的微信公众号Linux运维小白,我会持续更新文章,欢迎大家关注,互相交流学习。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)