Python编程学习思维导图大全
函数是组织好的、可重复使用的、用来执行特定任务的代码块。Python提供了许多内建函数,例如print(),也允许用户自定义函数。函数定义的基本结构如下:"""函数文档字符串"""def是定义函数的关键字。是函数名,应遵循标识符的命名规则。parameters是传递给函数的参数,函数可以没有参数,也可以有多个参数。是函数执行的语句块。return语句可以返回值给函数调用者,若没有,则默认返回Non

简介:在Python编程学习中,思维导图能够帮助学习者系统化地理解和记忆复杂概念和语法。本压缩包文件包含了Python基础语法、函数与模块、面向对象编程、高级特性、实战应用以及测试和调试等多个方面的思维导图,为初学者和进阶者提供了全面的学习辅助工具。通过结构化的展现方式,学习者可以清晰地掌握各个知识点,提高学习效率,并在实际项目中应用所学技能。
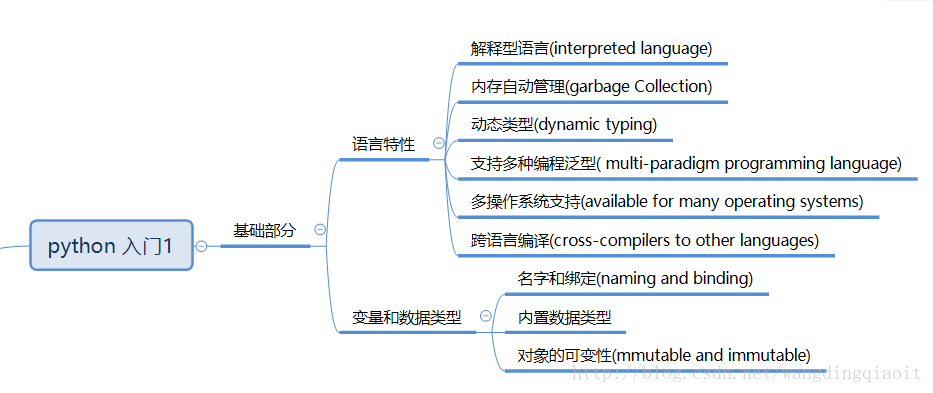
1. Python基础语法思维导图
Python作为一种高级编程语言,以简洁明了著称。其基础语法是构建复杂程序的基石。本章节将对Python的核心语法元素进行全面梳理,并以思维导图的形式展现。
1.1 语法基础
Python的语法非常接近英语,这使得初学者能够快速上手。其中,缩进是Python语法中最为显著的特色之一,它用来表示代码块的结构。标识符的命名要遵循特定的规则,比如变量名应以字母或下划线开头,不能使用Python的关键字。
# 示例:缩进和变量命名
def greet(name):
print("Hello, " + name) # 函数缩进,正确代码块结构
message = "How are you?" # 合法的变量命名
1.2 数据类型与操作
Python中的数据类型分为可变类型和不可变类型。不可变类型如整数(int)、浮点数(float)、字符串(str)和元组(tuple),意味着一旦创建,不能改变其值;而可变类型如列表(list)、字典(dict)和集合(set),则可动态地修改。
# 示例:数据类型操作
numbers = [1, 2, 3] # 列表(可变类型)
numbers.append(4) # 列表动态添加元素
print(numbers) # 输出:[1, 2, 3, 4]
1.3 控制结构
控制结构是编程中用来决定程序执行路径的重要组成部分,Python提供了多种控制结构,如if-else条件语句、for和while循环。这些结构使得程序能够进行决策判断和重复操作。
# 示例:控制结构
for number in numbers:
if number > 2:
print(number, "is greater than 2") # 条件语句与循环的结合
else:
print(number, "is less than or equal to 2")
通过本章的学习,读者将掌握Python编程的初步知识,为后续深入学习打下坚实基础。随着对语法的理解不断加深,将逐步探索更高级的概念和特性。
2. 函数与模块概念思维导图
2.1 Python函数的定义和使用
2.1.1 函数的基本结构和参数传递
函数是组织好的、可重复使用的、用来执行特定任务的代码块。Python提供了许多内建函数,例如 print() ,也允许用户自定义函数。
函数定义的基本结构如下:
def function_name(parameters):
"""函数文档字符串"""
function_suite
return [expression]
def是定义函数的关键字。function_name是函数名,应遵循标识符的命名规则。parameters是传递给函数的参数,函数可以没有参数,也可以有多个参数。function_suite是函数执行的语句块。return语句可以返回值给函数调用者,若没有,则默认返回None。
在Python中,函数参数的传递方式有以下几种:
- 必须参数(Required arguments)
- 关键字参数(Keyword arguments)
- 默认参数(Default arguments)
- 可变参数(Variable-length arguments)
下面是一个包含各种参数传递方式的函数示例:
def func(a, b, c=0, *args, **kwargs):
print("a = %s" % a)
print("b = %s" % b)
print("c = %s" % c)
print("args = %s" % args)
print("kwargs = %s" % kwargs)
调用该函数的示例:
func(1, 2, 3, 4, 5, x=6, y=7)
输出:
a = 1
b = 2
c = 3
args = (4, 5)
kwargs = {'x': 6, 'y': 7}
在该示例中, a 和 b 是必须参数, c 是带有默认值的参数, *args 用来接受任意数量的非关键字参数, **kwargs 用来接受任意数量的关键字参数。
2.1.2 高级函数特性:默认参数、关键字参数
Python中的高级函数特性允许开发者使用更加灵活的参数传递方式,提高函数的可用性和可读性。
默认参数 是指函数定义时已经设定好的参数值,如果在调用时不显式提供该参数,就会使用默认值。默认参数应放在函数参数列表的末尾。
def increment_by(n, step=1):
return n + step
print(increment_by(10)) # 使用默认值
print(increment_by(10, 2)) # 使用自定义的step值
关键字参数 允许调用者按照参数名来传递参数的值,而不是根据位置。关键字参数可以与必须参数和默认参数混合使用。
def display_info(name, age):
print(f"Name: {name}, Age: {age}")
display_info(name="Alice", age=30)
在这个例子中,关键字参数使得参数的顺序可以颠倒,这在函数参数较多时非常有用。
2.2 模块和包的使用
2.2.1 模块的导入和使用规则
模块是包含Python代码的文件,后缀名为 .py 。一个模块可以包含可执行语句、函数定义、类定义等。
导入模块的几种方式如下:
import math # 导入整个模块,使用模块名作为前缀访问模块中的函数
from math import sqrt # 从模块中导入特定函数,无需模块名作为前缀
from math import * # 导入模块中的所有内容,不推荐使用,可能导致命名冲突
导入模块后,可以在代码中使用其功能:
import math
print(math.sqrt(16)) # 输出: 4.0
在Python 3中,还可以使用 as 关键字给导入的模块或函数指定别名:
import math as m
print(m.sqrt(16)) # 输出: 4.0
2.2.2 包的创建和命名空间管理
包是一种管理多个模块的方式,本质上是一个包含 __init__.py 文件的目录,该文件可以为空,也可以包含初始化代码。包可以包含模块和其他包,从而形成层次化的结构。
创建包的步骤如下:
- 创建一个包含
__init__.py的目录。 - 将模块文件放入该目录。
- 将该目录添加到Python的搜索路径或使用
importlib模块动态导入。
假设我们有如下目录结构:
mypackage/
__init__.py
module1.py
module2.py
在 __init__.py 文件中可以初始化包变量或函数,而在模块文件中定义具体的功能。
命名空间管理是指Python如何识别不同包和模块中的同名变量或函数。通过使用完整的包路径或模块前缀,可以避免命名冲突。
2.2.3 标准库模块的深入探索
Python的标准库包含很多预构建的模块,这些模块提供了强大的功能,使得很多常见的任务不需要从头编写代码。
举个例子, os 模块允许你使用操作系统相关功能:
import os
print(os.name) # 显示当前使用的操作系统
使用标准库模块时,遵循以下最佳实践:
- 阅读官方文档,了解模块功能。
- 使用
help()函数或IPython的?来获取帮助信息。 - 学习模块的常见用法,避免重复造轮子。
2.3 编码规范和最佳实践
2.3.1 PEP8编码风格指南
PEP 8是Python Enhancement Proposal #8的缩写,它是一份Python代码的风格指南。遵循PEP 8可以让Python代码更具有可读性。
PEP 8中的一些主要规范包括:
- 使用4个空格缩进,不使用制表符(Tab)。
- 每行最多不超过79个字符,使代码易于在窗口之间轻松切换。
- 二进制运算符左右各加一个空格,例如
a + b。 - 语句之后需要有一个空行,例如
if之后、函数定义之后等。 - 模块级的变量和常量应该放在模块顶部,函数和类之后。
- 为复杂的表达式使用括号,增强可读性。
一个遵守PEP 8风格的示例:
# Function example
def function_name(parameter_1, parameter_2=None, *args, **kwargs):
"""Function description."""
if parameter_1 > parameter_2:
return parameter_2
else:
return parameter_1
# Class example
class MyClass:
"""Class documentation."""
def __init__(self, arg1, arg2):
self.arg1 = arg1
self.arg2 = arg2
2.3.2 命名规范和代码布局
Python中有一些约定俗成的命名规范,遵循这些规范可以帮助维护代码的整洁和一致性。
- 变量、函数名、属性使用小写字母和下划线,例如
max_value。 - 受保护的实例属性,以单个下划线开头。
- 私有的实例属性,以两个下划线开头。
- 类和异常名使用首字母大写单词,例如
MyClass。 - 模块级别的常量使用全大写字母和下划线,例如
MAX_OVERFLOW。
代码布局的规范包括:
- 类定义后换行,函数定义后换行。
- 相关的类和函数应该放在一起。
- 在逻辑上将代码分成不同的段落,每一段后留一行空行。
遵循这些命名和布局规范,可以让代码更加清晰,易于理解。
3. 面向对象编程思维导图
3.1 类和对象的基本概念
3.1.1 类的定义和属性
在Python中,类是一个蓝图,用于创建具有共同特征和行为的对象。类定义使用关键字 class ,后跟类名和冒号,定义类的主体。类的基本结构如下:
class ClassName:
# 类体
def __init__(self):
# 初始化方法
pass
其中, __init__ 是一个特殊方法,被称为构造器,用于在创建对象时初始化对象的状态。
属性分为两类:类属性和实例属性。
- 类属性 :直接定义在类体中的属性,属于整个类。
- 实例属性 :在
__init__方法中定义,每个对象实例都有自己的一份。
class Dog:
# 类属性
species = 'Canis familiaris'
def __init__(self, name, age):
# 实例属性
self.name = name
self.age = age
3.1.2 对象的创建和使用
创建对象的过程称为实例化。实例化时,Python会自动调用 __init__ 方法,传入实例本身(通常以 self 为名)和其他初始化参数。
my_dog = Dog('Max', 5)
创建对象 my_dog 后,可以通过点号 . 操作符访问其属性:
print(my_dog.name) # 输出: Max
print(my_dog.age) # 输出: 5
print(Dog.species) # 输出: Canis familiaris
表格:类属性与实例属性的比较
| 属性类型 | 定义位置 | 访问方式 | 是否共享 | |---------|---------|---------|---------| | 类属性 | 类体中定义 | 类名.属性名 | 是 | | 实例属性 | __init__ 方法中定义 | 实例名.属性名 | 否 |
3.2 面向对象的高级特性
3.2.1 继承、多态和封装的实现
继承允许我们创建一个类,它继承另一个类的所有属性和方法。这样,我们就可以重用代码,创建更具体的类型。
class Animal:
def speak(self):
pass
class Dog(Animal):
def speak(self):
return "Woof"
在这个例子中, Dog 类继承了 Animal 类。
多态 是指同一个操作作用于不同的对象时,可以有不同的解释和不同的执行结果。在Python中,多态主要通过方法重写实现。
def make_animal_speak(animal):
print(animal.speak())
# 假设Cat类也继承Animal类并重写了speak方法
make_animal_speak(Dog()) # 输出: Woof
make_animal_speak(Cat()) # 输出: Meow
封装 是隐藏对象的属性和实现细节,只对外公开接口。Python通过使用下划线前缀 _ 或双下划线 __ 实现封装。
class BankAccount:
def __init__(self, balance):
self.__balance = balance
def deposit(self, amount):
if amount > 0:
self.__balance += amount
在这里, __balance 是私有属性,外部代码应通过 deposit 方法与之交互。
3.3 设计模式与面向对象思维
3.3.1 常用设计模式简介
设计模式是针对软件设计中常见问题的解决方案模板。在面向对象编程中,设计模式用于提高代码的可维护性和可复用性。以下是一些常见的设计模式:
- 单例模式 :确保一个类只有一个实例,并提供全局访问点。
- 工厂模式 :定义了一个创建对象的接口,但由子类决定要实例化的类是哪一个。
- 策略模式 :定义了一系列算法,并将每个算法封装起来,使它们可以互换。
- 观察者模式 :定义对象间的一种一对多依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都会得到通知。
3.3.2 设计模式在Python中的应用案例
单例模式 :
class Singleton:
_instance = None
def __new__(cls, *args, **kwargs):
if not cls._instance:
cls._instance = super(Singleton, cls).__new__(cls, *args, **kwargs)
return cls._instance
# 使用单例
first = Singleton()
second = Singleton()
print(first is second) # 输出: True
策略模式 :
class Strategy:
def calculate(self, num1, num2):
pass
class Add(Strategy):
def calculate(self, num1, num2):
return num1 + num2
class Subtract(Strategy):
def calculate(self, num1, num2):
return num1 - num2
# 使用策略
context = Strategy()
print(context.calculate(10, 5)) # 输出: 15
context = Subtract()
print(context.calculate(10, 5)) # 输出: 5
在本节中,我们深入探讨了面向对象编程的基本概念,包括类的定义、对象的创建和使用,以及面向对象的高级特性如继承、多态和封装。此外,我们还介绍了设计模式的概念,并通过Python中的应用案例加深了对常用设计模式的理解。这些概念和技巧是编写可维护和可复用代码的关键。
4. Python高级特性思维导图
4.1 迭代器和生成器
4.1.1 迭代器协议和实现原理
迭代器是Python中最强大的特性之一,它提供了一种优雅的方式来访问集合中的元素。迭代器协议要求对象必须实现 __iter__() 和 __next__() 方法,这两个方法共同工作以支持迭代。
__iter__()方法返回迭代器对象本身。__next__()方法返回序列的下一个元素,如果没有元素了,则抛出StopIteration异常。
迭代器协议实现示例代码:
class MyIterator:
def __init__(self, collection):
self.collection = collection
self.iterator = iter(collection)
def __iter__(self):
return self
def __next__(self):
try:
return next(self.iterator)
except StopIteration:
raise StopIteration # 或者返回None,或者抛出其他异常
# 使用示例
iterable = MyIterator([1, 2, 3])
for item in iterable:
print(item)
在这个例子中, MyIterator 类定义了如何按照迭代协议遍历一个集合。每个实例都有一个内部的 iterator 对象,该对象由 __iter__() 方法返回。每次调用 __next__() 方法时,都会从集合中获取下一个元素,直到所有元素都被遍历完毕。
参数说明和逻辑分析:
collection是被迭代的对象。iter()函数用来获取集合的迭代器。next()函数用来获取迭代器的下一个元素。
4.1.2 生成器的创建和优化技巧
生成器是一种特殊的迭代器,它们通过 yield 语句产生一系列的值,而不是一次性生成所有值。这使得生成器在处理大量数据时非常高效,因为它们在任何给定时间只占用内存中的一个值。
生成器创建示例代码:
def count_to_three():
yield 1
yield 2
yield 3
# 使用生成器
for number in count_to_three():
print(number)
生成器的优化技巧包括: - 使用 send() 方法与生成器进行双向通信。 - 利用 throw() 方法在生成器中抛出异常。 - 利用 close() 方法停止生成器。
4.2 装饰器和上下文管理器
4.2.1 装饰器的原理和应用
装饰器是一种设计模式,它允许在不修改原有函数或类的情况下扩展其功能。装饰器本质上是一个函数,它接受一个函数作为参数,并返回一个新的函数。
装饰器应用示例代码:
def my_decorator(func):
def wrapper():
print("Something is happening before the function is called.")
func()
print("Something is happening after the function is called.")
return wrapper
@my_decorator
def say_hello():
print("Hello!")
say_hello()
在这个例子中, my_decorator 是一个装饰器,它在原始函数 say_hello 执行前后添加了额外的代码。通过使用 @ 语法,我们“装饰”了 say_hello 函数。
装饰器的优化技巧包括: - 使用 functools.wraps 来保留原函数的元信息。 - 使用装饰器链来应用多个装饰器。 - 使用参数化装饰器来创建灵活的装饰器。
4.2.2 上下文管理器的使用和自定义
上下文管理器通过 with 语句来管理资源,确保资源在使用后能够正确地释放。上下文管理器最常用的实现方式是通过 __enter__() 和 __exit__() 方法。
上下文管理器使用示例代码:
class MyContextManager:
def __enter__(self):
print("Entering context")
return self
def __exit__(self, exc_type, exc_value, traceback):
print("Exiting context")
with MyContextManager() as manager:
print("Inside context")
# 输出:
# Entering context
# Inside context
# Exiting context
在这个例子中, MyContextManager 类定义了上下文管理器的行为。 __enter__() 方法在进入 with 代码块时被调用,而 __exit__() 方法在退出 with 代码块时被调用。
上下文管理器的优化技巧包括: - 确保 __exit__() 方法返回 False 以允许异常抛出。 - 使用 contextlib 模块中的装饰器如 contextmanager 来简化上下文管理器的编写。
4.3 并发编程思维导图
4.3.1 多线程编程的基础和高级特性
Python通过 threading 模块提供了对多线程编程的支持。多线程可以让程序同时执行多个线程,从而提高程序的效率,特别是在I/O密集型任务中。
多线程编程基础示例代码:
import threading
def print_numbers():
for i in range(1, 6):
print(i)
thread1 = threading.Thread(target=print_numbers)
thread1.start()
thread2 = threading.Thread(target=print_numbers)
thread2.start()
在这个例子中,我们创建了两个线程,每个线程都执行 print_numbers 函数,该函数打印从1到5的数字。
多线程编程的高级特性包括: - 使用线程锁( threading.Lock() )来处理资源竞争问题。 - 使用事件( threading.Event() )来同步线程。 - 使用信号量( threading.Semaphore() )来限制对资源的访问数量。
4.3.2 异步编程的原理和实践
异步编程允许程序中的一部分在等待I/O操作或其他长时间运行的操作完成时继续执行。Python通过 asyncio 模块支持异步编程。
异步编程实践示例代码:
import asyncio
async def say_after(delay, what):
await asyncio.sleep(delay)
print(what)
async def main():
print(f"started at {time.strftime('%X')}")
await say_after(1, 'hello')
await say_after(2, 'world')
print(f"finished at {time.strftime('%X')}")
asyncio.run(main())
在这个例子中, say_after 函数是一个异步函数,它使用 asyncio.sleep 来模拟异步I/O操作。 main 函数是程序的入口点,它通过 asyncio.run 来运行异步程序。
异步编程的优化技巧包括: - 使用 async with 语句和异步上下文管理器来管理异步资源。 - 使用异步生成器 async def 和 async for 来异步地遍历数据。 - 正确处理异步程序中的异常情况。
5. 实战应用思维导图
在本章节中,我们将深入了解Python在实际应用中的一些关键场景,并探索如何有效地利用Python强大的库和框架来完成具体任务。
5.1 文件操作和数据处理
文件操作和数据处理是编程中常见的需求,Python为这些需求提供了多种内置的库和方法,简化了操作步骤并增强了效率。
5.1.1 文件的读写和序列化技术
在文件读写方面,Python提供了一系列内置函数,使得文件操作变得简单。以下是文件基本操作的示例代码:
# 打开文件
with open('example.txt', 'w') as file:
file.write('Hello, Python!")
# 读取文件内容
with open('example.txt', 'r') as file:
content = file.read()
# 打印文件内容
print(content)
在处理文件时,有时需要进行序列化和反序列化,特别是对于复杂的数据结构。Python的 json 和 pickle 模块在这方面非常有用。以下是使用 json 模块将数据写入文件的示例:
import json
# 数据结构
data = {'name': 'Alice', 'age': 25, 'city': 'New York'}
# 序列化数据
with open('data.json', 'w') as file:
json.dump(data, file)
# 从文件反序列化数据
with open('data.json', 'r') as file:
loaded_data = json.load(file)
print(loaded_data)
序列化不仅仅是 json 模块的专利, pickle 模块也提供了强大的序列化功能,尤其是对Python对象的支持。
5.1.2 数据分析库Pandas的使用
Pandas是一个开源的Python数据分析库,提供了高性能、易于使用的数据结构和数据分析工具。以下是如何使用Pandas库来处理CSV文件的示例:
import pandas as pd
# 加载CSV文件
df = pd.read_csv('data.csv')
# 查看数据帧的前5行
print(df.head())
# 数据筛选
filtered_data = df[df['age'] > 20]
# 数据统计分析
print(filtered_data.describe())
# 数据保存到新的CSV文件
filtered_data.to_csv('filtered_data.csv', index=False)
Pandas库使得对数据进行清洗、过滤、统计分析变得非常便捷,这在数据处理项目中是不可或缺的技能。
5.2 网络编程和异步I/O
Python通过多种方式支持网络编程,包括标准库中的 socket 模块和用于异步I/O的 asyncio 库。
5.2.1 网络编程基础:socket编程
Socket编程是网络通信的基础,Python的 socket 模块允许程序员轻松地编写网络客户端和服务器程序。以下是一个简单的TCP客户端和服务器之间的对话示例:
import socket
# 服务器地址和端口
server_address = ('localhost', 10000)
# 创建socket对象
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
s.bind(server_address)
s.listen()
conn, addr = s.accept()
with conn:
print('Connected by', addr)
while True:
data = conn.recv(1024)
if data:
print('Received', repr(data))
conn.sendall(data)
else:
break
5.2.2 异步I/O框架:asyncio的应用
异步I/O通过 asyncio 模块得到Python的原生支持,使得编写并发网络代码更加高效。以下是一个简单的异步服务器示例:
import asyncio
async def handle_client(reader, writer):
data = await reader.read(100)
message = data.decode()
addr = writer.get_extra_info('peername')
print(f"Received {message} from {addr}")
print("Send: Hello, world!")
writer.write(b"Hello, world!")
await writer.drain()
print("Close the connection")
writer.close()
async def main():
server = await asyncio.start_server(
handle_client, 'localhost', 8888)
addr = server.sockets[0].getsockname()
print(f'Serving on {addr}')
async with server:
await server.serve_forever()
asyncio.run(main())
在上述代码中,服务器端使用异步函数 handle_client 处理客户端发送的数据,并发送响应。 asyncio.run(main()) 用于启动异步服务器。
5.3 图形用户界面编程
Python通过多种GUI框架简化了创建桌面应用程序的过程,其中 Tkinter 和 PyQt 是最常用的框架之一。
5.3.1 GUI框架Tkinter的使用
Tkinter 是Python的标准GUI库,提供了一种快速创建窗口和小部件的方法。下面的代码展示了如何使用 Tkinter 创建一个简单的窗口:
import tkinter as tk
# 创建窗口对象
root = tk.Tk()
# 设置窗口标题
root.title("Tkinter Basic Window")
# 创建一个标签
label = tk.Label(root, text="Hello, Tkinter!", width=50, height=5)
label.pack()
# 运行主循环
root.mainloop()
5.3.2 跨平台GUI框架PyQt的应用
PyQt 是一个较高级的GUI框架,它提供了丰富的控件和强大的功能。以下是使用 PyQt 创建一个简单窗口的示例:
from PyQt5.QtWidgets import QApplication, QWidget, QLabel, QVBoxLayout
# 创建应用实例
app = QApplication([])
# 创建一个窗口对象
window = QWidget()
# 创建一个标签
label = QLabel('Hello, PyQt!')
# 设置窗口布局
layout = QVBoxLayout()
layout.addWidget(label)
window.setLayout(layout)
# 显示窗口
window.show()
# 运行主循环
app.exec_()
PyQt 不仅支持跨平台操作,而且还支持与Python的其他库集成,使得创建复杂的应用程序变得简单快捷。
以上就是实战应用思维导图中关于文件操作、网络编程和GUI编程的详细介绍,通过代码示例和解释,我们了解了如何使用Python的高级特性来解决实际问题。下一章节将关注测试和调试,这在软件开发过程中同样至关重要。
6. 测试和调试思维导图
测试和调试是软件开发过程中不可或缺的环节。这一章节将深入探讨Python中的单元测试、调试技巧以及性能分析和优化。
6.1 单元测试的编写和管理
单元测试是软件开发中对最小可测试单元进行检查和验证的过程。Python提供了多个单元测试框架,其中最著名的是 unittest 模块。
6.1.1 测试框架unittest的使用
unittest 是Python的标准单元测试库。它支持测试自动化、共享搭建和拆卸代码、测试套件的组合以及多种测试运行器的使用。以下是一个简单的使用 unittest 模块的例子。
import unittest
def add(a, b):
return a + b
class TestAddFunction(unittest.TestCase):
def test_add_integers(self):
self.assertEqual(add(1, 2), 3)
def test_add_floats(self):
self.assertAlmostEqual(add(1.1, 2.2), 3.3, places=1)
def test_add_strings(self):
self.assertEqual(add('hello ', 'world'), 'hello world')
if __name__ == '__main__':
unittest.main()
在这个例子中,我们定义了一个简单的加法函数 add ,并用 unittest 框架编写了三个测试用例。每个测试用例都继承自 unittest.TestCase 类,并定义了 test_ 开头的方法来执行测试。使用 assertEqual 和 assertAlmostEqual 来验证结果是否符合预期。
6.1.2 测试驱动开发(TDD)的理念
测试驱动开发(TDD)是一种软件开发方法,要求先编写测试用例,然后实现功能,最后重构代码。TDD的基本流程如下:
- 编写一个失败的测试用例。
- 实现最小的代码改动以使测试通过。
- 重构代码并确保所有测试用例仍然通过。
- 重复以上步骤。
TDD能够帮助开发者聚焦于需求,减少不必要的开发,并提高代码质量。
6.2 调试技巧和工具
调试是找出程序错误并修正的过程。有效的调试策略可以大幅提升开发效率。
6.2.1 常用调试工具的介绍
Python提供了一些内置的调试工具和库,比如 pdb 。 pdb 是Python的内置调试工具,支持断点、单步执行、堆栈跟踪等。
使用 pdb 的步骤如下:
- 导入
pdb模块。 - 在程序中需要断点的位置插入
pdb.set_trace()。 - 运行程序,程序会在断点处暂停。
import pdb
def my_function(arg):
pdb.set_trace()
# ...
return result
my_function('test')
6.2.2 调试过程中的问题定位和解决
调试过程中,重要的是定位问题的源头。通常需要查看变量的值、执行流程、调用堆栈等信息。比如,当遇到一个未捕获的异常时,可以使用 pdb 查看引发异常的位置和上下文环境。
6.3 性能分析和优化
性能分析关注程序的运行时间和资源消耗。Python自带了一些工具来进行性能分析,比如 cProfile 和 line_profiler 。
6.3.1 性能分析工具的使用
cProfile 是Python的一个性能分析器。它可以记录程序执行过程中每个函数的调用次数和消耗时间。使用 cProfile 的方式很简单,可以在命令行中直接使用。
python -m cProfile -s time your_script.py
这个命令将运行 your_script.py ,并以时间(time)作为排序标准输出分析结果。 -s 参数表示按照什么标准排序,还可以是 calls (调用次数)。
6.3.2 代码优化策略和最佳实践
代码优化通常需要根据性能分析的结果来进行。以下是一些通用的优化策略:
- 减少不必要的计算和循环。
- 使用更高效的数据结构。
- 利用局部变量来避免多次查找全局变量。
- 使用生成器代替返回列表的函数,以节省内存。
- 对于递归函数,使用尾递归优化,或者通过迭代替代。
- 使用内建函数和库函数,它们通常经过优化且运行速度更快。
这些策略通常在性能分析后根据具体情况进行应用。在Python中,还应该特别注意全局解释器锁(GIL)对多线程程序性能的影响。
综上所述,测试、调试和性能优化是Python开发过程中确保代码质量的关键步骤。通过使用标准库中的工具,以及掌握一些最佳实践,开发人员可以有效地提升代码的健壮性和性能。在实际的项目开发中,将测试和调试集成到开发周期中,可以避免许多常见问题的发生,从而开发出更高质量的软件产品。
7. 综合应用案例分析
7.1 数据处理与可视化案例
数据处理与可视化是数据分析的重要组成部分,它允许我们从大量复杂的数据中提取信息,发现模式,验证假设,并将结果呈现给其他人。本节将探讨数据清洗和预处理的方法,以及数据可视化工具的使用和比较。
7.1.1 数据清洗和预处理的方法
数据清洗的目的是确保分析的质量。在数据准备阶段,可能会遇到不一致、缺失或错误的数据。数据预处理是分析前必不可少的一步。下面是一些常见的数据清洗和预处理技术:
- 缺失值处理 :对于缺失的数据,可以选择删除含有缺失值的记录、填充缺失值(如平均值、中位数、众数或基于模型的方法)或通过插值来估算缺失值。
- 异常值处理 :异常值可能是输入错误,也可能是正常的数据变异。对于异常值,可以考虑删除或替换,也可以使用箱线图或标准差来识别并处理。
- 数据转换 :将非数值型数据转换为数值型数据,例如,使用独热编码(One-Hot Encoding)或标签编码(Label Encoding)对分类变量进行编码。
- 数据标准化和归一化 :为了消除量纲影响,使数据具有可比性,常用的方法有标准化(Z-score Normalization)和最小-最大归一化(Min-Max Normalization)。
- 数据离散化 :将连续型特征分割成离散区间,使得特征的粒度更加细致,有助于模型更好地理解数据。
7.1.2 数据可视化工具的使用和比较
数据可视化工具使数据的表达更加直观,便于理解。在Python中,一些流行的数据可视化库包括Matplotlib、Seaborn、Plotly和Bokeh等。
- Matplotlib :这是Python中最常用的绘图库之一,提供了一套完整的绘图系统,可以自定义大部分图表元素,适用于创建静态、交互式和动画可视化图表。
- Seaborn :基于Matplotlib,提供了更高级的接口和更美观的默认设置。Seaborn擅长绘制统计图表,并对数据集之间的关系有很好的展示。
- Plotly :这是一个用于创建交互式图表的库,支持多种类型的图表,并能够输出为网页形式,适用于Web应用程序。
- Bokeh :类似Plotly,Bokeh也是一个用于创建交互式图表的库。它对大数据集的处理更为高效,且输出的图表可以在现代Web浏览器中运行。
代码示例 :
以下是使用Matplotlib库绘制一个简单的折线图的示例代码。
import matplotlib.pyplot as plt
# 横坐标数据
x = [1, 2, 3, 4, 5]
# 纵坐标数据
y = [2, 3, 5, 7, 11]
plt.plot(x, y)
plt.title("Simple Line Plot")
plt.xlabel("X Axis")
plt.ylabel("Y Axis")
plt.show()
为了实现数据可视化,首先需要安装Matplotlib库:
pip install matplotlib
在上述代码中, plt.plot(x, y) 函数用于绘制折线图, plt.title 、 plt.xlabel 和 plt.ylabel 分别用于设置图表标题和坐标轴标签。
7.2 Web开发实战
7.2.1 Web框架Django的基本使用
Django是一个高级的Python Web框架,它鼓励快速开发和干净、实用的设计。Django遵循MVC架构(模型-视图-控制器),但在实践中被描述为MTV架构(模型-模板-视图)。
Django项目的创建和运行
-
创建项目 :使用
django-admin工具创建新的Django项目。shell django-admin startproject myproject -
启动服务器 :进入项目目录,运行开发服务器。
shell cd myproject python manage.py runserver
Django模型的定义
在Django中,模型是一个Python类,表示数据库中的表。
from django.db import models
class Book(models.Model):
title = models.CharField(max_length=100)
author = models.CharField(max_length=100)
publish_date = models.DateField()
以上代码定义了一个 Book 模型,具有标题、作者和出版日期三个字段。
Django视图和URL路由
视图是处理Web请求并返回响应的函数或类。URL路由则是将URL映射到视图的机制。
from django.http import HttpResponse
from django.urls import path
from . import views
urlpatterns = [
path('', views.index, name='index'),
]
def index(request):
return HttpResponse("Hello, World!")
在本示例中, index 视图返回一个简单的文本响应。 urlpatterns 列表定义了一个路由,指向 index 视图。
7.3 自动化脚本编写
7.3.1 自动化脚本的需求分析和设计
自动化脚本的编写应从需求分析开始,分析潜在的重复性任务,然后设计解决方案。下面是一些步骤:
- 识别任务 :确定需要自动化的任务和流程。
- 分析流程 :分解任务为更小的步骤,确定自动化脚本的边界。
- 选择工具 :根据任务的需求选择合适的编程语言和工具。
- 编写脚本 :按照设计实现自动化任务。
- 测试和部署 :在不同的环境中测试脚本,并正式部署到生产环境。
7.3.2 实际案例:自动化运维脚本的编写与应用
假设需要编写一个自动化脚本来备份网站的数据库,并将备份文件上传到远程服务器。
代码示例 :
import os
import paramiko
from datetime import datetime
# 本地数据库参数
local_db_params = {
'user': 'local_user',
'password': 'local_pass',
'db': 'local_db'
}
# 远程服务器参数
remote_server_params = {
'hostname': 'remote_host',
'port': 22,
'username': 'remote_user',
'password': 'remote_pass'
}
# 生成数据库备份文件名
timestamp = datetime.now().strftime('%Y%m%d%H%M%S')
backup_filename = f'database_backup_{timestamp}.sql'
# 连接本地数据库并备份
local_db_conn = # 连接本地数据库的代码
# 生成备份SQL语句的代码
local_db_conn.export_data(backup_filename)
# 通过SSH连接到远程服务器并上传文件
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect(**remote_server_params)
# 创建SFTP会话
sftp = ssh.open_sftp()
sftp.put(backup_filename, f'/remote/path/{backup_filename}')
sftp.close()
# 关闭SSH连接
ssh.close()
# 清理本地备份文件
os.remove(backup_filename)
在实际编写脚本时,需要安装 paramiko 库:
pip install paramiko
上述脚本包括连接到本地数据库备份数据,通过SSH安全传输备份文件到远程服务器,并清理本地产生的备份文件。这是一个基础案例,实际应用中需要考虑错误处理和日志记录等更多的细节。
简介:在Python编程学习中,思维导图能够帮助学习者系统化地理解和记忆复杂概念和语法。本压缩包文件包含了Python基础语法、函数与模块、面向对象编程、高级特性、实战应用以及测试和调试等多个方面的思维导图,为初学者和进阶者提供了全面的学习辅助工具。通过结构化的展现方式,学习者可以清晰地掌握各个知识点,提高学习效率,并在实际项目中应用所学技能。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐



 4
4 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)