PSO优化SVM实现时间序列预测:从理论到实践
SVM旨在寻找一个最优超平面,将不同类别的数据点尽可能分开,在时间序列预测中,它通过对历史数据的学习,建立模型来预测未来的值。其核心在于核函数的选择,常见的有线性核、多项式核、径向基核(RBF)等。例如在Python的sklearn# 简单示例数据,x为特征,y为目标值# 创建SVR对象,使用RBF核函数,这里的C和gamma是需要调优的参数# 预测新值print("预测值:", predicte
PSO优化SVM做时间序列预测分析,代码内注释详细,直接替换数据就可以使用
在数据挖掘和预测领域,时间序列预测一直是个热门话题。支持向量机(SVM)以其出色的泛化能力在时间序列预测中有着广泛应用。然而,SVM的参数选择对预测结果影响较大,而粒子群优化算法(PSO)可以很好地解决参数寻优问题。下面就一起来看看如何用PSO优化SVM进行时间序列预测。
1. 原理简介
1.1 支持向量机(SVM)
SVM旨在寻找一个最优超平面,将不同类别的数据点尽可能分开,在时间序列预测中,它通过对历史数据的学习,建立模型来预测未来的值。其核心在于核函数的选择,常见的有线性核、多项式核、径向基核(RBF)等。例如在Python的sklearn库中,使用RBF核函数的SVM回归示例代码如下:
from sklearn.svm import SVR
import numpy as np
# 简单示例数据,x为特征,y为目标值
x = np.array([[1], [2], [3], [4], [5]])
y = np.array([2, 4, 6, 8, 10])
# 创建SVR对象,使用RBF核函数,这里的C和gamma是需要调优的参数
svr_rbf = SVR(kernel='rbf', C=1e3, gamma=0.1)
svr_rbf.fit(x, y)
# 预测新值
new_x = np.array([[6]])
predicted_value = svr_rbf.predict(new_x)
print("预测值:", predicted_value)在这段代码中,SVR(kernel='rbf', C=1e3, gamma=0.1) 初始化了一个使用RBF核的SVM回归器,C是惩罚参数,控制对错分样本的惩罚程度,gamma是核函数的系数,影响模型的复杂度。
1.2 粒子群优化算法(PSO)
PSO模拟鸟群觅食行为,每个粒子代表问题的一个潜在解,粒子在解空间中飞行,通过追踪自身历史最优位置(pbest)和群体历史最优位置(gbest)来更新自己的位置和速度。以下是简单的PSO更新位置和速度的公式伪代码:
# 假设粒子维度为D,种群大小为N
# v[i][j] 表示第i个粒子在第j维的速度
# x[i][j] 表示第i个粒子在第j维的位置
# pbest[i][j] 表示第i个粒子在第j维的历史最优位置
# gbest[j] 表示全局最优位置在第j维的值
# w 是惯性权重,c1、c2是学习因子
for i in range(N):
for j in range(D):
r1 = random()
r2 = random()
v[i][j] = w * v[i][j] + c1 * r1 * (pbest[i][j] - x[i][j]) + c2 * r2 * (gbest[j] - x[i][j])
x[i][j] = x[i][j] + v[i][j]这里,w决定了粒子对当前速度的继承程度,c1和c2则控制粒子向自身历史最优和全局最优位置靠近的程度。
2. PSO优化SVM实现时间序列预测代码
import numpy as np
from sklearn.svm import SVR
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
# 粒子群优化算法部分
class PSO:
def __init__(self, n_particles, dim, w, c1, c2, bounds, max_iter):
self.n_particles = n_particles # 粒子数量
self.dim = dim # 粒子维度,这里对应SVM的C和gamma两个参数,所以dim为2
self.w = w # 惯性权重
self.c1 = c1 # 学习因子1
self.c2 = c2 # 学习因子2
self.bounds = bounds # 参数边界
self.max_iter = max_iter # 最大迭代次数
self.particles = np.random.uniform(bounds[0], bounds[1], (n_particles, dim))
self.velocities = np.zeros((n_particles, dim))
self.pbest = self.particles.copy()
self.pbest_fitness = np.full(n_particles, np.inf)
self.gbest = None
self.gbest_fitness = np.inf
def fitness(self, params):
C, gamma = params
svr = SVR(kernel='rbf', C=C, gamma=gamma)
svr.fit(X_train, y_train)
y_pred = svr.predict(X_test)
return mean_squared_error(y_test, y_pred)
def update(self):
for i in range(self.n_particles):
r1 = np.random.rand(self.dim)
r2 = np.random.rand(self.dim)
self.velocities[i] = self.w * self.velocities[i] + \
self.c1 * r1 * (self.pbest[i] - self.particles[i]) + \
self.c2 * r2 * (self.gbest - self.particles[i])
self.particles[i] = self.particles[i] + self.velocities[i]
# 边界检查
self.particles[i] = np.clip(self.particles[i], self.bounds[0], self.bounds[1])
fitness_value = self.fitness(self.particles[i])
if fitness_value < self.pbest_fitness[i]:
self.pbest_fitness[i] = fitness_value
self.pbest[i] = self.particles[i]
if fitness_value < self.gbest_fitness:
self.gbest_fitness = fitness_value
self.gbest = self.particles[i]
# 生成或读取时间序列数据部分,这里简单生成示例数据
time_series = np.array([10, 12, 15, 13, 16, 18, 20, 22, 25, 23])
X = np.array([[time_series[i]] for i in range(len(time_series) - 1)])
y = np.array([time_series[i + 1] for i in range(len(time_series) - 1)])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False)
# PSO参数设置
n_particles = 20
dim = 2
w = 0.7
c1 = 1.5
c2 = 1.5
bounds = (0.001, 1000)
max_iter = 50
pso = PSO(n_particles, dim, w, c1, c2, bounds, max_iter)
for _ in range(max_iter):
pso.update()
# 使用优化后的参数进行SVM预测
best_C, best_gamma = pso.gbest
svr_opt = SVR(kernel='rbf', C=best_C, gamma=best_gamma)
svr_opt.fit(X_train, y_train)
y_pred_opt = svr_opt.predict(X_test)
# 绘图展示预测结果
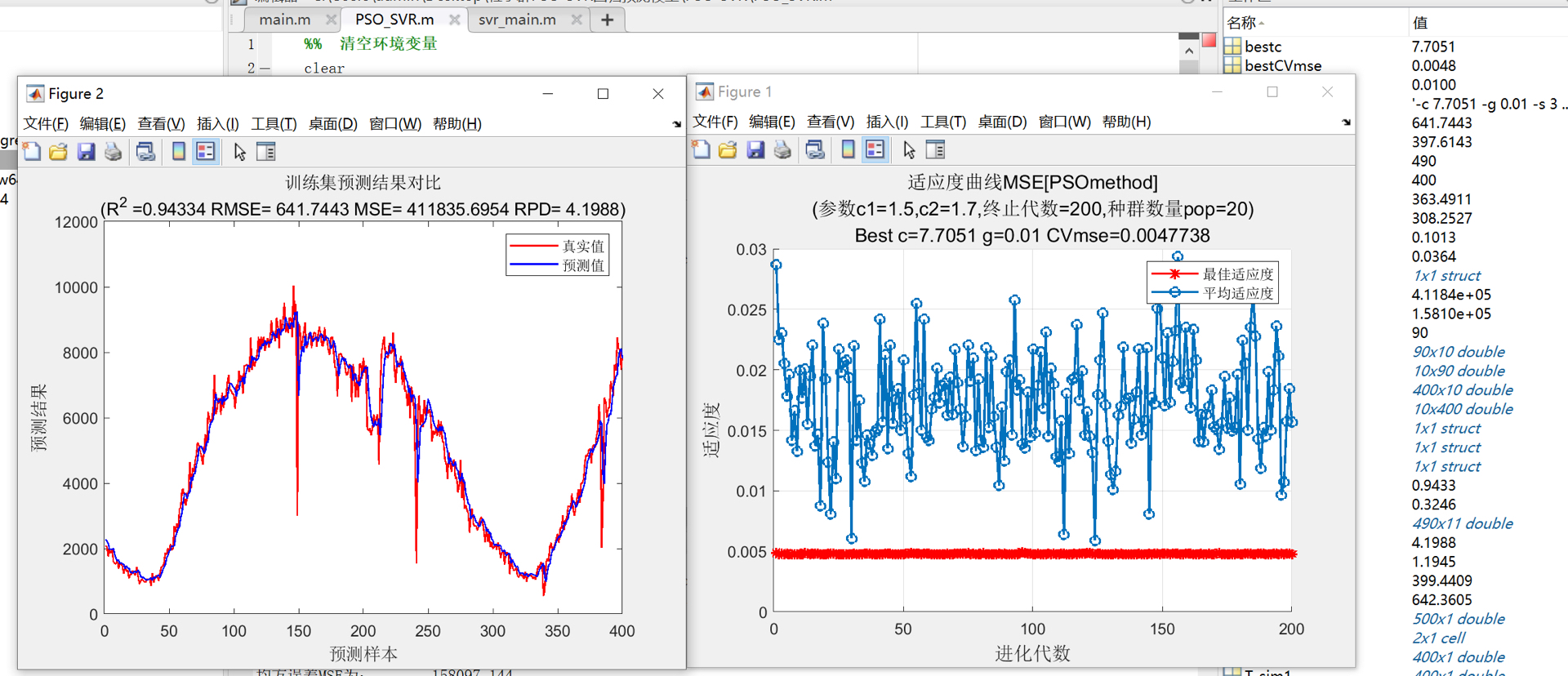
plt.plot(range(len(y_test)), y_test, label='真实值')
plt.plot(range(len(y_pred_opt)), y_pred_opt, label='预测值')
plt.legend()
plt.show()代码分析
- PSO类部分:
-init方法初始化了粒子群的各项参数,包括粒子数量、维度、惯性权重、学习因子、参数边界和最大迭代次数,并随机初始化粒子位置和速度,以及记录粒子和全局最优的变量。
-fitness方法用于计算每个粒子(即一组SVM参数)对应的模型均方误差,以此作为适应度值。
-update方法根据PSO公式更新粒子的速度和位置,同时进行边界检查,防止粒子超出设定范围,并更新粒子的历史最优位置和全局最优位置。 - 数据处理和模型训练部分:
- 这里简单生成了一个时间序列数据示例,并将其划分为训练集和测试集。实际使用中,你可以替换为真实的时间序列数据,只需要修改time_series变量即可。
- 设置PSO的各项参数并创建PSO对象,通过迭代更新找到最优的SVM参数C和gamma。
- 使用优化后的参数创建SVM模型并进行训练和预测,最后绘制真实值和预测值的对比图。
通过PSO优化SVM,我们能够在时间序列预测中获得更优的参数,从而提升预测性能。希望这篇博文能帮助你在时间序列预测的道路上更进一步!
PSO优化SVM做时间序列预测分析,代码内注释详细,直接替换数据就可以使用

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐

 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)