机器学习第五课之随机森林
随机森林作为集成学习的经典算法,通过多棵决策树的集体决策提升模型性能。本文系统介绍了随机森林的核心概念,包括样本和特征的双重随机性、决策树集成原理,以及关键参数如n_estimators、max_depth的调优策略。通过垃圾邮件分类案例,展示了从数据预处理、模型训练到特征重要性分析的全流程实现,使用100棵树、80%特征采样的配置取得了显著效果。文章特别强调了随机森林相比单棵决策树的优势:抗过拟
目录
简介:
如果你已经掌握了决策树的基本原理,那随机森林这颗 “升级版” 的 “树” 绝对值得你深入探究!作为集成学习中的经典模型,随机森林凭借 “多棵树投票” 的智慧,轻松解决了单棵决策树容易过拟合、泛化能力弱的问题。本博客作为 “机器学习第四课”,将用通俗易懂的语言拆解随机森林的核心逻辑:从 “为什么要随机采样样本和特征” 的底层原理,到 “多棵决策树如何协同工作” 的集成思路;从关键参数(如树的数量、最大深度、特征采样策略)的含义与调优技巧,到实际案例中如何用代码快速实现并评估模型性能。无论你是刚入门机器学习的新手,还是想深化集成学习理解的学习者,这篇教程都能让你清晰掌握随机森林的 “前世今生” 与实战要点,看懂它为何能成为工业界广泛应用的 “万能模型”。
一、随机森林相关概念
1.集成学习
- 任务⼀:如何优化训练数据 —> 主要⽤于解决⽋拟合问题
- 任务⼆:如何提升泛化性能 —> 主要⽤于解决过拟合问题
集成学习的应用:
- 1.分类问题集成
- 2.回归问题集成
- 3.特征选取集成
2.随机森林
什么是随机森林?
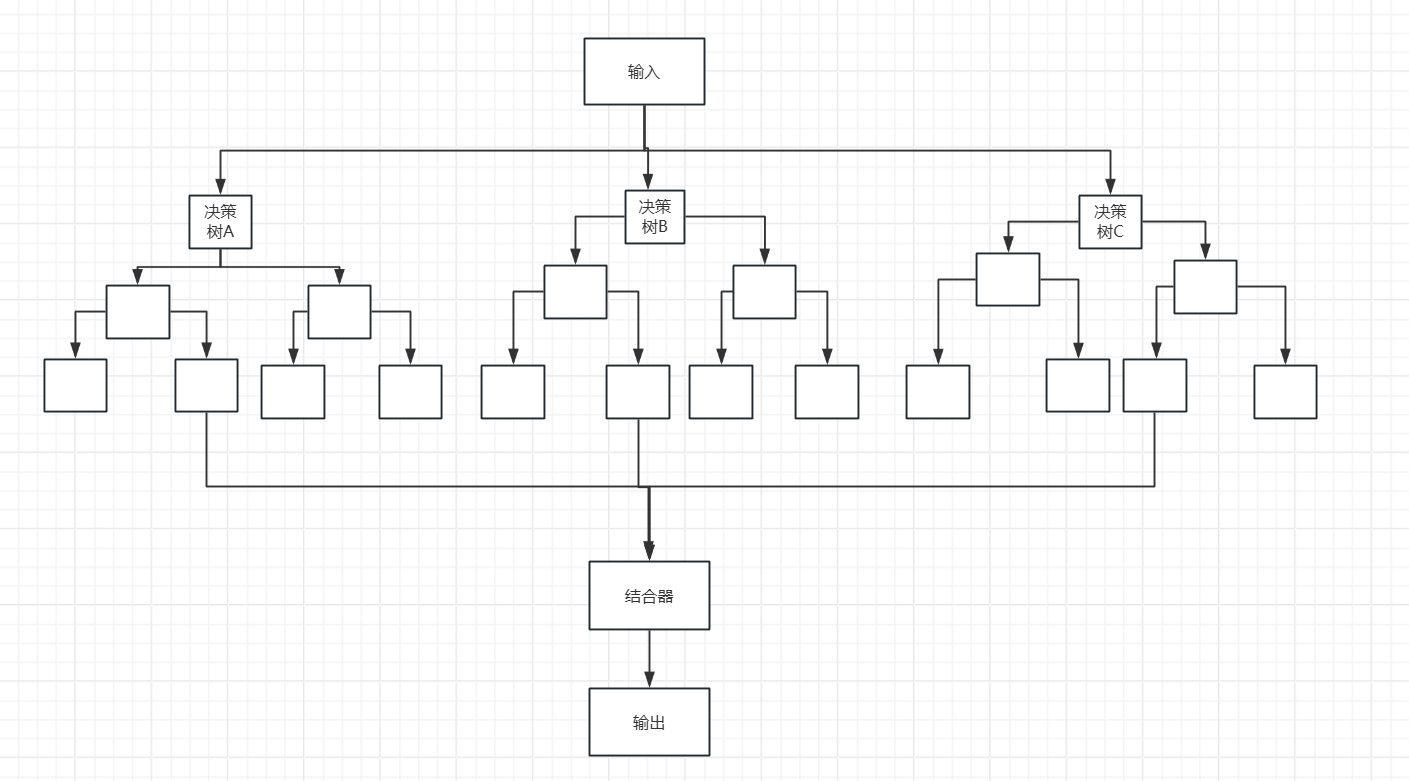
将多个决策树结合在一起,每次数据集是随机有放回的选出,同时随机选出部分特征作为输入,所以该算法被称为随机森林算法
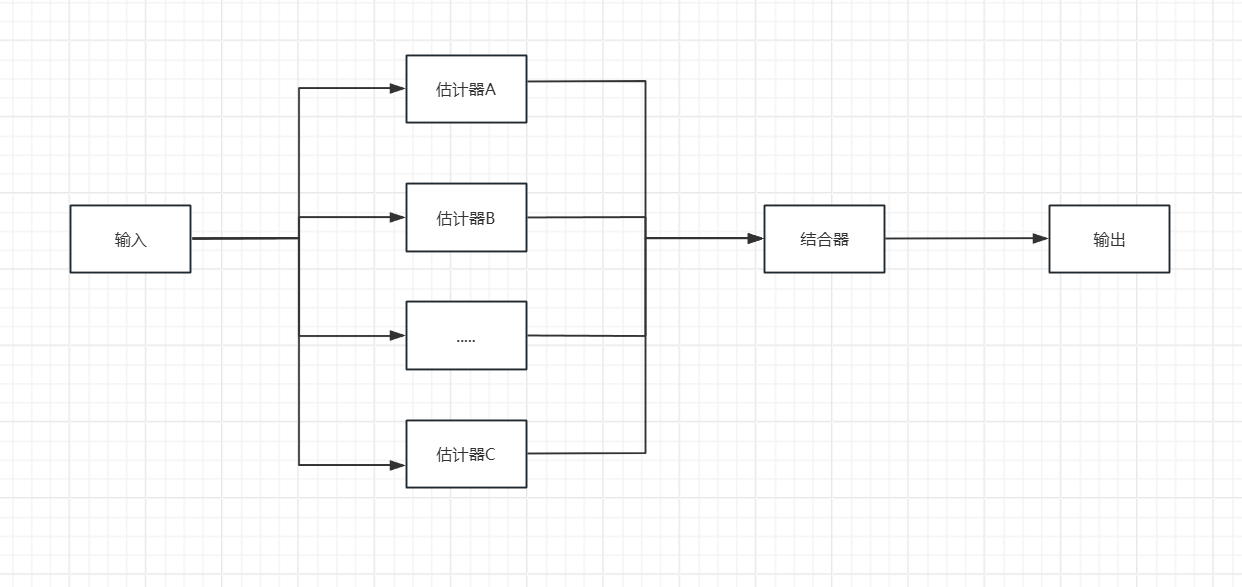
下图展示了随机森林算法的具体流程,其中结合器在分类问题中,选择多数分类结果作为最后的结果,在回归问题中,对多个回归结果取平均值作为最后的结果。
随机森林的特点:
- 数据采样随机
- 特征选取随机
- 森林
- 基分类器为决策树
每个单独的决策树不会学习到全部的数据,而是学习一部分的数据
3.随机森林的优缺点
优点:
1. 具有极高的准确率。
2. 随机性的引入,使得随机森林的抗噪声能力很强
3. 随机性的引入,使得随机森林不容易过拟合。
4. 能够处理很高维度的数据,不用做特征选择。
5. 容易实现并行化计算。
缺点:
1. 当随机森林中的决策树个数很多时,训练时需要的空间和时间会较大。
2. 随机森林模型还有许多不好解释的地方,有点算个黑盒模型。
二、随机森林的API
class sklearn.ensemble.RandomForestClassifier(n_estimators=’warn’,
criterion=’gini’, max_depth=None, min_samples_split=2, min_samples_leaf=1,
min_weight_fraction_leaf=0.0, max_features=’auto’, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True,
oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None)随机森林重要的一些参数:
1.n_estimators :(随机森林独有)
随机森林中决策树的个数。
在0.20版本中默认是10个决策树;
在0.22版本中默认是100个决策树;
2. criterion :(同决策树)
节点分割依据,默认为基尼系数。
可选【entropy:信息增益】
3.max_depth:(同决策树)【重要】
default=(None)设置决策树的最大深度,默认为None。
【(1)数据少或者特征少的时候,可以不用管这个参数,按照默认的不限制生长即可
(2)如果数据比较多特征也比较多的情况下,可以限制这个参数,范围在10~100之间比较好】
4.min_samples_split : (同决策树)【重要】
这个值限制了子树继续划分的条件,如果某节点的样本数少于设定值,则不会再继续分裂。默认是2.如果样本量不大,不需要管这个值。如果样本量数量级非常大,则建议增大这个值。
5.min_samples_leaf :(同决策树)【重要】
这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。 默认是1,可以输入最少的样本数的整数,或者最少样本数占样本总数的百分比。如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。
【叶是决策树的末端节点。 较小的叶子使模型更容易捕捉训练数据中的噪声。 一般来说,我更偏向于将最小叶子节点数目设置为大于50。在你自己的情况中,你应该尽量尝试多种叶子大小种类,以找到最优的那个。】
【比如,设定为50,此时,上一个节点(100个样本)进行分裂,分裂为两个节点,其中一个节点的样本数小于50个,那么这两个节点都会被剪枝】
6.min_weight_fraction_leaf : (同决策树)
这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝。 默认是0,就是不考虑权重问题。一般来说,如果我们有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们就要注意这个值了。【一般不需要注意】
7.max_features : (随机森林独有)【重要】
随机森林允许单个决策树使用特征的最大数量。选择最适属性时划分的特征不能超过此值。
当为整数时,即最大特征数;当为小数时,训练集特征数*小数;
if “auto”, then max_features=sqrt(n_features).
If “sqrt”, then max_features=sqrt(n_features).
If “log2”, then max_features=log2(n_features).
If None, then max_features=n_features.
【增加max_features一般能提高模型的性能,因为在每个节点上,我们有更多的选择可以考虑。 然而,这未必完全是对的,因为它降低了单个树的多样性,而这正是随机森林独特的优点。 但是,可以肯定,你通过增加max_features会降低算法的速度。 因此,你需要适当的平衡和选择最佳max_features。】
8.max_leaf_nodes:(同决策树)
通过限制最大叶子节点数,可以防止过拟合,默认是"None”,即不限制最大的叶子节点数。如果加了限制,算法会建立在最大叶子节点数内最优的决策树。如果特征不多,可以不考虑这个值,但是如果特征分成多的话,可以加以限制,具体的值可以通过交叉验证得到。
【比如,一颗决策树,如果不加限制的话,可以分裂100个叶子节点,如果设置此参数等于50,那么最多可以分裂50个叶子节点】
9.min_impurity_split:(同决策树)
这个值限制了决策树的增长,如果某节点的不纯度(基于基尼系数,均方差)小于这个阈值,则该节点不再生成子节点。即为叶子节点 。一般不推荐改动默认值1e-7。
10.bootstrap=True(随机森林独有)
是否有放回的采样,按默认,有放回采样
11. n_jobs=1:
并行job个数。这个在是bagging训练过程中有重要作用,可以并行从而提高性能。1=不并行;
n:n个并行;
-1:CPU有多少core,就启动多少job。
三、案例分析
这是一个基于随机森林的垃圾邮件分类模型,分析一个数据集:
数据集共有 4597 行 58 列数据
Word_freq_make-Word_freq_conference:表示各个单词在邮件中出现的频率。Char_freq1-Char_freq6:表示某些字符的出现频率。Capital_run_length_average:大写字母连续出现长度的平均值。Capital_run_length_longest:大写字母连续出现的最长长度。Capital_run_length_total:大写字母连续出现的总长度。label:是邮件的分类标签
导入所需库
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.ensemble import RandomForestClassifier #随机森林数据加载与预处理
data = pd.read_csv("spambase.csv")
x = data.iloc[:, :-1] # 提取所有行和除最后一列外的所有列作为特征
y = data.iloc[:, -1] # 提取最后一列作为目标变量(是否为垃圾邮件)数据集拆分
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.2, random_state=100
)随机森林模型训练与评估
estimator = RandomForestClassifier(
n_estimators=100, # 100棵决策树
max_features=0.8, # 每棵树使用80%的特征
random_state=0
)
estimator.fit(x_train, y_train) # 训练模型使用 100 棵决策树构建随机森林模型,每棵树随机使用 80% 的特征以增加多样性。
test_predicted = estimator.predict(x_test) # 在测试集上预测
score = estimator.score(x_train, y_train) # 计算训练集准确率
print(score)
# 输出详细分类报告(精确率、召回率、F1分数等)
print(metrics.classification_report(y_test, test_predicted))特征重要性分析
importances = estimator.feature_importances_ # 获取特征重要性
im = pd.DataFrame(importances, columns=["importances"])
# 处理特征名称
clos = data.columns
clos_1 = clos.values
clos_2 = clos_1.tolist()
clos = clos_2[0:-1] # 排除目标变量列
im['clos'] = clos可视化前 10 个重要特征
# 排序并取前10个最重要的特征
im = im.sort_values(by=['importances'], ascending=False)[:10]
# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False
# 绘制横向条形图
fig, ax = plt.subplots(figsize=(10, 8))
ax.barh(im['clos'], im['importances'], color='skyblue')
# 设置图表标题和标签
ax.set_title('特征重要性横向条形图(前10个特征)')
ax.set_xlabel('重要性得分')
ax.set_ylabel('特征名称')
plt.tight_layout()
plt.show()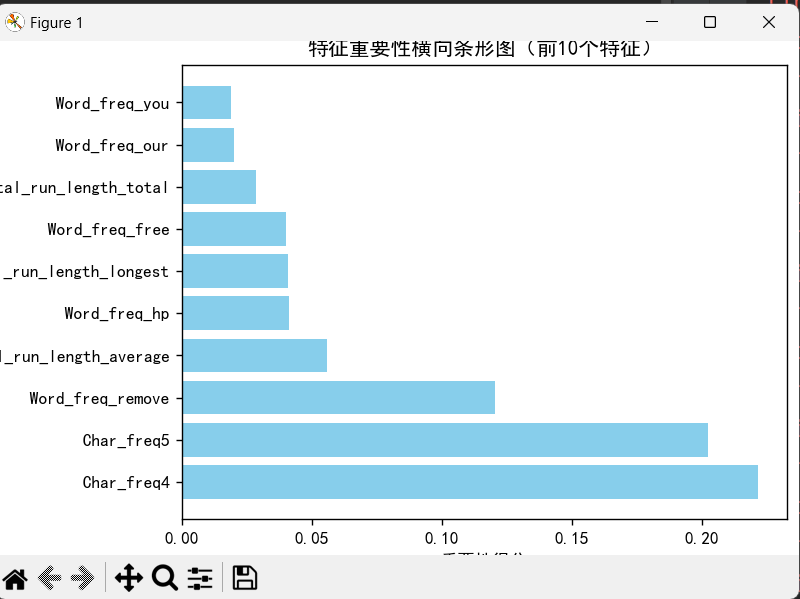
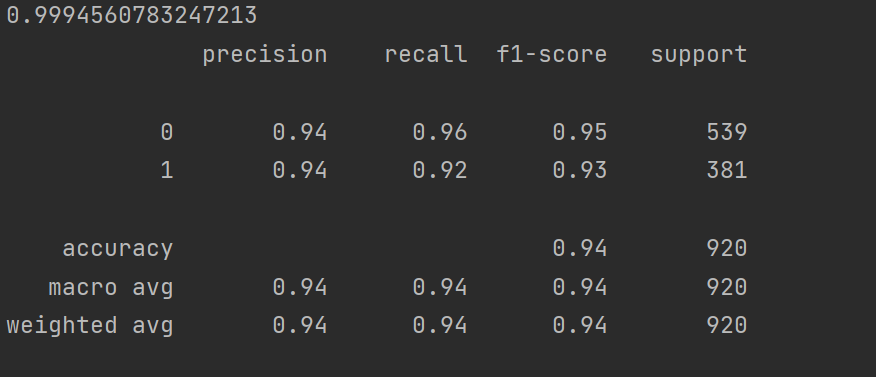
在结果上我们发现随机森林比决策树的准确率性能都比较突出。
完整代码
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.ensemble import RandomForestClassifier
data=pd.read_csv("spambase.csv")
x=data.iloc[:, :-1]
y=data.iloc[:, -1]
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=100)
estimator=RandomForestClassifier(n_estimators=100,
max_features=0.8,
random_state=0)
estimator.fit(x_train,y_train)
test_predicted=estimator.predict(x_test)
score=estimator.score(x_train,y_train)
print(score)
print(metrics.classification_report(y_test,test_predicted))
importances = estimator.feature_importances_ # 这个属性保存了模型中特征的重要性
im = pd.DataFrame(importances, columns=["importances"])
# 获取特征列名(使用指定的处理方式)
clos = data.columns # 获取数据集中所有列名
clos_1 = clos.values # 转换为numpy数组
clos_2 = clos_1.tolist() # 转换为列表
clos = clos_2[0:-1] # 去掉最后一列(目标变量列)
im['clos'] = clos # 将处理后的特征名称添加到DataFrame
# 按重要性降序排序并取前10个特征
im = im.sort_values(by=['importances'], ascending=False)[:10]
# 设置中文字体
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False
# 创建图形和轴
fig, ax = plt.subplots(figsize=(10, 8))
# 使用barh绘制横向条形图
ax.barh(im['clos'], im['importances'], color='skyblue')
# 设置标题和标签
ax.set_title('特征重要性横向条形图(前10个特征)')
ax.set_xlabel('重要性得分')
ax.set_ylabel('特征名称')
# 调整布局
plt.tight_layout()
# 显示图形
plt.show()

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐


 34
34 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)