全链路压测核心技术:日志隔离体系化设计与实践
Serverless 与云原生日志隔离:云服务商提供开箱即用的日志隔离服务,例如通过 AWS Lambda extension 或 Kubernetes sidecar 模式,将隔离逻辑从业务容器中剥离,实现按需、弹性的日志处理,进一步优化压测期间的资源成本。例如,基于 NLP 的日志聚类模型,能够自动识别出未携带标记的压测日志,并进行动态隔离,使系统更具韧性。对于非核心、允许少量日志丢失的压测场
一、日志隔离的核心挑战与业务风险
在压测流量与真实流量混跑的场景下,日志若不加隔离,会直接从技术问题演变为业务风险。如下“三座大山”必须被高度重视:
1. 数据污染(Data Contamination)
-
问题描述:压测日志(包括 Metrics、Traces、Logs)被错误地写入生产存储,直接污染生产数据大盘,干扰核心业务指标的准确性,可能导致错误的商业决策。
-
业务风险:运营团队基于被污染的数据做出错误的营销决策;管理层无法准确评估系统健康度。
2. 服务雪崩(Service Avalanche)
-
问题描述:压测期间,日志量通常是日常的 10 倍甚至更高。海量压测日志未经分流,直接冲击下游的日志处理链路(如 ELK、Loki、Splunk),极易导致其存储、计算资源耗尽。
-
业务风险:某电商大促压测案例中,压测日志写爆生产 ELK 集群磁盘,导致生产环境的日志检索、监控告警彻底瘫痪长达 2 小时,直接引发生产故障。
3. 诊断失效(Diagnostic Failure)
-
问题描述:压测产生的海量 Trace ID 与生产 Trace ID 混杂在一起,形成巨大的噪声。当生产环境出现真实故障时,运维和研发人员难以在海量压测数据中定位到有效的故障链路,排障时间被无限拉长。
-
业务风险:系统 SLA(服务等级协议)因故障恢复时间(MTTR)过长而无法达标。
二、日志隔离的分层架构与方案选型
一个成熟的日志隔离体系,应采用分层设计的思想。我们将隔离方案划分为四个层次,各层方案可独立实施,也可组合使用,以实现纵深防御。
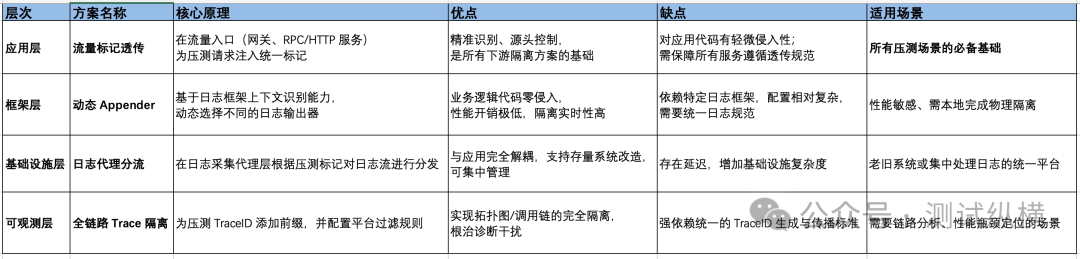
三、四大方案深度解析与实操代码
3.1 流量标记透传(应用层)
这是所有隔离方案的基石。核心是定义一个全局压测标记,并确保其在分布式系统中的所有服务间可靠传递。
-
标记规范:建议使用 HTTP Header 或 RPC Metadata,例如:
X-Stress-Test: true或 env: stress
-
实现方式:
1. 网关层注入
2. 应用内部 MDC或 ThreadLocal传递
3. 服务间透传(通过 OpenFeign、Dubbo 拦截器、OpenTelemetry 探针等)
// 示例:Spring MVC 拦截器,在入口将 Header 存入 MDCpublic class StressTestInterceptor implements HandlerInterceptor {public static final String STRESS_TEST_HEADER = "X-Stress-Test";public static final String STRESS_TEST_MDC_KEY = "stress_test";@Overridepublic boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) {String stressHeader = request.getHeader(STRESS_TEST_HEADER);if ("true".equalsIgnoreCase(stressHeader)) {MDC.put(STRESS_TEST_MDC_KEY, "true");}return true;}@Overridepublic void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) {MDC.remove(STRESS_TEST_MDC_KEY); // 请求结束时清理,防止内存泄漏}}
3.2 动态 Appender(框架层)
利用 Logback 强大的 SiftingAppender,可以实现优雅的动态分流。
-
原理:
SiftingAppender会根据MDC中的一个值(我们这里用stress_test)来动态创建和分发日志到不同的子 Appender。 -
实现示例 (Logback - logback.xml):
<configuration><appender name="PROD_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender"><file>/logs/application.log</file></appender><appender name="STRESS_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender"><file>/logs/stress_test.log</file></appender><appender name="SIFTER" class="ch.qos.logback.classic.sift.SiftingAppender"><discriminator><key>stress_test</key><defaultValue>prod</defaultValue> </discriminator><sift><appender name="FILE-${stress_test}" class="ch.qos.logback.core.FileAppender"><file>/logs/stress-${stress_test}.log</file> <layout class="ch.qos.logback.classic.PatternLayout"><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern></layout></appender></sift></appender><root level="INFO"><appender-ref ref="SIFTER" /></root></configuration>
3.3 日志代理分流(基础设施层)
当无法改造应用时,这是最后的防线。
-
架构流程:
应用日志文件 → Filebeat (附加标记) → Kafka/Logstash (过滤分流) → 压测 ES 集群 / 生产 ES 集群 / 直接丢弃 -
企业实践:
Filebeat 配置 (
filebeat.yml):在 Agent 端附加字段。
Filebeat 示例配置:
filebeat.inputs:- type: logpaths:- /path/to/your/app.logprocessors:- script:lang: javascriptsource: >function process(event) {var message = event.Get("message");if (message.includes("STRESS-TRACE")) {event.Put("tags", ["stress_test"]);}}
Logstash 配置 (logstash.conf): 根据标记进行管道分流。
input { kafka { topics => ["all_logs"] } }filter {// 可选:如果Filebeat没打标,在这里用grok解析并添加标记}output {if "stress_test" in [tags] {// 方案A:写入独立的压测ES集群elasticsearch {hosts => ["http://stress-es-host:9200"]index => "stress-logs-%{+YYYY.MM.dd}"}} else {// 方案B:写入生产ES集群elasticsearch {hosts => ["http://prod-es-host:9200"]index => "prod-logs-%{+YYYY.MM.dd}"}}}
3.4 全链路 Trace 隔离 (可观测层)
-
方案要点:
1. TraceID 规范: 在压测流量的 TraceID 生成时,统一添加前缀,如
stress-。这通常在网关层的 OpenTelemetry/SkyWalking 插件中配置。2. 平台配置: 在 Grafana Tempo, Jaeger 或 SkyWalking UI 中,查询时利用该前缀进行过滤,或配置独立的数据源指向压测专用的 Trace 存储后端。
-
价值:
确保在查看分布式系统的服务依赖拓扑图和进行根因分析时,压测流量和生产流量的视图完全分离,互不干扰。
四、企业级落地混合架构与治理
单一方案往往不够,企业级落地需要的是一个结合了技术、成本、流程的混合架构。
4.1 推荐架构:标记透传 + 动态 Appender + 代理分流
这是一个兼顾性能、成本和健壮性的黄金组合:
-
标记透传(必选)
作为全链路识别的唯一事实标准。
-
动态 Appender(推荐)
在应用内部实现第一层物理隔离。对于非核心、允许少量日志丢失的压测场景,甚至可以直接配置一个 NullAppender,在本地就将压测日志丢弃,实现极致的成本节约和性能提升。
-
代理分流(兜底)
作为中心化的第二道防线,处理未改造应用或 Appender 配置错误的“漏网之鱼”,确保没有一滴压测日志能污染生产存储。
4.2 日志存储优化:成本控制
-
冷热分离策略:使用 Elasticsearch 的 ILM(Index Lifecycle Management)策略
-
热节点(Hot):压测日志保留 24 小时,使用高性能 SSD,满足实时查询需求。
-
冷节点(Cold):超过 24 小时后,自动迁移至低成本的 HDD 节点或对象存储(如 S3、MinIO)。
-
删除(Delete):超过 7 天后自动删除,释放空间。
-
-
高效压缩算法
在日志框架或代理端,使用 ZSTD 替代默认的 Gzip。ZSTD 在同等 CPU 开销下,通常能提供比 Gzip 高 20–50% 的压缩比和更快的压缩解压速度,显著降低存储和网络成本。
4.3 监控告警隔离:避免“狼来了”
-
Prometheus 隔离抓取
为压测实例添加特定的 label(如 env: stress),并在 Prometheus scrape_config中使用 relabel_configs创建专门的 Job,仅抓取带有该标签的目标。
- job_name: 'stress_test_services'scrape_interval: 15smetrics_path: '/actuator/prometheus'kubernetes_sd_configs:- role: podrelabel_configs:- source_labels: [__meta_kubernetes_pod_label_env]regex: 'stress'action: keep
-
告警策略隔离
在 Alertmanager 中配置独立的告警路由,将来自 job: stress_test_services的告警发送到压测专用通道(如临时钉钉群、Slack 频道),避免打扰生产 On-Call。
同时为压测告警设置更高的错误率和延迟阈值。
4.4 故障演练与红线治理
日志隔离体系必须经过验证才能信任。
-
混沌工程演练
-
场景 1:标记丢失演练。模拟某个核心服务丢失压测标记透传逻辑,观察日志代理层是否能成功兜底并告警。
-
场景 2:日志风暴演练。模拟压测日志量瞬时增大 100 倍,测试 Kafka Topic 是否扩容及时、Logstash 是否能稳定运行。
-
-
红线指标与自动化卡点
-
压测日志误写率 < 0.001%:通过抽样比对生产与压测日志库,持续度量。
-
日志分流延迟 < 500ms:度量从日志产生到写入正确存储的时间。
-
自动化检查:在 CI/CD 流程中加入静态代码扫描,检测是否破坏 MDC 传递规则;或在预发环境中自动测试日志隔离效果。
-
五、总结与展望
日志隔离并非一次性的技术改造,而是一项需要体系化设计、分层防御、持续治理的架构级工程。成功的关键在于建立起从标记规范、应用框架、基础设施到可观测平台的端到端协同机制。
未来展望:
-
AIOps 驱动的智能隔离:从依赖固定规则,走向利用机器学习模型自动识别日志模式。例如,基于 NLP 的日志聚类模型,能够自动识别出未携带标记的压测日志,并进行动态隔离,使系统更具韧性。
-
基于 eBPF 的零侵入隔离:利用 eBPF(Extended Berkeley Packet Filter)技术,在操作系统内核层面无侵入地拦截应用的网络调用和 write 系统调用,识别并重定向压测日志流,实现对应用的“零”改造和“零”性能损耗的终极隔离方案。
-
Serverless 与云原生日志隔离:云服务商提供开箱即用的日志隔离服务,例如通过 AWS Lambda extension 或 Kubernetes sidecar 模式,将隔离逻辑从业务容器中剥离,实现按需、弹性的日志处理,进一步优化压测期间的资源成本。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 14
14 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)