RN&OpenHarmony:本地化MQTT同行通信(系列二)-架构与消息流
迎加入开源鸿蒙PC社区:https://harmonypc.csdn.net/
延续系列一,这篇我们深入聊聊架构设计、主题命名、QoS 选择、会话管理这些“硬核”内容。还是用“客户端 SDK / 服务端 SDK”作为代称,避免暴露真实项目名称。
说实话,架构设计这块,我一开始也是“摸着石头过河”。主题怎么命名?QoS 怎么选?重连策略怎么定?这些问题看起来简单,但真正落地的时候,每个细节都能让你踩坑。
今天咱们就像老朋友聊天一样,把这些细节掰开揉碎了说清楚。
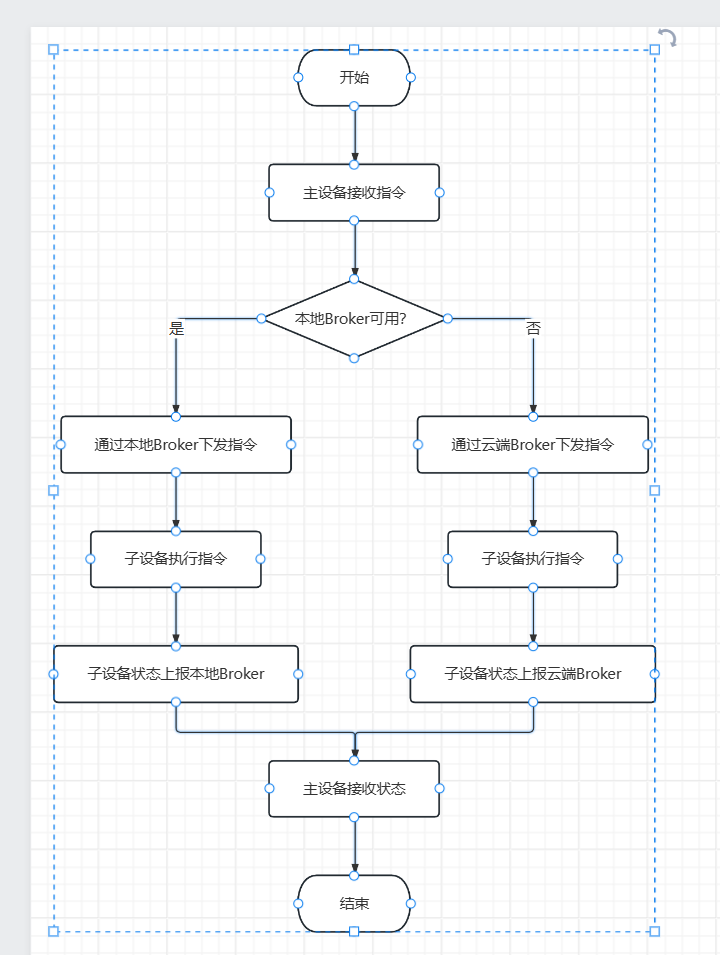
整体架构:本地优先,云端兜底
先看整体架构。我们的设计是“本地优先,云端兜底”,听起来简单,但实现起来要考虑很多细节。
Broker 的位置
Broker 可以内置于主设备/网关,也可以独立运行。内置的好处是部署简单,一个设备搞定;独立运行的好处是更灵活,可以单独升级 Broker。
我们选的是内置方案,因为我们的主设备本身就是一个网关,资源足够。如果你的主设备资源有限,可以考虑独立运行。
客户端 SDK 的职责
客户端 SDK 跑在主设备或者移动端 App 上,主要做这几件事:
- 连接到本地 Broker(或者云端 Broker,如果本地不可达)
- 订阅需要的主题(比如所有子设备的上报主题)
- 发布控制指令
- 管理连接状态(重连、保活、错误处理)
- 提供 UI 配置入口
服务端 SDK 的职责
服务端 SDK 跑在本地网关或者边缘节点上,主要做这几件事:
- 作为 Broker 的“代理层”,做主题路由
- 校验权限(订阅/发布权限)
- 消息转发(把主设备的指令转发给对应的子设备)
- 必要时透传到云端
云端的作用
云端不是摆设,它主要负责:
- 策略/配置下发(主题前缀、设备 ID、区域码等)
- 兜底通道(本地失败时自动切换)
- 历史数据存储和画像分析
主题设计:命名规范很重要
主题设计这块,我踩过最大的坑就是“命名太随意”。一开始我们主题命名很随意,后来发现不同设备类型、不同区域的主题混在一起,很难管理。
基本命名规范
我们的命名规范是这样的:
主设备下行:gateway/{gwId}/down
主设备上行:gateway/{gwId}/up
子设备下行:sub/{subId}/down
子设备上行:sub/{subId}/up
广播控制:broadcast/{model}/down
事件上报:event/{subId}/{eventType}
这样命名的好处是:
- 角色清晰:一看就知道是主设备还是子设备,是上行还是下行
- 设备可寻址:通过
{gwId}和{subId}可以精确定位到某个设备 - 支持广播:
broadcast/{model}/down可以同时控制同一型号的所有设备
版本和区域码
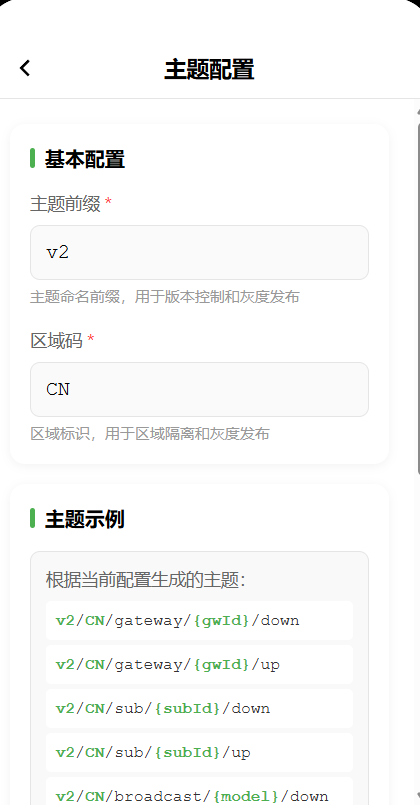
为了支持灰度发布和区域隔离,我们还加了版本号和区域码:
v2/{region}/gateway/{gwId}/down
v2/{region}/sub/{subId}/up
这样设计的好处是:
- 灰度发布:可以先让某个区域用新版本,其他区域还用旧版本
- 区域隔离:不同区域的主题不会互相干扰
- 平滑升级:可以逐步迁移,不需要一次性切换
避免硬编码
主题前缀、设备 ID、区域码这些,都不要硬编码在代码里。应该从配置接口获取:
// 不好的做法
const topic = `gateway/${deviceId}/down`; // 前缀写死了
// 好的做法
const config = await getConfigFromServer();
const topic = `${config.topicPrefix}/gateway/${deviceId}/down`;
这样如果以后要改前缀,或者要支持多区域,只需要改配置,不需要改代码。
QoS 选择:不是越高越好
QoS 这块,很多人有个误区:觉得 QoS 越高越好。其实不是这样的。QoS 越高,性能开销越大,要根据消息的重要性来选择。
QoS 0:最多一次(适合心跳和状态上报)
QoS 0 的特点是“发完就忘”,不保证送达,也不保证不重复。适合:
- 心跳消息(丢了就丢了,反正很快会再发一次)
- 高频状态上报(比如温度、湿度,偶尔丢一条不影响)
// 心跳用 QoS 0
client.publish('gateway/heartbeat', JSON.stringify({ timestamp: Date.now() }), { qos: 0 });
QoS 1:至少一次(适合控制指令)
QoS 1 保证至少送达一次,但可能会重复。适合:
- 控制指令(比如开灯、关灯)
- 关键状态上报(比如告警信息)
// 控制指令用 QoS 1
client.publish(`sub/${subId}/down`, JSON.stringify({ action: 'turnOn' }), { qos: 1 });
QoS 2:恰好一次(尽量少用)
QoS 2 保证恰好送达一次,但性能开销最大。我们基本不用,除非是特别关键的场景(比如支付、认证)。
我们的选择策略
- 心跳:QoS 0
- 状态上报:QoS 0(高频)或 QoS 1(关键)
- 控制指令:QoS 1
- 告警信息:QoS 1
Keepalive 和重连:细节决定成败
Keepalive 和重连这块,我踩过不少坑。Keepalive 设置不合理,网络稍微波动就断开;重连没有回退,很容易造成“重连风暴”。
Keepalive 设置
Keepalive 的作用是检测连接是否还活着。如果 Keepalive 时间内没有收到任何消息,Broker 会认为客户端已经断开。
我们的经验是:
- 局域网环境:30-60 秒比较合适
- 移动网络:可以适当延长到 60-120 秒
- Broker 超时时间:要设置为 Keepalive 的 1.5 倍,给网络波动留点缓冲
const options = {
keepalive: 60, // 60 秒
// Broker 的超时时间应该设置为 90 秒(60 * 1.5)
};
重连策略:指数回退 + 抖动
重连这块,最重要的是“不要立即重连”。如果连接失败,应该用指数回退:第一次等 1 秒,第二次等 2 秒,第三次等 4 秒...
但纯指数回退有个问题:如果多个客户端同时重连,可能会“同步”,造成“重连风暴”。所以还要加个随机抖动:
function calculateReconnectDelay(attemptCount) {
const baseDelay = Math.min(1000 * Math.pow(2, attemptCount), 60000); // 最多 60 秒
const jitter = Math.random() * 1000; // 0-1 秒的随机抖动
return baseDelay + jitter;
}
重连后自动重订阅
重连成功后,要自动重新订阅之前订阅过的主题。否则即使连接恢复了,也收不到消息。
const subscribedTopics = [];
client.on('connect', () => {
// 重连后自动重订阅
subscribedTopics.forEach(topic => {
client.subscribe(topic, { qos: 1 });
});
});
function subscribe(topic) {
client.subscribe(topic, { qos: 1 });
subscribedTopics.push(topic); // 记录下来
}
![> []](https://i-blog.csdnimg.cn/direct/36276717c48a4b28aa325c8d75daa78f.png)
会话管理:Clean Session 的选择
Clean Session 这块,很多人不太理解。简单说就是:如果 Clean Session = true,连接断开后,Broker 会删除这个客户端的会话信息(包括订阅的主题、未送达的消息等);如果 Clean Session = false,Broker 会保留这些信息,等客户端重连后恢复。
什么时候用 Clean Session = true?
- 临时性的客户端(比如移动端 App,每次打开都是新连接)
- 不需要保留订阅的场景(比如只发不发收)
什么时候用 Clean Session = false?
- 需要保留订阅的场景(比如子设备,重连后还要继续接收指令)
- 需要接收离线消息的场景(比如主设备,离线期间的指令要等上线后收到)
我们的策略是:
- 客户端 SDK:Clean Session = true(移动端 App,每次打开都是新连接)
- 服务端 SDK:Clean Session = false(网关设备,需要保留订阅)
状态持久化
除了 Broker 的会话管理,客户端自己也要做状态持久化。比如:
- 订阅的主题列表(重连后要重新订阅)
- 设备映射表(主设备和子设备的对应关系)
- 最后的状态(用于比对和校验)
可以用轻量级的 KV 存储(比如 AsyncStorage)或者内存缓存。
![> [截图占位:运行态面板(订阅列表、重连计数等)]](https://i-blog.csdnimg.cn/direct/aceda036fc694481a865d1d582917f66.png)
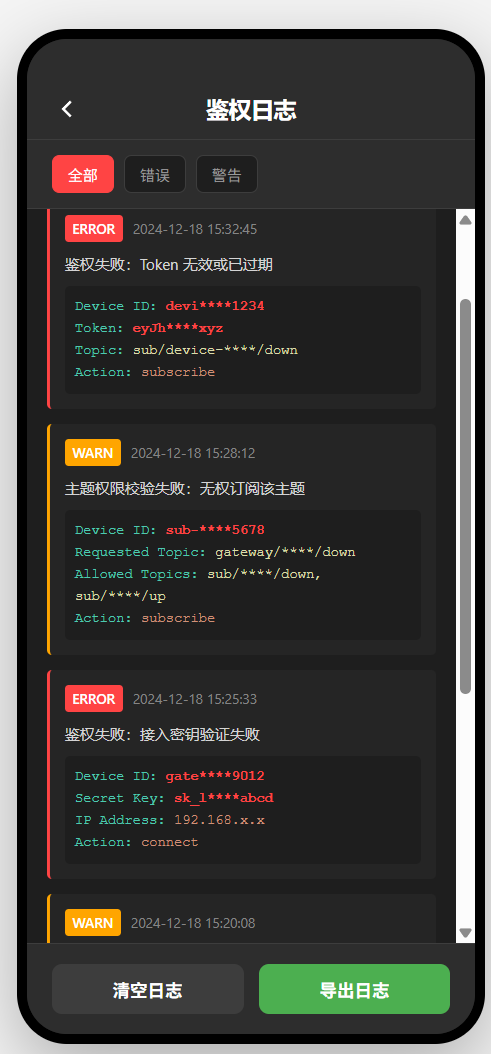
安全与鉴权:局域网也要安全
很多人觉得局域网是“内网”,不需要安全。其实不是这样的。局域网虽然相对安全,但还是要做基本的鉴权,防止恶意设备接入。
接入密钥
首次配对时,主设备和子设备要交换接入密钥。这个密钥要加密存储,不要明文存在代码里。
// 不好的做法
const secretKey = 'my-secret-key'; // 写死在代码里
// 好的做法
const secretKey = await secureStorage.get('secretKey'); // 从安全存储读取
Token 机制
除了接入密钥,还要有 Token 机制。Token 有有效期,过期后要自动刷新。如果网络断开,可以延用本地缓存的 Token。
let token = null;
let tokenExpireTime = 0;
async function getToken() {
const now = Date.now();
if (token && now < tokenExpireTime) {
return token; // 还在有效期内,直接用
}
// Token 过期了,重新获取
const response = await fetch('/api/token', {
method: 'POST',
headers: { 'Authorization': `Bearer ${secretKey}` }
});
const data = await response.json();
token = data.token;
tokenExpireTime = now + data.expiresIn * 1000;
return token;
}
主题鉴权
Broker 端要校验客户端是否有权限订阅/发布某个主题。比如:
- 子设备只能订阅自己的下行主题,不能订阅其他设备的主题
- 主设备可以订阅所有子设备的上行主题,但不能订阅其他主设备的主题
加密传输
如果硬件资源允许,建议用 TLS 加密。如果资源有限,至少要对敏感数据做签名,防止被篡改。
日志脱敏
日志里不要输出完整的设备 ID、Token、密钥。至少要打码:
function maskSensitiveData(str) {
if (str.length <= 8) return '****';
return str.substring(0, 4) + '****' + str.substring(str.length - 4);
}
console.log(`Device ID: ${maskSensitiveData(deviceId)}`);
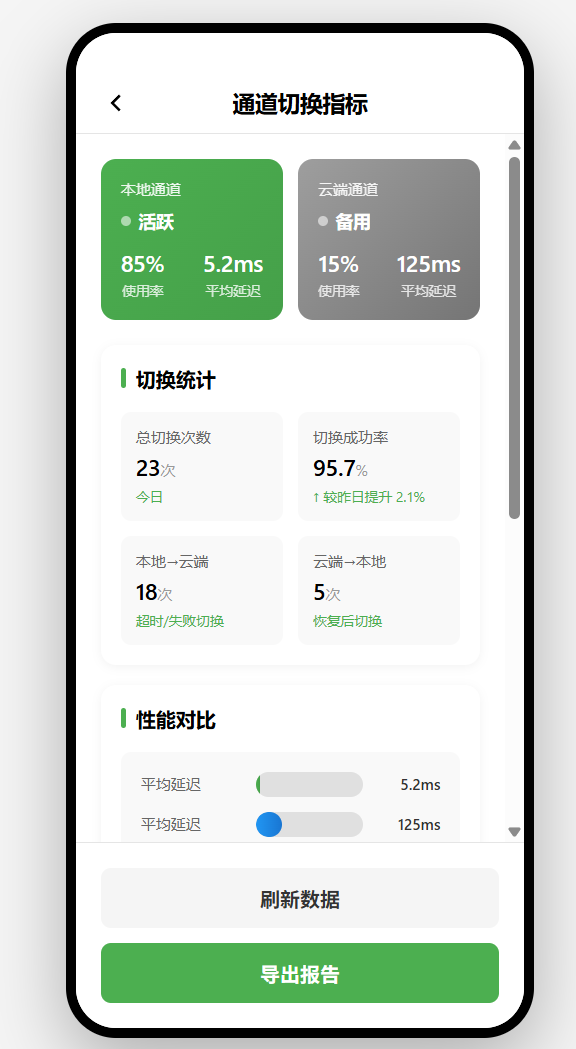
云端协同与降级:本地失败怎么办?
本地化不是完全脱离云端,而是“本地优先,云端兜底”。如果本地 Broker 不可达,要自动切换到云端。
并行通道
对于特别重要的控制指令,可以本地和云端同时发送,哪个先到用哪个:
async function sendCommand(deviceId, command) {
const promises = [
sendToLocalBroker(deviceId, command),
sendToCloudBroker(deviceId, command)
];
// 哪个先到用哪个
const result = await Promise.race(promises);
return result;
}
超时切换
如果本地发送超时(比如 500ms),自动切换到云端:
async function sendCommand(deviceId, command) {
try {
const result = await Promise.race([
sendToLocalBroker(deviceId, command),
new Promise((_, reject) => setTimeout(() => reject(new Error('timeout')), 500))
]);
return result;
} catch (error) {
// 本地超时,切换到云端
return await sendToCloudBroker(deviceId, command);
}
}
灰度策略
可以按区域、按版本动态切换 Broker 地址或 QoS:
const config = await getConfigFromServer();
const brokerAddress = config.region === 'CN' ? 'local-broker' : 'cloud-broker';
const qos = config.version >= 2 ? 1 : 0;
断网降级
如果网络完全断开,要保留最后一次的配置,确保基本控制还能用:
// 网络断开时,使用本地缓存的配置
const cachedConfig = await localStorage.get('lastConfig');
if (!cachedConfig) {
// 没有缓存,无法工作
throw new Error('No cached config available');
}
常见坑点:你以为很简单,其实...
坑一:主题命名不规范
一开始我们主题命名很随意,后来发现不同设备类型、不同区域的主题混在一起,很难管理。所以后来统一了规范,按角色、按区域、按版本分层。
坑二:QoS 选择不合理
很多人觉得 QoS 越高越好,其实不是。QoS 越高,性能开销越大。要根据消息的重要性来选择:心跳用 QoS 0,控制指令用 QoS 1,关键消息才用 QoS 2。
坑三:Keepalive 设置不合理
Keepalive 太短,网络稍微波动就断开;Keepalive 太长,设备真的掉线了也发现不了。我们的经验是:局域网 30-60 秒,移动网络 60-120 秒。
坑四:重连没有回退
如果连接失败,不要立即重连。应该用指数回退 + 抖动,否则很容易造成“重连风暴”。
坑五:没有做消息去重
MQTT QoS 1 保证至少送达一次,但可能会重复。关键指令要做去重,用请求 ID 或者时间戳。
总结一下
写这篇文章,其实就是想把架构设计、主题命名、QoS 选择、会话管理这些细节说清楚:
- 架构设计:本地优先,云端兜底。Broker 可以内置也可以独立运行,根据资源情况选择。
- 主题命名:按角色、按区域、按版本分层,避免硬编码,为后续扩展留空间。
- QoS 选择:不是越高越好,要根据消息的重要性选择。心跳用 QoS 0,控制指令用 QoS 1。
- Keepalive 和重连:Keepalive 要合理设置,重连要用指数回退 + 抖动,重连后要自动重订阅。
- 会话管理:临时客户端用 Clean Session = true,需要保留订阅的用 Clean Session = false。
- 安全与鉴权:局域网也要做基本的鉴权,接入密钥、Token、主题鉴权、日志脱敏都要做。
- 云端协同:本地失败要自动切换到云端,重要指令可以并行发送。
如果你对某个点特别感兴趣,可以看对应的章节。下一篇(系列三)我们会深入聊代码实现和性能优化,包括重连逻辑、消息队列、节流去抖这些细节。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)