OpenHarmony字符串最长公共前缀查找 | KMP实现
本文详细解析了最长公共前缀(LCP)问题的算法实现。该算法通过逐字符比较多个字符串,找出它们的共同前缀部分。核心实现包括输入解析模块、边界条件处理和双重循环比较结构。算法首先找到最短字符串长度,然后逐个位置比较所有字符串的字符,直到发现不匹配为止。代码还提供了详细的逐字符分析输出功能,帮助理解算法执行过程。这种算法适用于字符串预处理、路由匹配等场景,具有O(n*m)的时间复杂度,其中n是字符串数量
摘要
最长公共前缀(Longest Common Prefix)问题是字符串处理中的基础算法问题,用于查找多个字符串的共同前缀部分。本文详细解析基于逐字符比较的算法实现,包括输入解析、边界处理、逐字符匹配等核心功能的代码细节。
1. 算法背景
1.1 问题描述
给定一组字符串,找到它们的最长公共前缀(LCP)。公共前缀是指所有字符串都从开头匹配的部分。
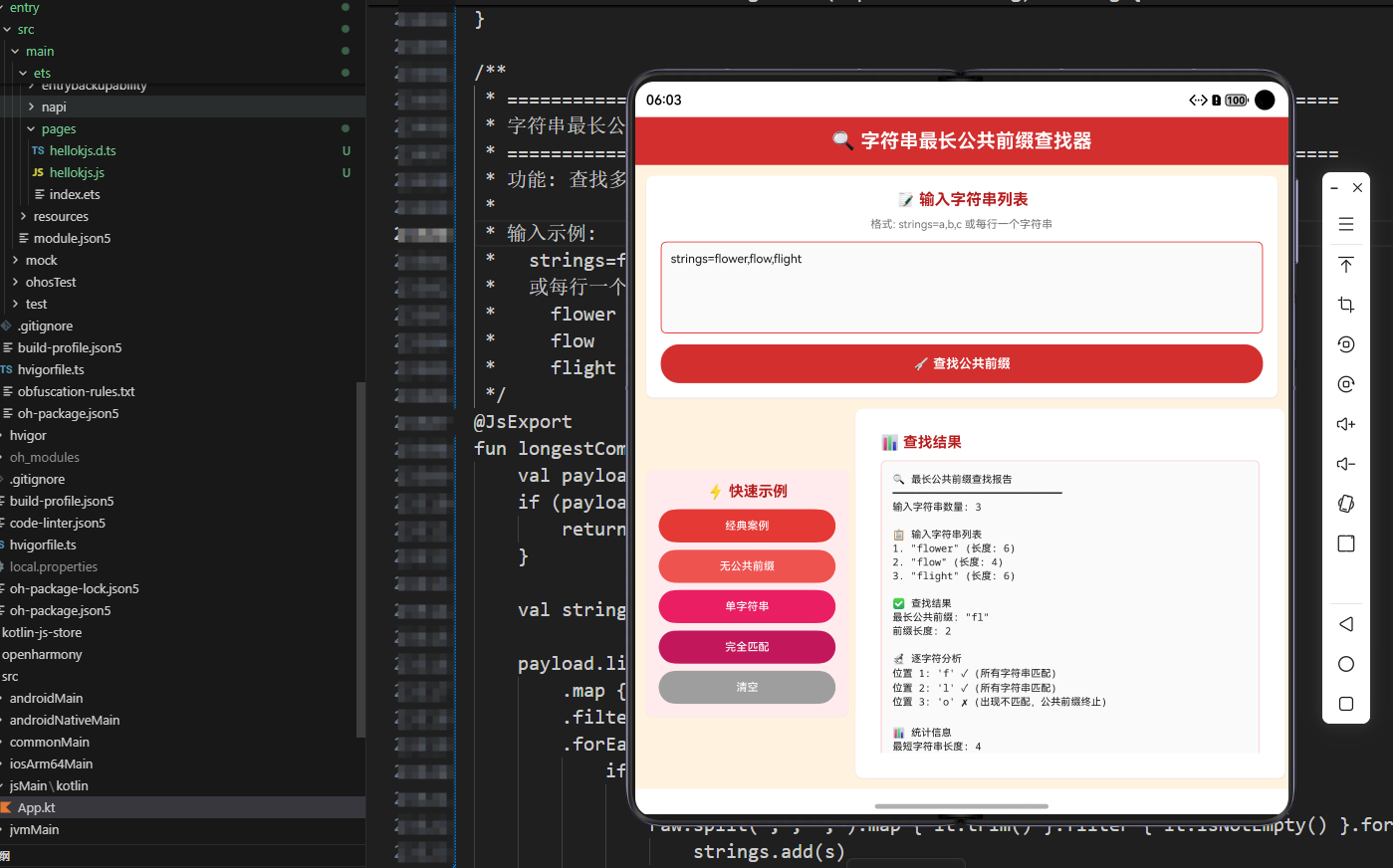
示例:
- 输入:
["flower", "flow", "flight"] - 输出:
"fl"(所有字符串都以 “fl” 开头)
1.2 应用场景
- 字符串集合预处理:数据库查询优化、索引构建
- 路由匹配:Web框架中的URL路由前缀匹配
- 自动补全:输入法的前缀提示功能
- 文件系统:查找文件路径的公共部分
2. 核心算法原理
使用逐字符比较的方法:
- 找到所有字符串中的最短长度
- 从第一个字符开始,逐位置比较所有字符串
- 如果某个位置所有字符串的字符都相同,继续下一个位置
- 如果出现不匹配,停止比较,返回当前已匹配的前缀
3. 代码实现详细解析
3.1 输入解析模块
val strings = mutableListOf<String>()
payload.lines()
.map { it.trim() }
.filter { it.isNotEmpty() }
.forEach { line ->
if (line.startsWith("strings=", ignoreCase = true)) {
val raw = line.substringAfter("=")
raw.split(",", ";").map { it.trim() }.filter { it.isNotEmpty() }.forEach { s ->
strings.add(s)
}
} else {
strings.add(line)
}
}
代码解析:
这段代码实现了灵活的输入解析机制,支持两种输入格式。首先创建一个可变的字符串列表 strings 用于存储解析结果。mutableListOf<String>() 创建了一个可变的列表,可以动态添加元素。
然后使用函数式编程风格处理输入:payload.lines() 将输入按行分割,map { it.trim() } 去除每行的首尾空白字符,filter { it.isNotEmpty() } 过滤空行,得到一个干净的字符串列表。
接着遍历每一行,使用条件判断处理不同的输入格式。如果行以 strings= 开头(忽略大小写),说明是键值对格式,使用 substringAfter("=") 提取等号后面的部分。然后使用 split(",", ";") 按逗号或分号分割字符串列表,支持多种分隔符。对分割后的每个部分使用 map { it.trim() } 去除空白,filter { it.isNotEmpty() } 过滤空字符串,最后通过 forEach 将所有有效的字符串添加到列表中。
如果行不是键值对格式,则直接将整行作为一个字符串添加到列表中。这种双重解析策略提高了用户体验,支持 strings=a,b,c 这样的单行格式,也支持每行一个字符串的多行格式。
3.2 边界条件处理
if (strings.isEmpty()) {
return "❌ 未解析到任何字符串,请检查格式:strings=a,b,c 或每行一个字符串"
}
if (strings.size == 1) {
builder.appendLine("单个字符串: \"${strings[0]}\"")
builder.appendLine("最长公共前缀: \"${strings[0]}\" (长度: ${strings[0].length})")
return builder.toString().trim()
}
代码解析:
这部分代码处理了算法的边界情况,体现了防御性编程的重要原则。边界条件处理是算法实现的关键环节,直接影响了代码的健壮性。
首先检查字符串列表是否为空。如果为空,说明输入解析失败,直接返回错误信息,避免后续处理出错。错误信息清晰地指出了正确的输入格式,帮助用户快速纠正错误。
然后处理单字符串的特殊情况。如果只有一个字符串,那么公共前缀就是这个字符串本身。这是一个合理的定义:单个字符串与自己的公共前缀就是它自己。代码提前返回,避免不必要的计算,提高了效率。输出信息清楚地说明了这是单字符串的情况,并直接给出结果。
这种提前返回的设计模式在算法实现中很常见,能够处理特殊情况并提高代码效率。
3.3 最长公共前缀查找核心函数
fun findLCP(strs: List<String>): String {
if (strs.isEmpty()) return ""
if (strs.size == 1) return strs[0]
val minLen = strs.minOfOrNull { it.length } ?: 0
if (minLen == 0) return ""
var prefixLen = 0
var foundMismatch = false
for (i in 0 until minLen) {
val char = strs[0][i]
for (j in 1 until strs.size) {
if (strs[j][i] != char) {
foundMismatch = true
break
}
}
if (foundMismatch) break
prefixLen++
}
return strs[0].substring(0, prefixLen)
}
代码解析:
这是算法的核心实现部分,使用嵌套循环逐字符比较所有字符串。函数首先进行边界检查:如果列表为空,返回空字符串;如果只有一个字符串,返回该字符串本身。这些检查确保了函数在各种输入情况下都能正确工作。
然后找到所有字符串中的最短长度 minLen。使用 minOfOrNull 函数安全地找到最小值,如果列表为空则返回 null,配合 Elvis 操作符 ?: 0 提供默认值 0。公共前缀的长度不可能超过最短字符串的长度,所以只需要比较到最短长度即可,这是一个重要的优化。
如果最短长度为 0(即存在空字符串),直接返回空字符串,因为空字符串不可能与其他字符串有公共前缀。
接下来是核心的双重循环结构。外层循环 for (i in 0 until minLen) 遍历每个字符位置,从第一个字符开始。until 关键字创建半开区间,不包含 minLen,正确遍历所有有效位置。
内层循环 for (j in 1 until strs.size) 从第二个字符串开始,将每个字符串在当前位置的字符与第一个字符串的字符比较。使用 strs[0][i] 获取第一个字符串在第 i 个位置的字符作为基准,strs[j][i] 获取第 j 个字符串在相同位置的字符进行比较。
如果发现不匹配(strs[j][i] != char),设置 foundMismatch = true 并立即跳出内层循环。这是算法优化的关键:一旦发现不匹配,就不需要继续比较其他字符串了,可以立即停止。
跳出内层循环后,检查是否发现了不匹配。如果发现,跳出外层循环,停止比较。如果没有发现不匹配,说明当前位置所有字符串的字符都相同,prefixLen++ 增加公共前缀长度。
最后,使用 strs[0].substring(0, prefixLen) 提取公共前缀。substring(0, prefixLen) 从第一个字符串的开头提取长度为 prefixLen 的子串,这就是所有字符串的公共前缀。
这个算法的核心思想是:公共前缀必须从所有字符串的开头开始,所以可以逐位置比较,一旦某个位置出现不匹配,就可以停止并返回之前匹配的部分。
3.4 逐字符分析输出
if (strings.size > 1 && lcp.isNotEmpty()) {
builder.appendLine("🔬 逐字符分析")
var commonUntil = 0
val minLen = strings.minOfOrNull { it.length } ?: 0
for (i in 0 until minLen) {
val char = strings[0][i]
var allMatch = true
for (j in 1 until strings.size) {
if (strings[j][i] != char) {
allMatch = false
break
}
}
if (allMatch) {
commonUntil = i + 1
builder.appendLine("位置 ${i + 1}: '$char' ✓ (所有字符串匹配)")
} else {
builder.appendLine("位置 ${i + 1}: '$char' ✗ (出现不匹配,公共前缀终止)")
break
}
}
}
代码解析:
这段代码实现了详细的逐字符分析输出功能,帮助用户理解算法的执行过程。首先检查是否有多个字符串且公共前缀非空,只在满足条件时显示详细分析。
然后重新计算最短长度,虽然前面已经计算过,但这里为了代码的独立性和清晰性,重新计算一次。这种设计虽然有一些重复,但使代码更模块化,更容易理解和维护。
接下来使用双重循环结构,与核心算法类似,但这里是为了输出详细的比较过程。外层循环遍历每个字符位置,内层循环比较所有字符串在该位置的字符。
使用 allMatch 标志位记录当前位置是否所有字符串都匹配。遍历所有字符串,如果发现任何一个字符串在该位置的字符与第一个字符串不同,设置 allMatch = false 并跳出循环。
如果所有字符串都匹配,更新 commonUntil 为当前位置加 1(因为索引是 0-based,而输出使用 1-based),并输出匹配信息,使用 ✓ 符号表示匹配成功。
如果出现不匹配,输出不匹配信息,使用 ✗ 符号表示匹配失败,并说明公共前缀在此位置终止。然后立即跳出循环,因为后续位置已经不需要比较了。
这种详细的输出对于教学和调试非常有用,用户可以清楚地看到算法是如何逐字符比较并找到公共前缀的。
3.5 统计信息输出
val lengths = strings.map { it.length }
val minLength = lengths.minOrNull() ?: 0
val maxLength = lengths.maxOrNull() ?: 0
val avgLength = lengths.average()
builder.appendLine("最短字符串长度: $minLength")
builder.appendLine("最长字符串长度: $maxLength")
builder.appendLine("平均字符串长度: ${round2(avgLength)}")
builder.appendLine("公共前缀长度: ${lcp.length}")
if (lcp.isNotEmpty()) {
val prefixRatio = (lcp.length.toDouble() / minLength * 100).coerceAtMost(100.0)
builder.appendLine("前缀占比: ${round2(prefixRatio)}% (相对于最短字符串)")
}
代码解析:
这段代码生成详细的统计信息,帮助用户了解输入字符串的特征和公共前缀的情况。首先使用 map { it.length } 将字符串列表转换为长度列表,这是函数式编程的典型用法,简洁高效。
然后计算最小长度、最大长度和平均长度。minOrNull() 和 maxOrNull() 是 Kotlin 的安全版本,如果列表为空返回 null,配合 Elvis 操作符提供默认值 0。average() 方法直接计算平均值,返回 Double 类型。
输出这些统计信息,让用户了解输入数据的分布情况。特别是最短字符串长度,它决定了公共前缀的最大可能长度。
如果公共前缀非空,计算前缀占比。使用 lcp.length.toDouble() / minLength * 100 计算百分比,toDouble() 确保浮点数除法。coerceAtMost(100.0) 限制最大值为 100%,因为公共前缀长度不可能超过最短字符串长度,这个限制是防御性编程的体现,但理论上不会触发。
前缀占比提供了公共前缀相对于最短字符串的覆盖程度,是一个有用的指标。例如,如果占比为 80%,说明公共前缀覆盖了最短字符串的 80%,字符串集合的相似度较高。
4. 算法复杂度分析
4.1 时间复杂度
- 找到最短长度:O(n),n 为字符串数量
- 逐字符比较:O(m × n),m 为最短字符串长度,n 为字符串数量
- 总体时间复杂度:O(m × n)
最坏情况下需要比较所有字符,但可以通过提前终止优化。
4.2 空间复杂度
- 字符串列表:O(n × m),存储所有字符串
- 其他变量:O(1)
- 总体空间复杂度:O(n × m)
5. 算法优化建议
5.1 提前终止优化
当前实现已经使用了提前终止(发现不匹配立即退出),这是很好的优化。
5.2 分治法优化
可以使用分治法,将字符串列表分成两部分,分别找公共前缀,然后合并:
- 时间复杂度:O(m × n),但在某些情况下可以提前终止
- 空间复杂度:O(m × log n)(递归栈)
5.3 排序优化
先按字典序排序,只需要比较第一个和最后一个字符串的公共前缀:
- 时间复杂度:O(m × n + n log n)(排序占主导)
6. 应用场景扩展
- 最长公共后缀:反转字符串后找公共前缀
- 多个公共前缀:找到所有长度大于某个阈值的公共前缀
- 模糊匹配:允许一定数量的字符不匹配
7. 总结
最长公共前缀算法是字符串处理的基础算法,本文详细解析了算法的每个实现细节。核心要点:
- 逐字符比较:从第一个字符开始,逐位置比较所有字符串
- 最短长度限制:公共前缀长度不可能超过最短字符串长度
- 提前终止:发现不匹配立即停止,提高效率
- 边界处理:正确处理空列表、单字符串等特殊情况
通过深入理解代码实现,可以更好地应用这个算法解决实际问题,如路由匹配、自动补全、字符串集合分析等场景。
欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 27
27 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)