kmp openharmony 数据去重与唯一值统计
在数据处理和分析中,我们经常遇到这样的问题:
数据中存在重复值,如何去除?
如何统计每个唯一值出现的次数?
数据的重复程度如何衡量?
数据去重与唯一值统计 (Data Deduplication and Unique Value Statistics) 是数据处理的基础工具,通过去除重复值、统计唯一值及其出现次数,帮助我们了解数据分布特征,优化数据存储和分析效率。
本案例基于 Kotlin Multiplatform(KMP)与 OpenHarmony,实现了一个数据去重与唯一值统计器:
- 去除重复值:保留每个值的首次出现,生成去重后的序列;
- 统计唯一值出现次数:计算每个唯一值在原始序列中的出现次数;
- 计算去重率:衡量数据的重复程度;
- 识别最频繁值和最少出现值:发现数据分布特征;
- 通过 ArkTS 单页面展示原始序列、去重后序列、唯一值统计和分布摘要,帮助你直观理解数据去重效果。
一、问题背景与典型场景
典型场景包括:
-
日志去重
对系统日志、应用日志中的重复记录进行去重,减少存储空间,提高查询效率。 -
事件聚合
对监控事件、告警事件中的重复事件进行去重和聚合,避免重复告警,提高告警质量。 -
指标唯一值分析
统计监控指标中的唯一值及其分布,了解指标的取值范围和分布特征。 -
数据清洗
在数据预处理阶段,对重复数据进行去重,提高数据质量。 -
存储优化
通过去重减少数据存储空间,提高存储效率。
相比保留重复数据,数据去重的优势在于:
- 减少存储空间,提高存储效率;
- 减少计算量,提高分析效率;
- 避免重复处理,提高数据质量;
- 便于统计分析,了解数据分布。
二、Kotlin 数据去重引擎
1. 输入格式设计
本案例沿用统一的文本输入风格:
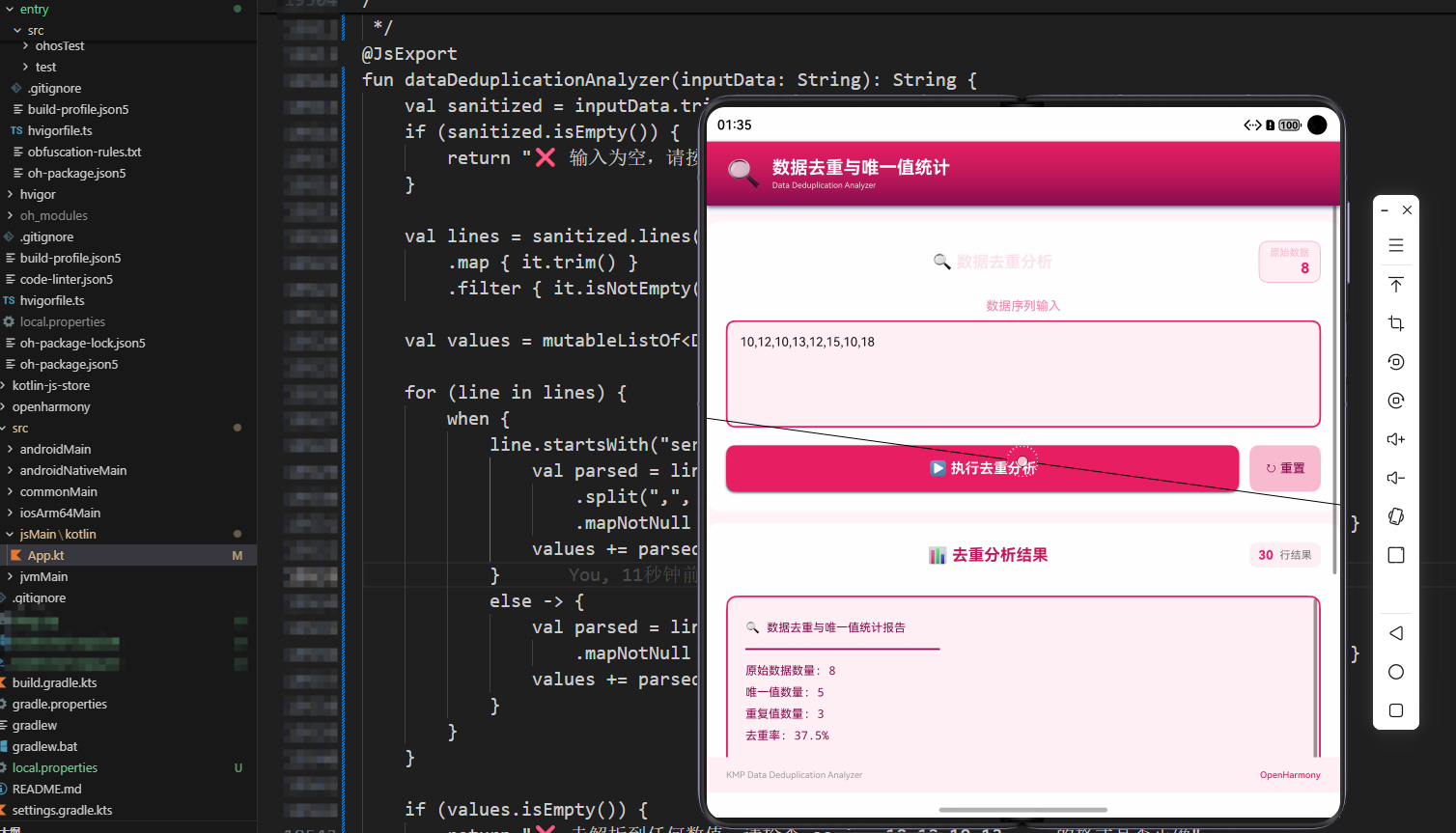
series=10,12,10,13,12,15,10,18
或直接输入数值序列:
10,12,10,13,12,15,10,18
2. 核心算法实现
在 App.kt 中,我们实现了 dataDeduplicationAnalyzer 函数:
@JsExport
fun dataDeduplicationAnalyzer(inputData: String): String {
// 1. 解析输入序列
val values = parseSeries(inputData)
// 2. 去重处理(保留首次出现)
val uniqueValues = values.distinct()
// 3. 统计每个值的出现次数
val valueCounts = mutableMapOf<Double, Int>()
for (value in values) {
valueCounts[value] = (valueCounts[value] ?: 0) + 1
}
// 4. 计算去重率
val duplicateCount = values.size - uniqueValues.size
val deduplicationRate = (duplicateCount.toDouble() / values.size) * 100.0
// 5. 识别最频繁值和最少出现值
val sortedCounts = valueCounts.toList().sortedByDescending { it.second }
val mostFrequent = sortedCounts.firstOrNull()
// 6. 生成报告
return buildReport(...)
}
3. 关键处理逻辑
去重处理:
- 使用
distinct()方法去除重复值 - 保留每个值的首次出现,保持原始顺序
- 时间复杂度:O(n),空间复杂度:O(n)
唯一值统计:
- 使用
Map<Double, Int>统计每个值的出现次数 - 遍历原始序列,累加每个值的计数
- 时间复杂度:O(n),空间复杂度:O(k),k 为唯一值数量
去重率计算:
- 公式:
去重率 = (重复值数量 / 原始数据数量) * 100% - 去重率越高,说明数据重复越多
- 去重率可以帮助评估去重的效果
三、OpenHarmony ArkTS 前端集成
1. 导入 Kotlin/JS 函数
在 index.ets 中导入:
import { dataDeduplicationAnalyzer } from './hellokjs'
2. 状态变量定义
@State seriesInput: string = "10,12,10,13,12,15,10,18"
@State result: string = ""
@State isLoading: boolean = false
3. 执行分析逻辑
executeDemo() {
this.isLoading = true
const seriesLine = this.seriesInput.includes('series=')
? this.seriesInput
: `series=${this.seriesInput}`
const payload = seriesLine
setTimeout(() => {
try {
this.result = dataDeduplicationAnalyzer(payload)
} catch (e) {
this.result = "❌ 执行失败: " + e.message
}
this.isLoading = false
}, 100)
}
4. UI 布局设计
- 顶部标题栏:使用渐变背景(粉色-红色主题),展示"数据去重与唯一值统计"标题
- 输入区域:单行文本输入框,支持
series=...格式或直接输入数值序列 - 执行按钮:运行分析按钮和重置按钮
- 结果展示区:使用 Scroll 组件展示分析报告,包括原始序列、去重后序列、唯一值统计和分布摘要
四、算法复杂度分析
- 时间复杂度:O(n),其中 n 为序列长度。需要遍历序列一次进行去重和统计。
- 空间复杂度:O(k),其中 k 为唯一值数量。需要存储唯一值集合和计数映射。
五、工程化应用建议
-
日志去重
对系统日志、应用日志中的重复记录进行去重,减少存储空间,提高查询效率。 -
事件聚合
对监控事件、告警事件中的重复事件进行去重和聚合,避免重复告警。 -
指标唯一值分析
统计监控指标中的唯一值及其分布,了解指标的取值范围和分布特征。 -
数据清洗
在数据预处理阶段,对重复数据进行去重,提高数据质量。 -
存储优化
通过去重减少数据存储空间,提高存储效率。 -
分布特征识别
通过唯一值统计,识别数据的高频值和低频值,了解数据分布特征。
六、总结
数据去重与唯一值统计是数据处理的基础工具,通过去除重复值、统计唯一值及其出现次数,帮助我们了解数据分布特征,优化数据存储和分析效率。本案例展示了如何在 KMP + OpenHarmony 架构下实现一个轻量级的数据去重与唯一值统计器,适用于日志去重、事件聚合、指标分析等场景。
核心优势:
- 实现简单,计算高效
- 结果直观,易于理解
- 适用广泛,可用于多种场景
- 提供丰富的统计信息
适用场景:
- 日志去重
- 事件聚合
- 指标唯一值分析
- 数据清洗
- 存储优化
通过本案例,你可以快速掌握数据去重与唯一值统计的核心思想,并在实际项目中灵活应用。
欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐


 27
27 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)