代码随想录 | Day12 | KC.替换数字 151.反转字符串中的单词 KC.右旋字符串 KMP算法 28.找出字符串中第一个匹配项的下标 459.重复的子字符串
再将各个单词依次反转去除空格时若使用erase,则会导致整个去除空格方法的时间复杂度为O(n^2)(erase时间复杂度为O(n) + for循环遍历),具体代码参考代码随想录对应章节为了尽可能减少时间复杂度,这里使用双指针的方法,快指针用于检索当前元素是否为空格,慢指针用于重构字符串时间复杂度:O(n)空间复杂度:O(1)
KC.替换数字
暴力解法
定义一个空字符串 result ,并对输入的字符串 s 遍历,若是数字,则 result 后加 "number",不是数字则加 s[i]
时间复杂度:O(n)
空间复杂度:O(n)
#include<bits/stdc++.h>
using namespace std;
int main()
{
string s;
cin >> s;
string result = "";
for (int i = 0; i < s.size(); i++)
{
if (s[i] >= '0' && s[i] <= '9') {
result += "number";
} else {
result += s[i];
}
}
cout << result;
return 0;
}双指针法
可以根据字符串中出现数字的次数来决定让原字符串扩容多少单元。
慢指针指向原字符串最后一位,快指针指向新字符串最后一位,从后往前替换数字字符,如图
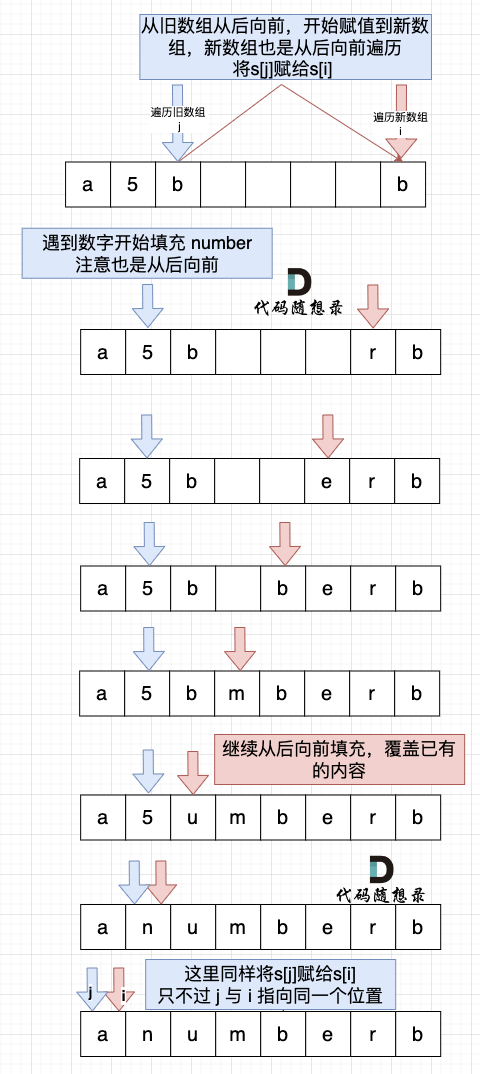
若从前往后遍历,由于需要将字符后移,时间复杂度就会变成O(n^2)
时间复杂度:O(n)
空间复杂度:O(1)
#include<bits/stdc++.h>
using namespace std;
int main()
{
string s;
cin >> s;
int count = 0; // 统计数字个数
int sOldIndex = s.size() - 1;
for (int i = 0; i < s.size(); i++)
{
if (s[i] >= '0' && s[i] <= '9') count++;
}
s.resize(s.size() + count * 5); // 扩容
int sNewIndex = s.size() - 1;
while (sOldIndex >= 0)
{
if (s[sOldIndex] >= '0' && s[sOldIndex] <= '9')
{
s[sNewIndex--] = 'r';
s[sNewIndex--] = 'e';
s[sNewIndex--] = 'b';
s[sNewIndex--] = 'm';
s[sNewIndex--] = 'u';
s[sNewIndex--] = 'n';
sOldIndex--;
}
else
{
s[sNewIndex] = s[sOldIndex];
sNewIndex--;
sOldIndex--;
}
}
cout << s << endl;
return 0;
}151.反转字符串中的单词
首先,将字符串中多余的空格全部去掉
其次,将字符串整体反转
最后,再将各个单词依次反转
去除空格时若使用erase,则会导致整个去除空格方法的时间复杂度为O(n^2)(erase时间复杂度为O(n) + for循环遍历),具体代码参考代码随想录对应章节
为了尽可能减少时间复杂度,这里使用双指针的方法,快指针用于检索当前元素是否为空格,慢指针用于重构字符串
时间复杂度:O(n)
空间复杂度:O(1)
class Solution {
public:
void reverse(string& s, int start, int end)
{
for (int i = start, j = end; i < j; i++, j--)
{
swap(s[i], s[j]);
}
}
void removeExtraSpaces(string& s) // 去除多余空格
{
int slow = 0; // 慢指针
for (int fast = 0; fast < s.size(); fast++) // 快指针检索到空格就前进
{
if (s[fast] != ' ') // 快指针检索到字母
{
if (slow != 0) s[slow++] = ' '; // 慢指针不指向开头,就先手动添加一个空格再赋字母。是开头就直接赋值
while (fast < s.size() && s[fast] != ' ') // 这个范围内快指针指向元素都是字母,就为慢指针依次赋值
{
s[slow++] = s[fast++];
}
}
}
s.resize(slow); // 停止循环时slow的值为新字符串的长度
}
string reverseWords(string s) {
removeExtraSpaces(s);
reverse(s, 0, s.size() - 1); // 先整体全部反转
int start = 0; // 记录每次反转单词的起始位置
for (int i = 0; i <= s.size(); i++) // 对各个单词反转,这里循环条件是 <= ,因为后面if判断需要i指向结尾后的元素
{
if (i == s.size() || s[i] == ' ') // 易错点:i == s.size()而不是s[i] == s.size()
{
reverse(s, start, i - 1); // 左闭右闭
start = i + 1; // 下次起始位置
}
}
return s;
}
};KC.右旋字符串
受上道题启发,这道题就变得很简单了,先将字符串整体反转,再分别反转左右两部分即为所需字符串
#include <bits/stdc++.h>
using namespace std;
int main()
{
int k;
cin >> k;
string s;
cin >> s;
reverse(s.begin(), s.end()); // 先整体反转
reverse(s.begin(), s.begin() + k); // 反转左边部分
reverse(s.begin() + k, s.end()); // 反转右边部分
cout << s;
return 0;
}注意reverse函数中第一个参数为起始位置,第二个参数为结束位置的后一个位置,即左闭右开
KMP算法
KMP算法是求解是否存在模式串问题的重要算法,而KMP算法最重要的就是求解next数组
这里采用最基本的方式,也就是既不统一右移也不统一减一的方式
例如模拟求解模式串 a a b a a f 的next数组 (即 0 1 0 1 2 0)
首先初始化 j = 0 ,next[0] = 0 ,从i = 1开始遍历循环(j 为前缀末尾,i 为后缀末尾)
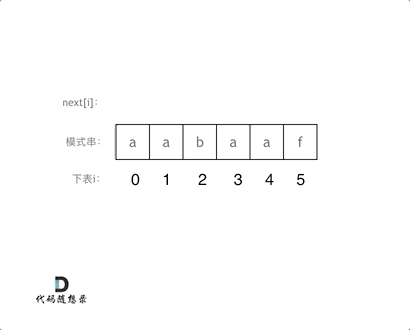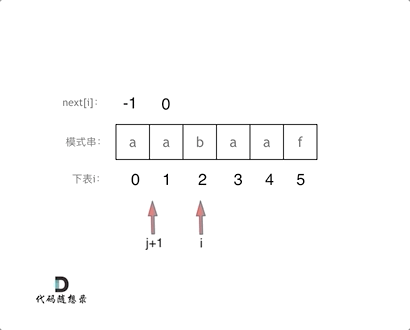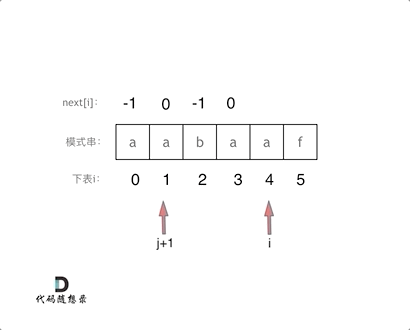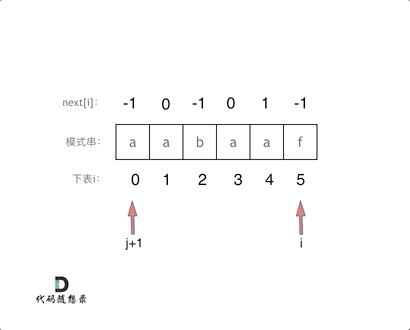
j = 0, i = 1 时,子串为 a a ,前缀为 a,后缀为 a, next[i] == next[j],则令 j++(j 为 1),然后next[i] = j(next[1] 为 1),表示 a a 的最长相等前后缀长度为1,也表示若 b 失配,则与 b 前面 a 位置的 next 值匹配
j = 1, i = 2 时,子串为 a a b,前缀为 a a,后缀为 a b,next[i] != next[j],那么让 j 循环回到可能能够匹配的位置,即 j = next[j - 1],此时 j = 0,前缀变为a,后缀变为b,仍然不匹配,next[i] = j (next[2] = 0),表示 a a b 的最长相等前后缀长度为0
j = 0, i = 3 时,子串为 a a b a,前缀为 a, 后缀为 a,next[i] == next[j],j++ (j = 1),next[i] = j (next[3] = 1),表示 a a b a 的最长相等前后缀长度为1
j = 1, i = 4 时,子串为 a a b a a,前缀为 a a ,后缀为 a a,next[i] == next[j],j++(j = 2),next[i] = j (next[4] = 2),表示 a a b a a 的最长相等前后缀长度为2
j = 2, i = 5 时,子串为 a a b a a f,前缀为 a a b,后缀为 a a f,next[i] != next[j],j = next[j - 1] (j = 1),前缀变为 a a,后缀变为 a f,仍然不匹配,j = next[j - 1] (j = 0),前缀变为 a,后缀变为 f,仍然不匹配,next[i] = j (next[5] = 0),表示a a b a a f 的最长相等前后缀长度为0
从这个模拟过程可以总结出,若前缀末尾字符与后缀末尾字符匹配,则将会进一步延申前缀长度和后缀长度;若不匹配,则不断压缩前缀长度和后缀长度
可结合该图进行理解,注意这幅图是next数组全部减1对应的图示,重点关注动画过程
void getNext(int* next, const string& s)
{
int j = 0;
next[0] = 0;
for (int i = 1; i < s.size(); i++)
{
// 前后缀不相同
while (j > 0 && s[i] != s[j]) // j要保证大于0,因为下面有取j-1作为数组下标的操作
{
j = next[j - 1]; // 注意这里,是要找前一位的对应的回退位置了
}
// 前后缀相同
if (s[i] == s[j])
{
j++;
}
next[i] = j;
}
}28.找出字符串中第一个匹配项的下标
28. 找出字符串中第一个匹配项的下标 - 力扣(LeetCode)
这道题就是KMP算法的应用,构建好next数组后,当模式串与文本串不匹配时,可将模式串回退到前面字符都匹配的位置,从而比重头再匹配更节省时间
时间复杂度:O(n + m)
空间复杂度:O(m)
class Solution {
public:
void getNext(int* next, const string& s)
{
int j = 0;
next[0] = 0;
for (int i = 1; i < s.size(); i++)
{
// 前后缀不相同
while (j > 0 && s[i] != s[j]) // j要保证大于0,因为下面有取j-1作为数组下标的操作
{
j = next[j - 1]; // 注意这里,是要找前一位的对应的回退位置了
}
// 前后缀相同
if (s[i] == s[j])
{
j++;
}
next[i] = j;
}
}
int strStr(string haystack, string needle) {
if (needle.size() == 0) return 0;
int next[needle.size()];
getNext(next, needle);
int j = 0;
for (int i = 0; i < haystack.size(); i++)
{
while (j > 0 && haystack[i] != needle[j])
{
j = next[j - 1]; // 回退
}
if (haystack[i] == needle[j])
{
j++;
}
if (j == needle.size())
{
return (i + 1 - needle.size());
}
}
return -1;
}
};文本串与模式串的匹配过程与构建next数组的过程很相似,都是不断扩大或缩小前后缀长度
459.重复的子字符串
暴力解法
将子串长度len从1开始遍历,并以len为步进验证对应字符是否相同
class Solution {
public:
bool repeatedSubstringPattern(string s) {
// 不断测试子串的长度
for (int len = 1; len <= s.size() / 2; len++) // 重复子串的长度最大也超不过字符串的一半
{
if (s.size() % len != 0) continue; // // 剪枝:原字符串长度必须能被子串长度整除,否则跳过
bool isMatch = true; // 标记当前子串是否满足条件
for (int i = len; i < s.size(); i++) // 遍历验证
{
if (s[i] != s[i - len]) // 若不满足重复子串
{
isMatch = false; // 标记不满足
break; // 直接进行下一轮循环
}
}
if (isMatch == true) return true; // 该轮循环直到最后标记都没有变成false,说明满足条件,直接返回
}
// 循环到最后都没返回,那么就不存在这样的重复子串
return false;
}
};虽然能通过,但是时间复杂度较高,为O(n^2)
KMP解法
如果这个字符串s是由重复子串组成,那么最长相等前后缀不包含的子串是字符串s的最小重复子串。
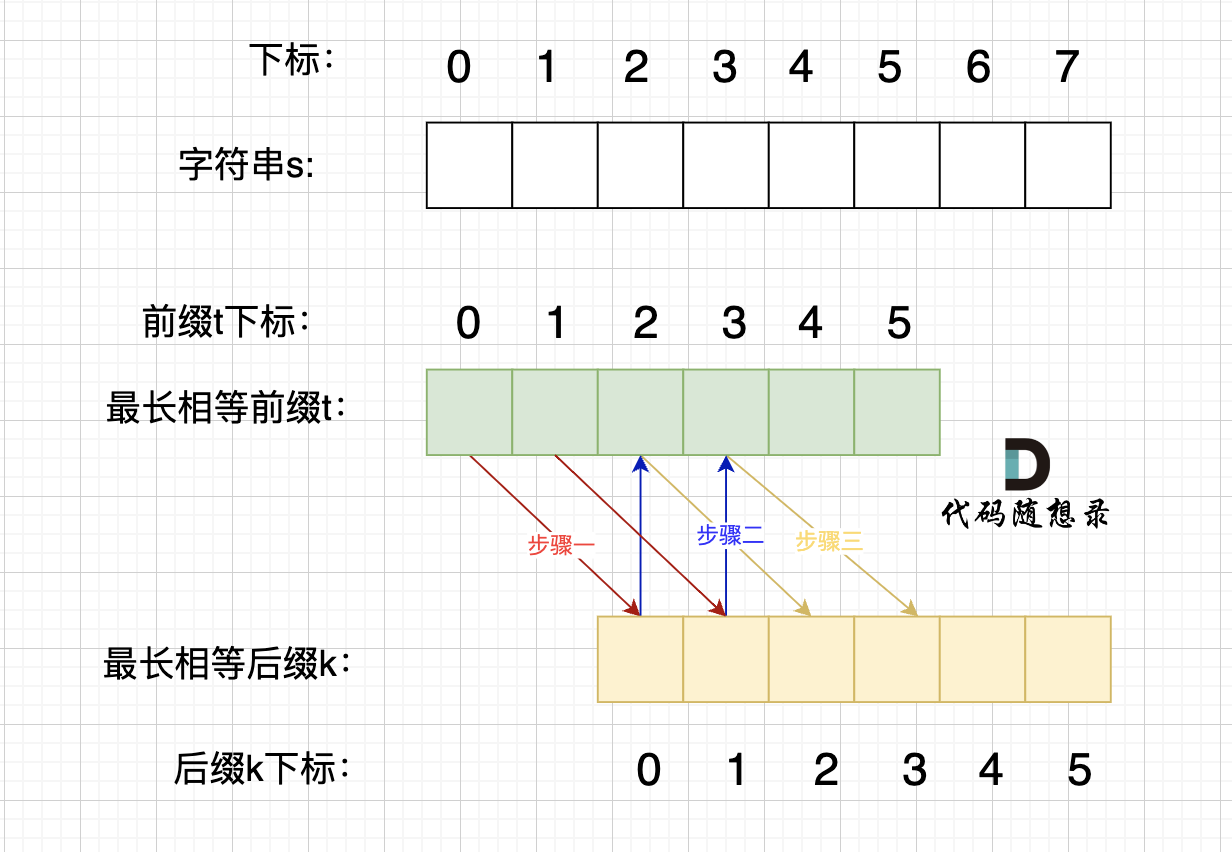

(这个图片的next数组是前缀表都减1后的,对应这里的代码应该加上1)
具体讲解过程查看代码随想录对应章节吧,我反正没咋搞懂
class Solution {
public:
void getNext(int* next, const string& s)
{
int j = 0;
next[0] = 0;
for (int i = 1; i < s.size(); i++)
{
while (j > 0 && s[j] != s[i])
{
j = next[j - 1];
}
if (s[j] == s[i])
{
j++;
}
next[i] = j;
}
}
bool repeatedSubstringPattern(string s) {
if (s.size() == 0) return false;
int next[s.size()];
getNext(next, s);
int len = s.size();
if (next[len - 1] != 0 && len % (len - next[len - 1]) == 0) return true;
return false;
}
};
开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)