如何快速读懂开源代码?
只有当你着手修改一个开源项目,你才能够快速懂得它。
先说结论:只有当你着手修改它,你才能够快速懂得它。
由于工作缘故,我必须参考大量开源项目,深入到源代码层面。
 https://github.com/platonai/PulsarRPA
https://github.com/platonai/PulsarRPA阅读 Apache Nutch 源代码
Apache Nutch is an extensible and scalable web crawler.
首先,我需要一个高性能分布式网络爬虫,在几年前,最知名的高性能分布式网络爬虫是 Apache Nutch。然而,Apache Nutch 有很多问题,首要的问题是,它不支持浏览器渲染。
于是我重新写了 Apache Nutch,让它支持浏览器渲染,同时提供了更好的 API,譬如:
fun load()
fun loadDeferred()
fun loadAsync()
fun submit()
fun loadAll()
fun submitAll()
fun loadOutPages()
fun submitForOutPages()
fun loadResource()
fun loadResourceDeferred()
fun loadDocument()
fun scrape()
fun scrapeOutPages()刚开始,我是用 Java 重写 Apache Nutch,在开发过程中,感到 Java 语法过于繁文缛节,于是我将所有 Java 代码转换成了 Kotlin,经过转换后,代码量大约只剩下三分之一。
开发效率大大提升,跟得上思维速度,语法比较符合思维习惯,我的感受是编写程序第一次有了行云流水的感觉,这非常重要。从头开发一个百万行代码的大型项目,编程时获得快感,意味着节约几年寿命。我至今满头黑发,皮肤透光就是明证。
最早的时候,比较知名的浏览器渲染引擎是 phantomjs,众所周知,后来 chrome 推出 CDP (Chrome DevTools Protocol) ,phantomjs 就被淘汰了。我也将 PulsarRPA 的渲染引擎切换到了 chrome。
阅读 Chromium 源代码
Chromium: chromium is an open-source browser project that aims to build a safer, faster, and more stable way for all users to experience the web. It is the foundation for Google Chrome. CEF: chromium Embedded Framework (CEF). A simple framework for embedding Chromium-based browsers in other applications.
最夸张的经历,是阅读 CEF (Chromium Embedded Framework) 和 Chromium 源代码。
开发 PulsarRPA,需要操作 Chromium 集群,自由网上冲浪。为了达到最佳效果,我调研了大量方案,其中一个方案就是基于 CEF 或者干脆基于 Chromium 直接开发。
CEF focuses on facilitating embedded browser use cases in third-party applications. CEF insulates the user from the underlying Chromium and Blink code complexity by offering production-quality stable APIs, release branches tracking specific Chromium releases, and binary distributions. Most features in CEF have default implementations that provide rich functionality while requiring little or no integration work from the user. CEF 专注于促进第三方应用程序中嵌入式浏览器的使用案例。CEF 通过提供生产级别的稳定API、跟踪特定 Chromium 版本的发布分支和二进制分发,使用户免受底层 Chromium 和 Blink 代码复杂性的影响。CEF 中的大多数功能都有默认实现,这些实现提供了丰富的功能,而用户需要进行的集成工作很少或没有。
CEF 是基于 Chromium 内核重新编译的,是 C++ 编写的,看上去能够解决很多问题,能够自由操纵浏览器网上冲浪。我基于 CEF 写了一些实验性代码,来体验 CEF 的可行性,写下来感觉,CEF 能够解决很多问题,但是和 CDP 打交道,开发工作量比较大,编译成本也比较高。
后来调研清楚了,PulsarRPA 的场景,基于 CDP (Chrome DevTools Protocol ) 开发就可以了。为什么不基于 selenium, playwright 和 puppeteer 开发呢?这个后面介绍。
阅读 Smile 源代码
Smile:Statistical Machine Intelligence & Learning Engine
由于我需要实现使用机器学习算法自动提取网页数据,将网页完整精确还原成结构化数据,因此我需要一个机器学习库。
Java 系的机器学习库有 Spark, Apache Math, Smile, Apache Mahout, Deeplearning4j, H2O, JavaML 等等。
由于我需要自行编写一些机器学习算法,并且需要足够快地掌握库,同时为项目提供最少外部依赖,因此我选择了最轻量级的 Apache Math 和 Smile,并阅读参考 Smile 的一些算法实现,自行编写机器学习算法。
为了实现大规模机器学习,也重新开了一个项目,使用 Spark 来训练机器学习模型。
阅读 Jsoup 源代码
jsoup: the Java HTML parser, built for HTML editing, cleaning, scraping, and XSS safety.
尽管 PulsarRPA 的数据提取的主要方法是机器学习和人工智能,但使用人工规则做数据提取仍然有需要。
PulsarRPA 使用 jsoup 从 HTML 文档中提取数据。 Jsoup 将 HTML 解析为与现代浏览器相同的 DOM。查看 selector-syntax 以查阅所有受支持的 CSS 选择器,这里 也有一份中文版标准 CSS 选择器的详细表格。 现代网页源代码变化非常频繁,但是一个网站的网页“看上去”不会变太多,从而保证一致的用户体验。这时候,从视觉特征去审视网页元素就特别有效。为了更好地从视觉特征和数字特征来看待网页,PulsarRPA 扩展了 CSS,从而可以从视觉特征和数字特征角度解决最复杂的现实问题。
为了更好地提取网页数据,我深入阅读了 Jsoup 源代码,做了一些升级,其中一个升级就是扩展 CSS 语法,用来支持数学计算。
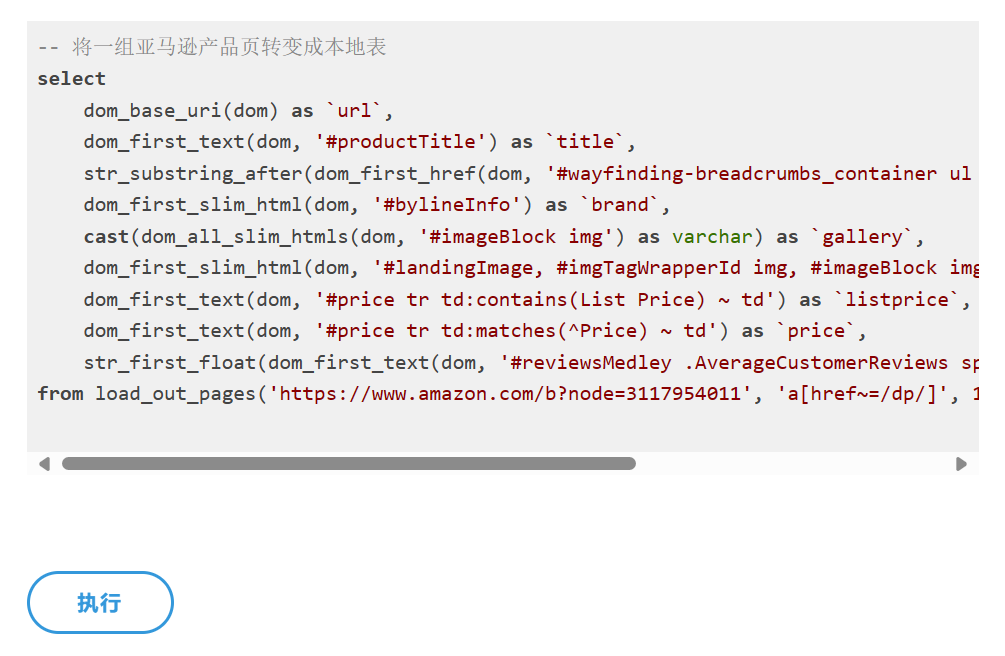
为了弥补现有 CSS 表达式的不足,PulsarRPA 引入了 :expr(expression) 伪选择器,使得我们可以在 CSS 中做数学运算。
/* 选择左侧栏宽 500 的链接 */
a:expr(left < 100 && width == 500)
/* 选择面积超过 1600 的图片 */
img:expr(width * height > 1600)
/* 选择文档中所有 div 元素,这些元素需要包含一张图片,宽和高都在 400 ~ 500 之间 */
div:expr(img == 1 && width > 400 && width < 500 && height > 400 && height < 500) https://blog.csdn.net/weixin_48738961/article/details/127534242
https://blog.csdn.net/weixin_48738961/article/details/127534242阅读 h2database 源代码
H2 is an embeddable RDBMS written in Java.
扩展 CSS 仍然不足以管理复杂的数据提取难题。尤其是:
-
Web 数据提取规则非常复杂,例如,每个单独的页面有 100 多个规则
-
需要维护的数据提取规则很多,比如全球 20 多个亚马逊网站,每个网站 20 多个数据类型
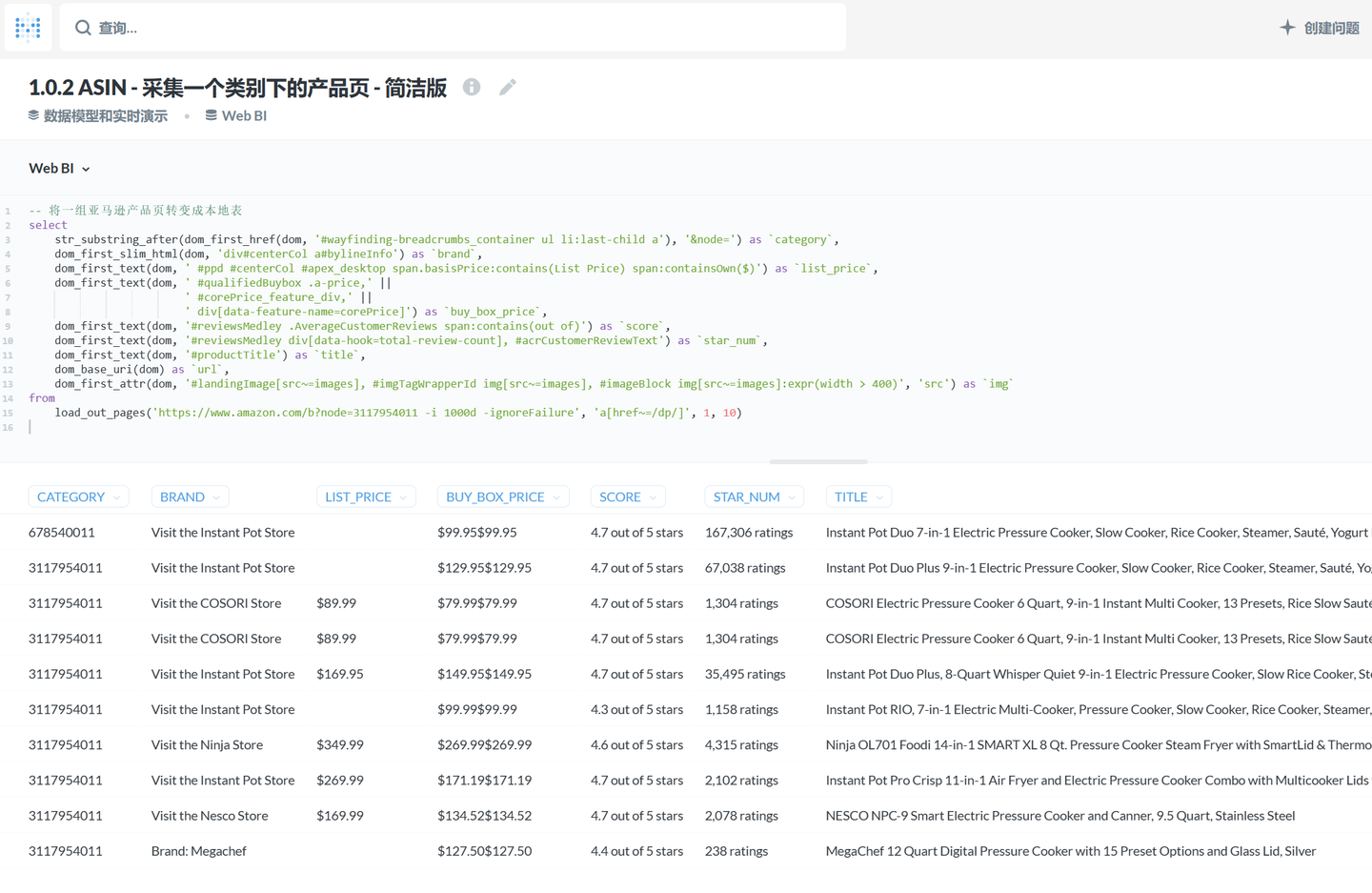
这时候,我让 PulsarRPA 支持了 SQL,使用 SQL 直接查询在线网页,提取网页内容,将网页内容转变成表格数据。
PulsarRPA 开发了 X-SQL 来直接查询互联网,并将网页转换成表格和图表。X-SQL 扩展了 SQL 来管理 Web 数据:网络爬取、数据采集、数据提取、Web 内容挖掘、Web BI,等等。 当 PulsarRPA 作为 REST 服务运行时,X-SQL 可用于随时随地采集网页或直接查询互联网,无需打开 IDE,就象是升级版的 Google 和百度。 现在,我们在大型数据采集项目中,所有 提取规则(国内镜像)都是用 X-SQL 编写的,数据类型转换、数据清理等工作也由强大的 X-SQL 内联处理。编写 X-SQL 做数据采集项目的体验,就像传统的 CRUD 项目一样简单高效。一个很好的例子是 x-asin.sql(国内镜像),它从每个产品页面中提取 70 多个字段。
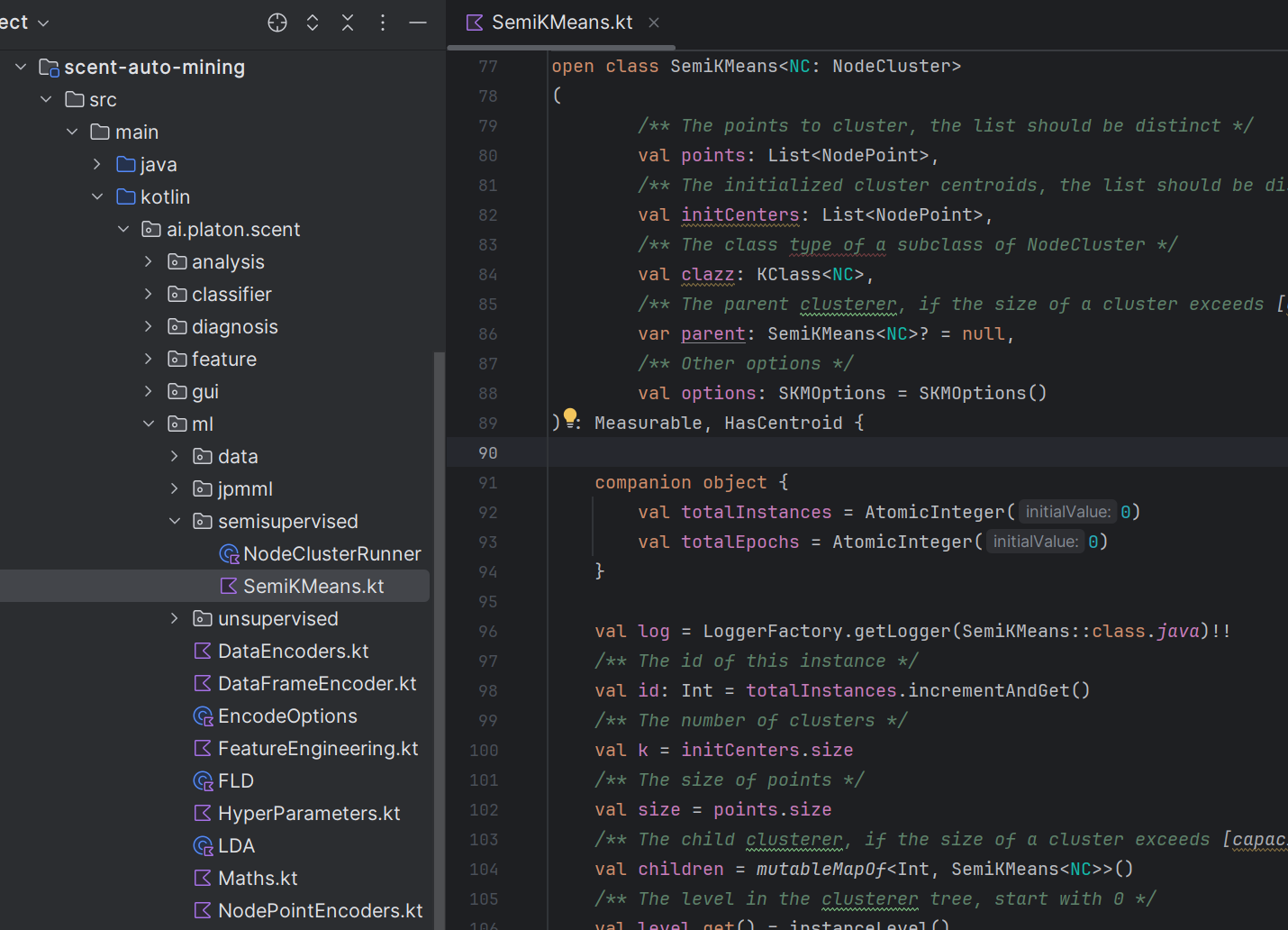
为了让 PulsarRPA 支持了 SQL,我深入阅读了 h2database 源代码,做了一些升级,来支持使用SQL 直接查询在线网页,提取网页内容:
阅读 Metabase 源代码
Metabase: The simplest, fastest way to get business intelligence and analytics to everyone in your company.
由于 PulsarRPA 支持了 SQL,我需要一个好用的 SQL 编辑器来访问 PulsarRPA。在做了一番调研后,我选择了 Metabase。
Metabase 是由 ReactJS 和 Clojure 编写的,漂亮到惊艳。我看到 Metabase 的第一眼,就被它漂亮的界面、简洁的设计迷住了。
我决定让 Metabase 成为 PulsarRPA 的 SQL 编辑器。然而事情并不那么容易。
Metabase 前端是由 ReactJS 编写,后端是由 Clojure 编写的,这是两个我从来没有见过的语言,Clojure 甚至是我从来没有见过的语系,所有语法完全颠覆了我的认知。
不得不说,Clojure 语法非常简洁漂亮,然而要在一周左右的短时间内掌握它,并且编写代码实现目标,大脑比较抗拒。最终,在大约两个周左右时间里,我成功改写了 Metabase,能够用它编写 SQL 访问 PulsarRPA。
阅读 selenium, playwright 和 puppeteer 源代码
由于 PulsarRPA 是操纵大规模浏览器集群,因此,不得不和 selenium, playwright, puppeteer 几个知名框架做深层次对比。
类似 selenium, playwright, puppeteer 这样的浏览器驱动,在 PulsarRPA 中仅仅只是一个不大的子系统,可见单单 selenium, playwright, puppeteer 能够解决的问题极其有限。为了性能、稳定性、容错性、简洁性等考虑,我没有用这些框架作为浏览器驱动,而是基于 CDP 直接开发。
PulsarRPA 的 RPA 子系统,来实现网页交互:滚动、打字、屏幕捕获、鼠标拖放、点击等。该子系统和大家所熟知的 selenium, playwright, puppeteer 是类似的,但对所有行为进行了优化,譬如更真实的模拟操作,更好的执行性能,更好的并行性,更好的容错处理,等等。
阅读其他项目源代码
作为一名工程师,要实现目标,往往不需要太多外部资源,搜索+阅读,就能够提供我们需要的绝大多数资源。
在我的编程生涯中,阅读过的源代码远远不止这些项目。
在前智能时代,很多代码细节都能够由 LLM 自动生成,这时候,领域深度和视野广度可能会变得越来越重要。
我相信,编程=文学+数学+程序。文学代表了产品的社会价值和总体架构,数学往往代表了产品能够解决的问题的规模,而程序则意味着一步一个脚印实现目标。
在前智能时代,工程师不应该向销售看齐,而是应当向作家看齐。程序员和畅销书作家类似,不同的是,程序员直接影响物理世界,改造物理世界,创造产品,获得产品带来的收益。

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐


 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)