(2.4.2.1)协程->任务
协程是可挂起计算的一个任务实例,用一个代码块表示从概念上讲,它类似于线程。从某种意义上说,它需要一个代码块来运行,该代码块与代码的其余部分同时工作。但是,协程不绑定到任何特定线程。它可能会在一个线程中暂停执行,并在另一个线程中恢复执行。协程如果不配置线程,默认在当前线程跑,只不过实现了并发控制规避回调地域。协程的挂起函数(如delay)在底层确实依赖 回调机制,但通过编译器和运行时将其隐藏,开发者
把协程和一个任务挂靠上更方便理解
参考文献
https://juejin.cn/post/6953441828100112392
Kotlin 协程 - 协程作用域 CoroutineScope-CSDN博客
Kotlin Playground: Edit, Run, Share Kotlin Code Online
Hello 协程!
import kotlinx.coroutines.*
fun main() {
GlobalScope.launch(Dispatchers.Main) {
val result = withContext(Dispatchers.IO) {
//网络请求...
"请求结果"
}
btn.text = result
Log.i(TAG, "这个最后输出")
}
Log.i(TAG, "这个首先输出")
}
主线程时间线:
├── 新建并提交协程到主线程队列(未立即执行)
├── 执行 Log.i("这个首先输出") // 立即执行
└── 主线程空闲后执行协程:
├── 切换到 IO 线程执行网络请求 // 后台执行
├── 切回主线程更新 UI(btn.text = result)
└── 执行 Log.i("这个最后输出") // 最后输出解释下这段代码不阻塞Main的原理
- 先新建一个主线程上的协程任务(立即调度,但是要等待主线程空闲时才执行)
-
- launch协程会被立即调度到目标线程(此处是
Dispatchers.Main,即 Android 的主线程) Dispatchers.Main表示协程的默认执行线程是主线程(UI 线程),但此时协程仅仅是启动了一个空的代码块,并没有实际执行耗时操作。
- launch协程会被立即调度到目标线程(此处是
-
-
- 在 Android 中,主线程通过 事件循环(Event Loop) 处理任务队列。协程的代码块会被封装成一个任务(
Runnable),通过Handler.post()提交到主线程队列。 - 非抢占式执行:协程的代码块会被放入主线程的任务队列中,等待主线程空闲时才会执行。
- 在 Android 中,主线程通过 事件循环(Event Loop) 处理任务队列。协程的代码块会被封装成一个任务(
-
GlobalScope.launch(Dispatchers.Main) {
// 协程在 Dispatchers.Main(主线程)中启动
}withContext(Dispatchers.IO)的挂起与线程切换。withContext是一个 挂起函数,它会在不阻塞当前线程(主线程)的情况下,切换到Dispatchers.IO线程池立即执行耗时操作。
-
- 主线程的协程会被挂起(非阻塞!),主线程立即释放,继续处理其他任务(如 UI 渲染、点击事件)。
- 耗时操作(网络请求)在
Dispatchers.IO的线程池中执行。withContext切换线程后,目标代码块会立即执行。 - 当
withContext内的代码执行完毕后,协程会自动切换回原来的调度器(Dispatchers.Main)。
val result = withContext(Dispatchers.IO) {
// 网络请求(耗时操作)
"请求结果"
}- UI 更新的安全执行
-
- 由于
withContext结束后自动切换回Dispatchers.Main,此时btn.text = result会在主线程执行,符合 Android 的 UI 更新规则。
- 由于
btn.text = result // 回到主线程更新 UI原理图示
主线程(Main Thread)
│
├── 新建协程(无阻塞)
│ │
│ ├── 挂起点(withContext 切换线程)
│ │ └── 耗时操作在 IO 线程执行 ──┐
│ │ │
│ └── 恢复点(操作完成,回到主线程) <──┘
│ └── 更新 UI(安全操作)
│
└── 主线程继续处理其他任务(如 UI 事件)对比传统线程方案
Thread+Handler:需要手动切换线程,代码冗余且易出错。- 协程:通过结构化并发和挂起机制,以同步代码风格实现异步操作,且天然避免回调地狱。
其实有点像自己之前手撸的RXjava实现链式调度和线程调度,本质上是在线程的基础上实现一套基于观察者模式和代理机制的任务调度体系,从而规避调各种回调(从某种意义上启动协程就开始进入回调机制,只不过有的回调是立即执行)。
一、协程概述
协程是可挂起计算的一个任务实例,用一个代码块表示
- 从概念上讲,它类似于线程。
- 从某种意义上说,它需要一个代码块来运行,该代码块与代码的其余部分同时工作。
- 但是,协程不绑定到任何特定线程。它可能会在一个线程中暂停执行,并在另一个线程中恢复执行。
-
- 协程如果不配置线程,默认在当前线程跑,只不过实现了并发控制规避回调地域。
- 协程的挂起函数(如
withContext、delay)在底层确实依赖 回调机制,但通过编译器和运行时将其隐藏,开发者无需手动处理回调。具体实现方式
kotlin协程本质上是在线程池基础上对回调机制的一套封装。协程通过将复杂性放入库来简化异步编程。程序的逻辑可以在协程中顺序地表达,而底层库会为我们解决其异步性。该库可以将用户代码的相关部分包装为回调、订阅相关事件、在不同线程(甚至不同机器!)上调度执行,而代码则保持如同顺序执行一样简单。
1.1 与线程的差异
协程可以被认为是轻量级线程,但有许多重要的差异使它们在现实生活中的使用与线程非常不同。与 JVM 线程相比,协程占用的资源更少。例如,以下代码启动 50,000 个不同的协程,每个协程等待 5 秒,然后打印一个句点 ('.'),同时消耗很少的内存:
import kotlinx.coroutines.*
fun main() = runBlocking {
repeat(50_000) { // 启动大量的协程
launch {
delay(5000L)
print(".")
}
}
}如果使用线程编写相同的程序(删除 runBlocking,用线程替换 launch,用 Thread.sleep 替换 delay),它将消耗大量内存。根据您的操作系统、JDK 版本及其设置,它将抛出内存不足错误或缓慢启动线程,以便永远不会有太多并发运行的线程。
1.2 协程的挂起->启动一个独立任务
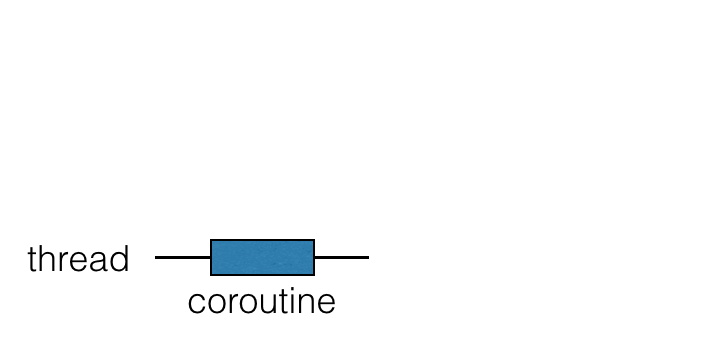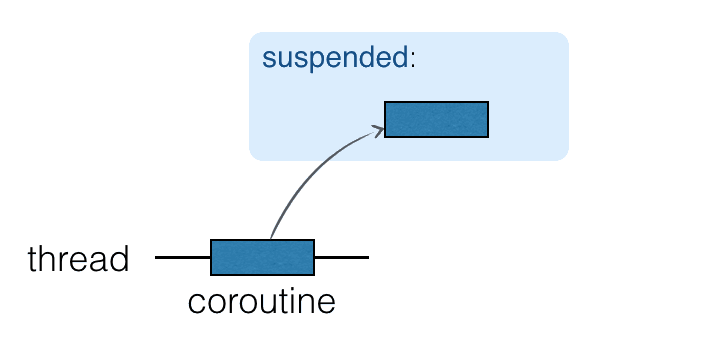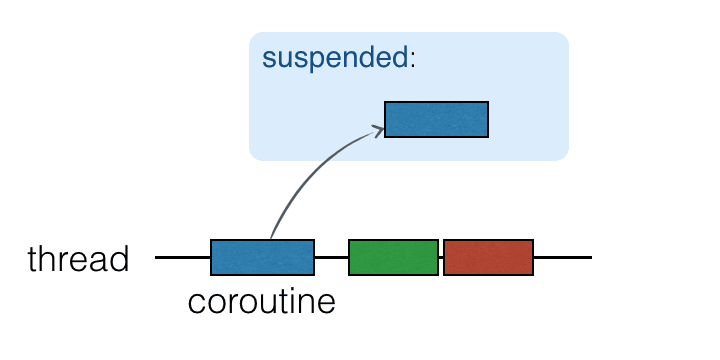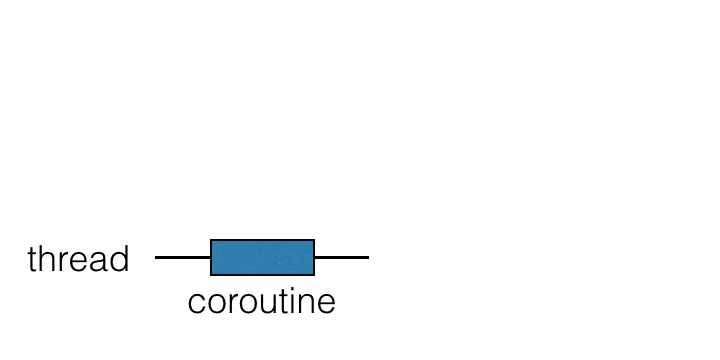
- 协程任务在线程上运行,可以挂起和恢复(注意不是线程的挂起,而是协程的挂起)。
- [并发1] 当协程任务挂起时相应的计算将暂停,从线程中删除,并存储在内存中。当前线程可以自由地被其他任务占用
-
- 当响应等待接收时,线程可以自由地被其他任务占用,UI 仍保持响应
- [并发2] 相当于后续代码变成了一个任务并发开始
-
- 当计算准备好=挂起结束时,协程继续,它将返回到一个线程(不一定是同一个线程)。

1.3 协程的生命周期
[新建 New] → [活跃 Active] → ([完成 Completed] 或 [取消 Cancelled])
↗ ↖
[挂起 Suspended]
新建(New)
- 状态特征:协程已创建但未启动。
- 触发条件:使用
launch(start = CoroutineStart.LAZY)或async(start = CoroutineStart.LAZY)延迟启动时。 - 示例代码:
kotlin
val job = CoroutineScope(Dispatchers.IO).launch(start = CoroutineStart.LAZY) {
// 协程体(未执行)
}活跃(Active)
- 状态特征:协程正在执行或可被恢复。
- 包含子状态:
-
- 运行中(Running):代码块正在执行。
- 挂起(Suspended):遇到
delay()或withContext()等挂起点,等待恢复。
- 状态转换:
kotlin
job.start() // 从 New → Active
job.resume() // 从 Suspended → Active完成(Completed)
- 状态特征:协程正常执行完毕。
- 触发条件:协程体代码执行完成。
- 结果处理:
kotlin
val deferred = async { "Result" }
deferred.await() // 获取结果取消(Cancelled)
- 状态特征:协程被显式取消或因异常终止。
- 触发条件:
kotlin
job.cancel() // 手动取消
// 或协程内部抛出未捕获异常- 取消传播:父协程取消时,所有子协程递归取消。
1.4 协程运行的核心源码CoroutineScheduler
internal class CoroutineScheduler(...) : Executor, Closeable {
@JvmField
val globalBlockingQueue = GlobalQueue()
fun runSafely(task: Task) {
try {
task.run()
} catch (e: Throwable) {
val thread = Thread.currentThread()
thread.uncaughtExceptionHandler.uncaughtException(thread, e)
} finally {
unTrackTask()
}
}
//省略...
internal inner class Worker private constructor() : Thread() {
override fun run() = runWorker()
private fun runWorker() {
var rescanned = false
while (!isTerminated && state != WorkerState.TERMINATED) {
val task = findTask(mayHaveLocalTasks)
if (task != null) {
rescanned = false
minDelayUntilStealableTaskNs = 0L
executeTask(task)
continue
} else {
mayHaveLocalTasks = false
}
//省略...
continue
}
}
private fun executeTask(task: Task) {
//省略...
runSafely(task)
//省略...
}
fun findTask(scanLocalQueue: Boolean): Task? {
if (tryAcquireCpuPermit()) return findAnyTask(scanLocalQueue)
val task = if (scanLocalQueue) {
localQueue.poll() ?: globalBlockingQueue.removeFirstOrNull()
} else {
globalBlockingQueue.removeFirstOrNull()
}
return task ?: trySteal(blockingOnly = true)
}
//省略...
}
//省略...
}
跟ThreadPoolExecutor线程池和Thread线程的运行很像,一样的生产者消费者对列,我们通过线程池(CoroutineScheduler)创建了一个Thread线程(Worker),然后开始执行线程(runWorker),线程里面通过executeTask执行一个任务DispatchedTask,在执行任务的时候我们通过try..catch来保证任务安全执行runSafely
二、协程3要素
在主线程为单一线程的模型中下述例子 输出 Hello kotlin World! &&,如果去掉delay(1000L)其实还是一样的输出
- &&在最后
-
- runBlocking 是一个协程构建器。运行它的线程(在本例中为 — 主线程)在调用期间被阻塞,直到
runBlocking { ... }中的所有协程完成执行。
- runBlocking 是一个协程构建器。运行它的线程(在本例中为 — 主线程)在调用期间被阻塞,直到
- Hello在前 Kotlin在后
-
- Launch 是一个协程构建器。它与代码的其余部分同时启动一个新的协程,该协程继续独立工作。launch接受一个函数类型的参数,其实就是我们后续的协程任务
launch启动的协程会被立即调度,但不会立即执行(需要等待当前协程代码块让出线程)。这就是Hello首先被打印出来的原因。- 协程开始执行时,就会输出Kotlin
- delay 是一种特殊的挂起功能。它会在特定时间内暂停协程。挂起协程不会阻塞底层线程,但允许其他协程运行并使用底层线程处理其代码。
import kotlinx.coroutines.*
//sampleStart
fun main() {
runBlocking { // this: CoroutineScope 开始阻塞主线程
launch { // 步骤 1:启动新协程将协程任务加入队列(不立即执行),还是在main线程
println("Kotlin") // 任务运行时立即输出
delay(1000L) // non-blocking delay for 1 second (default time unit is ms)
println("World!") // print after delay
}
println("Hello") // // 步骤 2:主协程立即执行这条代码
}
println("&&")
}
//sampleEndCoroutineScope 协程作用域。 协程遵循结构化并发原则,这意味着新的协程只能在特定的 CoroutineScope 中启动,这限制了协程的生存期。上面的示例表明 runBlocking 建立了相应的范围
2.1 挂起函数suspend释放当前线程资源
delay()是一个带有 suspend 修饰符的新函数。挂起函数可以像常规函数一样在协程内部使用,他们的主要功能就是 挂起当前协程,释放当前线程允许其他使用
import kotlinx.coroutines.*
//sampleStart
fun main() = runBlocking { // this: CoroutineScope
launch { doWorld() }
println("Hello")
}
// this is your first suspending function
suspend fun doWorld() {
delay(1000L)
println("World!")
}
//sampleEnd2.2 协程作用域CoroutineScope
2.3 协程构建器launch
launche生成器启动协程后返回一个 Job 对象,该对象是已启动协程的句柄,可用于显式等待其完成。例如,您可以等待子协程完成,然后打印“Done”字符串:
import kotlinx.coroutines.*
fun main() = runBlocking {
//sampleStart
val job = launch { // launch a new coroutine and keep a reference to its Job
delay(1000L)
println("World!")
}
println("Hello")
job.join() // wait until child coroutine completes
println("Done")
//sampleEnd
}This code produces: 此代码生成:
Hello
World!
Done
三、新建协程
3.1 构建器runBlocking、launch、async
要启动新的协程,请使用主要的协程构建器之一:launch、async 或 runBlocking。不同的库可以定义其他协程构建器
|
顶层 |
普通函数 |
runBlocking:T |
|
|
静态函数 |
核心库 |
利用GlobalScope作用域调用lanch和async |
可以使用
|
|
工厂函数 |
利用MainScope( ) CoroutineScope()作用域调用lanch和async |
|
|
|
作用域函数 |
扩展函数 |
launch:Job |
|
|
扩展函数 |
|
|
|
|
只创建协程作用域 |
作用域成员函数 |
supervisorScope() withContext() |
不会主动启动新的协程,它仅用于创建一个新的 协程作用域(Coroutine Scope),并挂起当前协程,立即执行直到其代码块内的所有子协程执行完毕,全是suspend
|



import kotlinx.coroutines.*
fun main() = runBlocking {
val deferred: Deferred<Int> = async {
loadData()
}
println("waiting...")
println(deferred.await())
}
suspend fun loadData(): Int {
println("loading...")
delay(1000L)
println("loaded!")
return 42
}
waiting
loading
loaded
423.2【2rd 协程启动模式】CoroutineStart
CoroutineStart协程启动模式,是启动协程时需要传入的第二个参数。协程启动有4种:
DEFAULT默认启动模式,我们可以称之为饿汉启动模式,因为协程创建后立即开始调度,虽然是立即调度,单不是立即执行,有可能在执行前被取消。LAZY懒汉启动模式,启动后并不会有任何调度行为,直到我们需要它执行的时候才会产生调度。也就是说只有我们主动的调用Job的start、join或者await等函数时才会开始调度。ATOMIC一样也是在协程创建后立即开始调度,但是它和DEFAULT模式有一点不一样,通过ATOMIC模式启动的协程执行到第一个挂起点之前是不响应cancel取消操作的,ATOMIC一定要涉及到协程挂起后cancel取消操作的时候才有意义。UNDISPATCHED协程在这种模式下会直接开始在当前线程下执行,直到运行到第一个挂起点。这听起来有点像ATOMIC,不同之处在于UNDISPATCHED是不经过任何调度器就开始执行的。当然遇到挂起点之后的执行,将取决于挂起点本身的逻辑和协程上下文中的调度器。
3.2.1理解启动模式的示例
private fun testCoroutineStart(){
# 我们上面提到过DEFAULT模式协程创建后立即开始调度
# 但不是立即执行,所以它有可能会被cancel取消,导致没有输出defaultJob这条日志
# 也有可能不取消,所以可以打印出来
val defaultJob = GlobalScope.launch{
Log.d("defaultJob", "CoroutineStart.DEFAULT")
}
defaultJob.cancel()
#不会被打印,因为没有join或者await
val lazyJob = GlobalScope.launch(start = CoroutineStart.LAZY){
Log.d("lazyJob", "CoroutineStart.LAZY")
}
# 创建后立即开始调度,但是只有到第一个挂起点才响应cancel
# 所以一定会输出挂起前,一定不输出挂起后
val atomicJob = GlobalScope.launch(start = CoroutineStart.ATOMIC){
Log.d("atomicJob", "CoroutineStart.ATOMIC挂起前")
delay(100)
Log.d("atomicJob", "CoroutineStart.ATOMIC挂起后")
}
atomicJob.cancel()
# 创建后立即开始执行,但是只有到第一个挂起点才响应cancel
# 所以一定会输出挂起前,一定不输出挂起后
# 同时 因为UNDISPATCHED是立即执行的,所以他的日志UNDISPATCHED挂起前输出在ATOMIC挂起前的前面
# 但是注意,考虑到多线程机制,它在前边也是个概率事件
val undispatchedJob = GlobalScope.launch(start = CoroutineStart.UNDISPATCHED){
Log.d("undispatchedJob", "CoroutineStart.UNDISPATCHED挂起前")
delay(100)
Log.d("undispatchedJob", "CoroutineStart.UNDISPATCHED挂起后")
}
undispatchedJob.cancel()
}
D/defaultJob: CoroutineStart.DEFAULT
D/atomicJob: CoroutineStart.ATOMIC挂起前
D/undispatchedJob: CoroutineStart.UNDISPATCHED挂起前
或者
D/undispatchedJob: CoroutineStart.UNDISPATCHED挂起前
D/atomicJob: CoroutineStart.ATOMIC挂起前
3.2.2 惰性启动的 async
可选的,async 可以通过将 start 参数设置为 CoroutineStart.LAZY 而变为惰性的。 在这个模式下,只有结果通过 await 获取的时候协程才会启动或者在 Job 的 start 函数调用的时候。运行下面的示例:
import kotlinx.coroutines.*
import kotlin.system.*
fun main() = runBlocking<Unit> {
//sampleStart
val time = measureTimeMillis {
val one = async(start = CoroutineStart.LAZY) { doSomethingUsefulOne() }
val two = async(start = CoroutineStart.LAZY) { doSomethingUsefulTwo() }
// 执行一些计算
one.start() // 启动第一个
two.start() // 启动第二个
println("The answer is ${one.await() + two.await()}")
}
println("Completed in $time ms")
//sampleEnd
}
suspend fun doSomethingUsefulOne(): Int {
delay(1000L) // 假设我们在这里做了些有用的事
return 13
}
suspend fun doSomethingUsefulTwo(): Int {
delay(1000L) // 假设我们在这里也做了些有用的事
return 29
}它的打印输出如下:
The answer is 42
Completed in 1017 ms因此,在先前的例子中这里定义的两个协程没有执行,但是控制权在于程序员准确的在开始执行时调用 start。我们首先 调用 one,然后调用 two,接下来等待这个协程执行完毕。
注意,如果我们只是在 println 中调用 await,而没有在单独的协程中调用 start,这将会导致顺序行为,直到 await 启动该协程 执行并等待至它结束,这并不是惰性的预期用例
3.2.3 摇摆启动的UNDISPATCHED
当以UNDISPATCHED启动时:
- 无论我们是否指定协程调度器,
挂起前的执行都是在当前线程下执行。 - 如果所在的协程没有指定调度器,那么就会在
join处恢复执行的线程里执行,即我们上述案例中的挂起后的执行是在main线程中执行。 - 当我们指定了协程调度器时,遇到挂起点之后的执行将取决于挂起点本身的逻辑和协程上下文中的调度器。即
join处恢复执行时,因为所在的协程有调度器,所以后面的执行将会在调度器对应的线程上执行。
private fun testUnDispatched(){
GlobalScope.launch(Dispatchers.Main){
val job = launch(Dispatchers.IO) {
Log.d("${Thread.currentThread().name}线程", "-> 挂起前")
delay(100)
Log.d("${Thread.currentThread().name}线程", "-> 挂起后")
}
Log.d("${Thread.currentThread().name}线程", "-> join前")
job.join()
Log.d("${Thread.currentThread().name}线程", "-> join后")
}
}
D/main线程: -> join前
D/DefaultDispatcher-worker-1线程: -> 挂起前
D/DefaultDispatcher-worker-1线程: -> 挂起后
D/main线程: -> join后
#当以UNDISPATCHED模式即使我们指定了协程调度器Dispatchers.IO
# 挂起前还是在main线程里执行,但是挂起后是在worker-1线程里面执行
# 这是因为当以UNDISPATCHED启动时,协程在这种模式下会直接开始在当前线程下执行,直到第一个挂起点。
# 遇到挂起点之后的执行,将取决于挂起点本身的逻辑和协程上下文中的调度器,即join处恢复执行时,
# 因为所在的协程有调度器,所以后面的执行将会在调度器对应的线程上执行。
private fun testUnDispatched(){
GlobalScope.launch(Dispatchers.Main){
val job = launch(Dispatchers.IO,start = CoroutineStart.UNDISPATCHED) {
Log.d("${Thread.currentThread().name}线程", "-> 挂起前")
delay(100)
Log.d("${Thread.currentThread().name}线程", "-> 挂起后")
}
Log.d("${Thread.currentThread().name}线程", "-> join前")
job.join()
Log.d("${Thread.currentThread().name}线程", "-> join后")
}
}
D/main线程: -> 挂起前
D/main线程: -> join前
D/DefaultDispatcher-worker-1线程: -> 挂起后
D/main线程: -> join后
#它们都在一个线程里面执行了。这是因为当通过UNDISPATCHED启动后遇到挂起
# join处恢复执行时如果所在的协程没有指定调度器,那么就会在join处恢复执行的线程里执行
# 即挂起后是在父协程(Dispatchers.Main线程里面执行
# 而最后join后这条日志的输出调度取决于这个最外层的协程的调度规则
private fun testUnDispatched(){
GlobalScope.launch(Dispatchers.Main){
val job = launch(start = CoroutineStart.UNDISPATCHED) {
Log.d("${Thread.currentThread().name}线程", "-> 挂起前")
delay(100)
Log.d("${Thread.currentThread().name}线程", "-> 挂起后")
}
Log.d("${Thread.currentThread().name}线程", "-> join前")
job.join()
Log.d("${Thread.currentThread().name}线程", "-> join后")
}
}
D/main线程: -> 挂起前
D/main线程: -> join前
D/main线程: -> 挂起后
D/main线程: -> join后
3.2.4 协程返回值:作业Job 、Deferred
Job我们可以认为他就是一个协程作业是通过CoroutineScope.launch生成的,同时它运行一个指定的代码块,并在该代码块完成时完成。我们可以通过isActive、isCompleted、isCancelled来获取到Job的当前状态。Job的状态如下图所示,摘自官方文档:
|
State |
[isActive] |
[isCompleted] |
[isCancelled] |
|
New (optional initial state) |
|
|
|
|
Active (default initial state) |
|
|
|
|
Completing (transient state) |
|
|
|
|
Cancelling (transient state) |
|
|
|
|
Cancelled (final state) |
|
|
|
|
Completed (final state) |
|
|
|
我们可以通过下图可以大概了解下一个协程作业从创建到完成或者取消,Job在这里不扩展了,后面我们会在实际使用过程中去讲解。
wait children
+-----+ start +--------+ complete +-------------+ finish +-----------+
| New | -----> | Active | ---------> | Completing | -------> | Completed |
+-----+ +--------+ +-------------+ +-----------+
| cancel / fail |
| +----------------+
| |
V V
+------------+ finish +-----------+
| Cancelling | --------------------------------> | Cancelled |
+------------+ +-----------+Deferred继承自Job,我们可以把它看做一个带有返回值的Job,
复制代码public interface Deferred<out T> : Job {
//返回结果值,或者如果延迟被取消,则抛出相应的异常
public suspend fun await(): T
public val onAwait: SelectClause1<T>
public fun getCompleted(): T
public fun getCompletionExceptionOrNull(): Throwable?
}我们需要重点关注await()方法,可以看到await()方法返回结果是T,说明我们可以通过await()方法获取执行流的返回值,当然如果出现异常或者被取消执行,则会抛出相对应的异常。
四、协程作用域 CoroutineScope
协程作用域负责不同协程之间的结构和父子关系。新的协程通常需要在作用域内启动。
- 作用域通常负责子协程,子协程的生存期与作用域的生存期相关联。如果在协程内部发生了错误,并且它抛出了一个异常, 所有在作用域中启动的协程都会被取消
- 作用域会自动等待所有子协程的完成。因此,如果作用域对应于协程,则在其作用域中启动的所有协程都完成后,父协程不会完成。
launch、async都是CoroutineScope的扩展函数,CoroutineScope定义了新启动的协程作用范围,同时会继承了他的coroutineContext自动传播其所有的 elements和取消操作。换句话说,如果这个作用域销毁了,那么里面的协程也随之失效,就好比变量的作用域
当使用 launch、async 或 runBlocking 启动新的协程时,它们会自动创建相应的范围。所有这些函数都采用带有接收器的 lambda 作为参数,而 CoroutineScope 是隐式接收器类型:
launch { /* this: CoroutineScope */ }4.1 作用域的分类
我们之前提到过父协程和子协程的概念,既然有父协程和子协程,那么必然也有父协程作用域和子父协程作用域。不过我们不是这么称呼,因为他们不仅仅是父与子的概念。协程作用域分为三种:
顶级作用域--> 没有父协程的协程所在的作用域称之为顶级作用域。协同作用域--> 在协程中启动一个协程,新协程为所在协程的子协程。子协程所在的作用域默认为协同作用域。此时子协程抛出未捕获的异常时,会将异常传递给父协程处理,如果父协程被取消,则所有子协程同时也会被取消。主从作用域官方称之为监督作用域。与协同作用域一致,区别在于该作用域下的协程取消操作的单向传播性,子协程的异常不会导致其它子协程取消。但是如果父协程被取消,则所有子协程同时也会被取消。
同时补充一点:父协程需要等待所有的子协程执行完毕之后才会进入Completed状态,不管父协程自身的协程体是否已经执行完成
4.1.1 协同作用域的继承关系
子协程会继承父协程的协程上下文中的Element,如果自身有相同key的成员,则覆盖对应的key,覆盖的效果仅限自身范围内有效
private fun testCoroutineScope(){
GlobalScope.launch(Dispatchers.Main){
Log.d("父协程上下文", "$coroutineContext")
launch(CoroutineName("第一个子协程")) {
Log.d("第一个子协程上下文", "$coroutineContext")
}
launch(Dispatchers.Unconfined) {
Log.d("第二个子协程协程上下文", "$coroutineContext")
}
}
}
D/父协程上下文: [StandaloneCoroutine{Active}@81b6e46, Dispatchers.Main]
D/第二个子协程协程上下文: [StandaloneCoroutine{Active}@f6b7807, Dispatchers.Unconfined]
D/第一个子协程上下文: [CoroutineName(第一个子协程), StandaloneCoroutine{Active}@bbe6d34, Dispatchers.Main]
- 第一个子协程的覆盖了父协程的
coroutineContext,它继承了父协程的调度器Dispatchers.Main,同时也新增了一个CoroutineName属性。 - 第二个子协程覆盖了父协程的
coroutineContext中的Dispatchers,也就是将父协程的调度器Dispatchers.Main覆盖为Dispatchers.Unconfined,但是他没有继承第一个子协程的CoroutineName,这就是我们说的覆盖的效果仅限自身范围内有效
4.1.2 协同作用域的异常处理
如果子协程抛出未捕获的异常时,会将异常传递给父协程处理,如果父协程被取消,则所有子协程同时也会被取消
private fun testCoroutineScope2() {
val exceptionHandler = CoroutineExceptionHandler { coroutineContext, throwable ->
Log.d("exceptionHandler", "${coroutineContext[CoroutineName]} $throwable")
}
GlobalScope.launch(Dispatchers.Main + CoroutineName("scope1") + exceptionHandler) {
Log.d("scope", "--------- 1")
launch(CoroutineName("scope2") + exceptionHandler) {
Log.d("scope", "--------- 2")
throw NullPointerException("空指针")
Log.d("scope", "--------- 3")
}
val scope3 = launch(CoroutineName("scope3") + exceptionHandler) {
Log.d("scope", "--------- 4")
delay(2000)
Log.d("scope", "--------- 5")
}
scope3.join()
Log.d("scope", "--------- 6")
}
}
# 子协程scope2抛出了一个异常,将异常传递给父协程scope1处理,
# 但是因为任何一个子协程异常退出会导致整体都将退出。
# 所以导致父协程scope1未执行完成成就被取消,同时还未执行完子协程scope3也被取消了。
D/scope: --------- 1
D/scope: --------- 2
D/exceptionHandler: CoroutineName(scope1) java.lang.NullPointerException: 空指针
4.1.3 主从(监督)作用域 supervisorScope
与协同作用域一致,区别在于该作用域下的协程取消操作的单向传播性,子协程的异常不会导致其它子协程取消。分析主从(监督)作用域的时候,我们需要用到supervisorScope或者SupervisorJob
supervisorScope {}
private fun testCoroutineScope3() {
val exceptionHandler = CoroutineExceptionHandler { coroutineContext, throwable ->
Log.d("exceptionHandler", "${coroutineContext[CoroutineName]} $throwable")
}
GlobalScope.launch(Dispatchers.Main + CoroutineName("scope1") + exceptionHandler) {
supervisorScope {
Log.d("scope", "--------- 1")
launch(CoroutineName("scope2")) {
Log.d("scope", "--------- 2")
throw NullPointerException("空指针")
Log.d("scope", "--------- 3")
val scope3 = launch(CoroutineName("scope3")) {
Log.d("scope", "--------- 4")
delay(2000)
Log.d("scope", "--------- 5")
}
scope3.join()
}
val scope4 = launch(CoroutineName("scope4")) {
Log.d("scope", "--------- 6")
delay(2000)
Log.d("scope", "--------- 7")
}
scope4.join()
Log.d("scope", "--------- 8")
}
}
}
#子协程scope2抛出了一个异常,并将异常传递给父协程scope1处理,同时也结束了自己本身。
# 因为在于主从(监督)作用域下的协程取消操作是单向传播性,因此协程scope2的异常并没有导致父协程退出
# 所以6 7 8都照常输出,而3 4 5因为在协程scope2里面所以没有输出
D/scope: --------- 1
D/scope: --------- 2
D/exceptionHandler: CoroutineName(scope2) java.lang.NullPointerException: 空指针
D/scope: --------- 6
D/scope: --------- 7
D/scope: --------- 8
SupervisorJob
主从(监督)作用域 SupervisorJob的另外一个实例
private fun testCoroutineScope4() {
val exceptionHandler = CoroutineExceptionHandler { coroutineContext, throwable ->
Log.d("exceptionHandler", "${coroutineContext[CoroutineName]} $throwable")
}
#我们通过创建了一个SupervisorJob的主从(监督)协程作用域
val coroutineScope = CoroutineScope(SupervisorJob() +CoroutineName("coroutineScope"))
GlobalScope.launch(Dispatchers.Main + CoroutineName("scope1") + exceptionHandler) {
with(coroutineScope){
val scope2 = launch(CoroutineName("scope2") + exceptionHandler) {
Log.d("scope", "1--------- ${coroutineContext[CoroutineName]}")
throw NullPointerException("空指针")
}
val scope3 = launch(CoroutineName("scope3") + exceptionHandler) {
scope2.join()
Log.d("scope", "2--------- ${coroutineContext[CoroutineName]}")
delay(2000)
Log.d("scope", "3--------- ${coroutineContext[CoroutineName]}")
}
#调用了子协程的join是为了保证它一定是会执行
scope2.join()
Log.d("scope", "4--------- ${coroutineContext[CoroutineName]}")
coroutineScope.cancel()
scope3.join()
Log.d("scope", "5--------- ${coroutineContext[CoroutineName]}")
}
Log.d("scope", "6--------- ${coroutineContext[CoroutineName]}")
}
}
# 子协程scope2抛出了一个异常,通过协程scope2自己内部消化了,同时也结束了自己本身
# 因为协程scope2的异常并没有导致coroutineScope作用域下的协程取消退出,所以协程scope3照常运行输出2
# 后又因为调用了我们定义的协程作用域coroutineScope的cancel方法取消了协程,
# 所以即使我们后面调用了协程scope3的join,也没有输出3
# 因为SupervisorJob的取消是向下传播的,所以后面的45都是在coroutineScope的作用域中输出的
D/scope: 1--------- CoroutineName(scope2)
D/exceptionHandler: CoroutineName(scope2) java.lang.NullPointerException: 空指针
D/scope: 2--------- CoroutineName(scope3)
D/scope: 4--------- CoroutineName(coroutineScope)
D/scope: 5--------- CoroutineName(coroutineScope)
D/scope: 6--------- CoroutineName(scope1)
4.2 作用域技术实现
public interface CoroutineScope {
public val coroutineContext: CoroutineContext
}
public operator fun CoroutineScope.plus(context: CoroutineContext): CoroutineScope =
ContextScope(coroutineContext + context)
public fun MainScope(): CoroutineScope = ContextScope(SupervisorJob() + Dispatchers.Main)
public object GlobalScope : CoroutineScope {
override val coroutineContext: CoroutineContext
get() = EmptyCoroutineContext
}
public fun CoroutineScope(context: CoroutineContext): CoroutineScope =
ContextScope(if (context[Job] != null) context else context + Job())
- CoroutineScope接口只做了一个事,就是持有上下文,上下文我们后边再讲
- 我们可以看到
CoroutineScope也重载了plus方法,通过+号来新增或者修改我们CoroutineContext协程上下文中的Element - 官方也为我们定义好了
MainScope和GlobalScope2个顶级作用域
-
MainScope我们可以看到它的上下文是通过SupervisorJob和Dispatchers.Main组合的,说明它是一个在主线程执行的协程作用域,我们在后续的Android实战开发中,会结合Activity、Fragment,dialog等使用它。这里不再继续往下扩展
4.2.1 coroutineScope创建默认协程作用域
public suspend fun <R> coroutineScope(block: suspend CoroutineScope.() -> R): R {
contract {
callsInPlace(block, InvocationKind.EXACTLY_ONCE)
}
return suspendCoroutineUninterceptedOrReturn { uCont ->
val coroutine = ScopeCoroutine(uCont.context, uCont)
coroutine.startUndispatchedOrReturn(coroutine, block)
}
}除了不同构建器提供的协程作用域外,还可以使用 coroutineScope 构建器声明自己的作用域。它创建一个协程作用域,并且在所有启动的子项都完成之前不会完成。
- runBlocking 和 coroutineScope 构建器可能看起来很相似,因为它们都在等待其主体及其所有子体完成。
- 主要区别在于 runBlocking 方法会阻止当前线程等待而 coroutineScope 只是挂起,释放底层线程以进行其他用法。
由于这种差异,runBlocking 是一个常规函数,而 coroutineScope 是一个挂起函数。
import kotlinx.coroutines.*
//sampleStart
fun main() = runBlocking {
doWorld()
}
suspend fun doWorld() = coroutineScope { // this: CoroutineScope
launch {
delay(1000L)
println("World!")
}
println("Hello")
}
//sampleEndcoroutineScope 构建器可以在任何挂起函数内部使用,以执行多个并发操作。让我们在 doWorld 挂起函数中启动两个并发协程:
import kotlinx.coroutines.*
//sampleStart
// Sequentially executes doWorld followed by "Done"
fun main() = runBlocking {
doWorld()
println("Done")
}
// Concurrently executes both sections
suspend fun doWorld() = coroutineScope { // this: CoroutineScope
launch {
delay(2000L)
println("World 2")
}
launch {
delay(1000L)
println("World 1")
}
println("Hello")
}
//sampleEndlaunch { ... } 块内的两段代码同时执行,首先打印 World 1,在开始一秒后,然后打印 World 2,在开始后两秒后打印。doWorld 中的 coroutineScope 只有在两者都完成后才会完成,因此 doWorld 仅在此之后返回并允许打印 Done 字符串:
Hello
World 1
World 2
Done4.3 妙用协程作用域关闭协程
让我们将关于上下文,子协程以及作业的知识综合在一起。假设我们的应用程序拥有一个具有生命周期的对象,但这个对象并不是一个协程。举例来说,我们编写了一个 Android 应用程序并在 Android 的 activity 上下文中启动了一组协程来使用异步操作拉取并更新数据以及执行动画等等。所有这些协程必须在这个 activity 销毁的时候取消以避免内存泄漏。当然,我们也可以手动操作上下文与作业,以结合 activity 的生命周期与它的协程,但是 kotlinx.coroutines 提供了一个封装:CoroutineScope 的抽象。 你应该已经熟悉了协程作用域,因为所有的协程构建器都声明为在它之上的扩展。
我们通过创建一个 CoroutineScope 实例来管理协程的生命周期,并使它与 activity 的生命周期相关联。CoroutineScope 可以通过 CoroutineScope() 创建或者通过MainScope() 工厂函数。前者创建了一个通用作用域,而后者为使用 Dispatchers.Main 作为默认调度器的 UI 应用程序 创建作用域
在 main 函数中我们创建 activity,调用测试函数 doSomething,并且在 500 毫秒后销毁这个 activity。 这取消了从 doSomething 启动的所有协程。我们可以观察到这些是由于在销毁之后, 即使我们再等一会儿,activity 也不再打印消息。
import kotlinx.coroutines.*
class Activity {
private val mainScope = CoroutineScope(Dispatchers.Default) // use Default for test purposes
fun destroy() {
mainScope.cancel()
}
fun doSomething() {
// 在示例中启动了 10 个协程,且每个都工作了不同的时长
repeat(10) { i ->
mainScope.launch {
delay((i + 1) * 200L) // 延迟 200 毫秒、400 毫秒、600 毫秒等等不同的时间
println("Coroutine $i is done")
}
}
}
} // Activity 类结束
fun main() = runBlocking<Unit> {
//sampleStart
val activity = Activity()
activity.doSomething() // 运行测试函数
println("Launched coroutines")
delay(500L) // 延迟半秒钟
println("Destroying activity!")
activity.destroy() // 取消所有的协程
delay(1000) // 为了在视觉上确认它们没有工作
//sampleEnd
}这个示例的输出如下所示:
Launched coroutines
Coroutine 0 is done
Coroutine 1 is done
Destroying activity!五、【1rd协程上下文】 CoroutineContext
协程上下文存储用于运行给定协程的其他技术信息,例如协程自定义名称,或指定应调度协程的线程的调度程序。
5.1 基础实现
本质
协程上下文是一个包含了用户定义的一些各种不同元素的Element对象集合
plus有个关键字operator表示这是一个运算符重载的方法,类似List.plus的运算符,可以通过+号来返回一个包含原始集合和第二个操作数中的元素的结果。同理CoroutineContext中是通过plus来返回一个由原始的Element集合和通过+号引入的Element产生新的Element集合。minusKey方法plus作用相反,它相当于是做减法, 是用来取出除key以外的当前协程上下文其他Element,返回的就是不包含key的协程上下文。get方法,顾名思义。可以通过key来获取一个Elementfold方法它和集合中的fold是一样的,用来遍历当前协程上下文中的Element集合。
public interface CoroutineContext {
public operator fun <E : CoroutineContext.Element> get(key: Key<E>): E?
public fun <R> fold(initial: R, operation: (R, CoroutineContext.Element) -> R): R
public operator fun plus(context: CoroutineContext): CoroutineContext =
if (context === EmptyCoroutineContext) this else context.fold(this) { ...}
public fun minusKey(key: Key<*>): CoroutineContext
}
Key和Element
public interface CoroutineContext {
public interface Key <E : CoroutineContext.Element>
public interface Element : CoroutineContext {
public val key: Key<*>
public override operator fun <E : Element> get(key: Key<E>): E? =
if (this.key == key) this as E else null
public override fun <R> fold(initial: R, operation: (R, Element) -> R): R =
operation(initial, this)
public override fun minusKey(key: Key<*>): CoroutineContext =
if (this.key == key) EmptyCoroutineContext else this
}
}
Element是CoroutineContext的内部接口,同时它又实现了CoroutineContext接口,这么设计的原因是为了保证Element中一定只能存放的Element它自己,而不能存放其他类型的数据- 另一个内部接口
Key标记了Element的类型
Element的实现
|
类型 |
接口/类 |
主要用途 |
示例 |
|
|
|
控制协程的生命周期,支持取消和完成操作。 |
|
|
|
|
决定协程的执行线程或线程池。 |
|
|
|
|
为协程指定名称,方便调试。 |
|
|
|
|
处理未捕获的异常,提供全局异常处理机制。 |
|
|
|
|
在协程切换线程时保存和恢复线程局部变量(如 )。 |
|
public interface Job : CoroutineContext.Element {
public companion object Key : CoroutineContext.Key<Job> {
//省略...
}
}
public abstract class CoroutineDispatcher :
AbstractCoroutineContextElement(ContinuationInterceptor), ContinuationInterceptor {
public companion object Key : AbstractCoroutineContextKey<ContinuationInterceptor, CoroutineDispatcher>(
ContinuationInterceptor,
{ it as? CoroutineDispatcher })
}
public interface CoroutineExceptionHandler : CoroutineContext.Element {
public companion object Key : CoroutineContext.Key<CoroutineExceptionHandler>
}
public interface ContinuationInterceptor : CoroutineContext.Element {
companion object Key : CoroutineContext.Key<ContinuationInterceptor>
}
public data class CoroutineName(
val name: String
) : AbstractCoroutineContextElement(CoroutineName) {
public companion object Key : CoroutineContext.Key<CoroutineName>
}
5.2 CoroutineName
private fun testCoroutineScope(){
GlobalScope.launch(Dispatchers.Main){
Log.d("父协程上下文", "$coroutineContext")
launch(CoroutineName("第一个子协程")) {
Log.d("第一个子协程上下文", "$coroutineContext")
}
launch(Dispatchers.Unconfined) {
Log.d("第二个子协程协程上下文", "$coroutineContext")
}
}
}5.3 CoroutineExceptionHandler
见4.1.2 协同作用域的异常处理
5.4 Job
见3.2.4 协程返回值:作业Job 、Deferred, 默认会生成一个Job并返回
见4.1.3 主从(监督)作用域 supervisorScope
|
|
描述 |
特点 |
|
|
最基础的 实现,不附加任何额外功能。 |
无父子关系,独立运行。 |
|
|
可手动控制完成的 ,通常由 |
支持手动完成或异常完成。 |
|
|
一种特殊的 ,不会因为子协程的失败而取消父协程。 |
适用于需要单独处理子协程错误的场景。 |
|
|
表示一个子协程的 ,与父协程绑定。 |
子协程会继承父协程的上下文,并受父协程的生命周期影响。 |
|
|
一种特殊的 ,无法被取消,始终处于活动状态。 |
适用于需要确保某些代码块在取消时仍能执行的场景。 |
import kotlinx.coroutines.*
fun main() = runBlocking {
val job = Job()
launch(job) {
println("Running in a new coroutine")
}
job.cancel() // 取消协程
}- 创建一个普通的
Job,并将其绑定到协程。 - 调用
cancel()方法可以取消协程。
5.5 协程调度器和线程 CoroutineDispatcher
协程默认是在当前线程执行。协程上下文包含一个 协程调度器 (参见 CoroutineDispatcher)它确定了相关的协程在哪个线程或哪些线程上执行。协程调度器可以将协程限制在一个特定的线程执行,或将它分派到一个线程池,亦或是让它不受限地运行。
一个线程的多个协程的运行是串行的。如果是多核CPU,多个进程或一个进程内的多个线程是可以并行运行的,但是一个线程内协程却绝对是串行的,无论CPU有多少个核。毕竟协程虽然是一个特殊的函数,但仍然是一个函数。一个线程内可以运行多个函数,但这些函数都是串行运行的,当仅存在一个线程那么一个协程运行时其它协程必须挂起
所有的协程构建器诸如 launch 和 async 接收一个可选的 CoroutineContext 参数,它可以被用来显式的为一个新协程或其它上下文元素指定一个调度器。对于调度器的实现机制我们已经非常清楚了,官方框架中预置了4个调度器,我们可以通过Dispatchers对象直接访问它们:
Default:默认调度器,CPU密集型任务调度器,适合处理后台计算。通常处理一些单纯的计算任务,或者执行时间较短任务。比如:Json的解析,数据计算等IO:IO调度器,,IO密集型任务调度器,适合执行IO相关操作。比如:网络处理,数据库操作,文件操作等Main:UI调度器, 即在主线程上执行,通常用于UI交互,刷新等Unconfined:非受限调度器,又或者称为“无所谓”调度器,不要求协程执行在特定线程上
kotlin
代码解读
复制代码public actual object Dispatchers {
@JvmStatic
public actual val Default: CoroutineDispatcher = createDefaultDispatcher()
@JvmStatic
public actual val Main: MainCoroutineDispatcher
get() = MainDispatcherLoader.dispatcher
@JvmStatic
public actual val Unconfined: CoroutineDispatcher = kotlinx.coroutines.Unconfined
@JvmStatic
public val IO: CoroutineDispatcher = DefaultScheduler.IO
}5.5.1 理解线程调度
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
//sampleStart
launch { // 运行在父协程的上下文中,即 runBlocking 主协程
println("main runBlocking : I'm working in thread ${Thread.currentThread().name}")
}
launch(Dispatchers.Unconfined) { // 不受限的——将工作在主线程中
println("Unconfined : I'm working in thread ${Thread.currentThread().name}")
}
launch(Dispatchers.Default) { // 将会获取默认调度器
println("Default : I'm working in thread ${Thread.currentThread().name}")
}
launch(newSingleThreadContext("MyOwnThread")) { // 将使它获得一个新的线程
println("newSingleThreadContext: I'm working in thread ${Thread.currentThread().name}")
}
//sampleEnd
}它执行后得到了如下输出(也许顺序会有所不同):
Unconfined : I'm working in thread main
Default : I'm working in thread DefaultDispatcher-worker-1
newSingleThreadContext: I'm working in thread MyOwnThread
main runBlocking : I'm working in thread main- 当调用
launch { …… }时不传参数,它从启动了它的 CoroutineScope 中承袭了上下文(以及调度器)。在这个案例中,它从main线程中的runBlocking主协程承袭了上下文。 - Dispatchers.Unconfined 是一个特殊的调度器且似乎也运行在
main线程中,但实际上, 它是一种不同的机制,这会在后文中讲到。 - 当在作用域中没有显式指定其他分派器时,将使用默认分派器。它由Dispatchers表示。默认并使用共享的后台线程池。
- newSingleThreadContext 为协程的运行启动了一个线程。 一个专用的线程是一种非常昂贵的资源。 在真实的应用程序中两者都必须被释放,当不再需要的时候,使用 close 函数,或存储在一个顶层变量中使它在整个应用程序中被重用。
5.5.2 Dispatchers.Unconfined
Dispatchers.Unconfined协程调度器在调用它的线程启动了一个协程,但它仅仅只是运行到第一个挂起点,挂起后,它恢复线程中的协程
mport kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
//sampleStart
launch(Dispatchers.Unconfined) { // 非受限的——将和主线程一起工作
println("Unconfined : I'm working in thread ${Thread.currentThread().name}")
delay(500)
println("Unconfined : After delay in thread ${Thread.currentThread().name}")
}
launch { // 父协程的上下文,主 runBlocking 协程
println("main runBlocking: I'm working in thread ${Thread.currentThread().name}")
delay(1000)
println("main runBlocking: After delay in thread ${Thread.currentThread().name}")
}
//sampleEnd
}执行后的输出:
Unconfined : I'm working in thread main
main runBlocking: I'm working in thread main
Unconfined : After delay in thread kotlinx.coroutines.DefaultExecutor
main runBlocking: After delay in thread main5.5.3 GlobalScope.async 或 GlobalScope.launch 使用默认调度
GlobalScope.launch启动的时候,没有传入参数际上它使用的是默认调度器Dispatchers.Default
import kotlinx.coroutines.*
fun main() =runBlocking<Unit> { start()}
private suspend fun start(){
coroutineScope {
val runBlockingJob = runBlocking {
println("runBlocking 启动一个协程")
41
}
println("runBlockingJob $runBlockingJob")
val launchJob = launch{
println("launch 启动一个协程")
}
println("launchJob $launchJob")
val asyncJob = async{
println("async 启动一个协程")
"我是返回值"
}
println("asyncJob $asyncJob")
}
}
一定输出下列顺序,因为协程在同一个线程上
runBlocking 启动一个协程
runBlockingJob 41
launchJob "coroutine#3":StandaloneCoroutine{Active}@7a92922
asyncJob "coroutine#4":DeferredCoroutine{Active}@6ad5c04e
launch 启动一个协程
async 启动一个协程但是
import kotlinx.coroutines.*
fun main() =runBlocking<Unit> { start()}
private suspend fun start(){
coroutineScope {
val runBlockingJob = runBlocking {
println("runBlocking 启动一个协程")
println("runBlocking : I'm working in thread ${Thread.currentThread().name}")
41
}
println("runBlockingJob $runBlockingJob")
val launchJob = GlobalScope.launch{
println("launch 启动一个协程")
println("launch: I'm working in thread ${Thread.currentThread().name}")
}
println("launchJob $launchJob")
val asyncJob = GlobalScope.async{
println("async 启动一个协程")
println("async: I'm working in thread ${Thread.currentThread().name}")
"我是返回值"
}
println("asyncJob $asyncJob")
println(asyncJob.await())
}
}可能有多种输出,因为GlobalScope会引入一套独立线程池
runBlocking 启动一个协程
runBlockingJob 41
launch 启动一个协程
launchJob "coroutine#3":StandaloneCoroutine{Completed}@357246de
asyncJob "coroutine#4":DeferredCoroutine{Active}@1b40d5f0
async 启动一个协程
runBlocking 启动一个协程
runBlocking : I'm working in thread main @coroutine#2
runBlockingJob 41
launchJob "coroutine#3":StandaloneCoroutine{Active}@357246de
launch 启动一个协程
launch: I'm working in thread DefaultDispatcher-worker-1 @coroutine#3
asyncJob "coroutine#4":DeferredCoroutine{Active}@1b40d5f0
async 启动一个协程
async: I'm working in thread DefaultDispatcher-worker-2 @coroutine#4
我是返回值最后我们推测下一段代码的执行顺序
private fun start(){
GlobalScope.launch{
val launchJob = launch{
Log.d("launch", "启动一个协程")
}
Log.d("launchJob", "$launchJob")
val asyncJob = async{
Log.d("async", "启动一个协程")
"我是async返回值"
}
Log.d("asyncJob.await", ":${asyncJob.await()}")
Log.d("asyncJob", "$asyncJob")
}
}
D/launchJob: StandaloneCoroutine{Active}@f3d8da3
D/async: 启动一个协程
D/launch: 启动一个协程
D/asyncJob.await: :我是async返回值
D/asyncJob: DeferredCoroutine{Completed}@d6f28a0
D/launchJob: StandaloneCoroutine{Active}@f3d8da3
D/launch: 启动一个协程
D/async: 启动一个协程
D/asyncJob.await: :我是async返回值
D/asyncJob: DeferredCoroutine{Completed}@d6f28a0
同一协程内顺序执行
由于await的存在,导致"asyncJob.await"一定会等待async协程执行完毕,
但是async协程和launch协程可能在不同线程启动,所以顺序不能保证
5.5.4 协程并发管理
线程局部数据
有时,能够将一些线程局部数据传递到协程与协程之间是很方便的。 然而,由于它们不受任何特定线程的约束,如果手动完成,可能会导致出现样板代码。
ThreadLocal, asContextElement 扩展函数在这里会充当救兵。它创建了额外的上下文元素, 且保留给定 ThreadLocal 的值,并在每次协程切换其上下文时恢复它。
import kotlinx.coroutines.*
val threadLocal = ThreadLocal<String?>() // 声明线程局部变量
fun main() = runBlocking<Unit> {
//sampleStart
threadLocal.set("main")
println("Pre-main, current thread: ${Thread.currentThread()}, thread local value: '${threadLocal.get()}'")
val job = launch(Dispatchers.Default + threadLocal.asContextElement(value = "launch")) {
println("Launch start, current thread: ${Thread.currentThread()}, thread local value: '${threadLocal.get()}'")
yield()
println("After yield, current thread: ${Thread.currentThread()}, thread local value: '${threadLocal.get()}'")
}
job.join()
println("Post-main, current thread: ${Thread.currentThread()}, thread local value: '${threadLocal.get()}'")
//sampleEnd
}在这个例子中我们使用 Dispatchers.Default 在后台线程池中启动了一个新的协程,所以它工作在线程池中的不同线程中,但它仍然具有线程局部变量的值, 我们指定使用 threadLocal.asContextElement(value = "launch"), 无论协程执行在哪个线程中都是没有问题的。 因此,其输出如(调试)所示:
Pre-main, current thread: Thread[main @coroutine#1,5,main], thread local value: 'main'
Launch start, current thread: Thread[DefaultDispatcher-worker-1 @coroutine#2,5,main], thread local value: 'launch'
After yield, current thread: Thread[DefaultDispatcher-worker-2 @coroutine#2,5,main], thread local value: 'launch'
Post-main, current thread: Thread[main @coroutine#1,5,main], thread local value: 'main'基于多线程的协程并发管理
以细粒度限制线程
限制线程 是解决共享可变状态问题的一种方案:对特定共享状态的所有访问权都限制在单个线程中。它通常应用于 UI 程序中:所有 UI 状态都局限于单个事件分发线程或应用主线程中。这在协程中很容易实现,通过使用一个单线程上下文。
import kotlinx.coroutines.*
import kotlin.system.*
suspend fun massiveRun(action: suspend () -> Unit) {
val n = 100 // 启动的协程数量
val k = 1000 // 每个协程重复执行同一动作的次数
val time = measureTimeMillis {
coroutineScope { // 协程的作用域
repeat(n) {
launch {
repeat(k) { action() }
}
}
}
}
println("Completed ${n * k} actions in $time ms")
}
//sampleStart
val counterContext = newSingleThreadContext("CounterContext")
var counter = 0
fun main() = runBlocking {
withContext(Dispatchers.Default) {
massiveRun {
// 将每次自增限制在单线程上下文中
withContext(counterContext) {
counter++
}
}
}
println("Counter = $counter")
}这段代码运行非常缓慢,因为它进行了 细粒度 的线程限制。每个增量操作都得使用 [withContext(counterContext)] 块从多线程 Dispatchers.Default 上下文切换到单线程上下文。
以粗粒度限制线程
在实践中,线程限制是在大段代码中执行的,例如:状态更新类业务逻辑中大部分都是限于单线程中。下面的示例演示了这种情况, 在单线程上下文中运行每个协程。
import kotlinx.coroutines.*
import kotlin.system.*
suspend fun massiveRun(action: suspend () -> Unit) {
val n = 100 // 启动的协程数量
val k = 1000 // 每个协程重复执行同一动作的次数
val time = measureTimeMillis {
coroutineScope { // 协程的作用域
repeat(n) {
launch {
repeat(k) { action() }
}
}
}
}
println("Completed ${n * k} actions in $time ms")
}
//sampleStart
val counterContext = newSingleThreadContext("CounterContext")
var counter = 0
fun main() = runBlocking {
// 将一切都限制在单线程上下文中
withContext(counterContext) {
massiveRun {
counter++
}
}
println("Counter = $counter")
}
//sampleEnd可以在这里获取完整代码。
这段代码运行更快而且打印出了正确的结果。
互斥
该问题的互斥解决方案:使用永远不会同时执行的 关键代码块 来保护共享状态的所有修改。在阻塞的世界中,你通常会为此目的使用 synchronized 或者 ReentrantLock。 在协程中的替代品叫做 Mutex 。它具有 lock 和 unlock 方法, 可以隔离关键的部分。关键的区别在于 Mutex.lock() 是一个挂起函数,它不会阻塞线程。
还有 withLock 扩展函数,可以方便的替代常用的 mutex.lock(); try { …… } finally { mutex.unlock() } 模式:
import kotlinx.coroutines.*
import kotlinx.coroutines.sync.*
import kotlin.system.*
suspend fun massiveRun(action: suspend () -> Unit) {
val n = 100 // 启动的协程数量
val k = 1000 // 每个协程重复执行同一动作的次数
val time = measureTimeMillis {
coroutineScope { // 协程的作用域
repeat(n) {
launch {
repeat(k) { action() }
}
}
}
}
println("Completed ${n * k} actions in $time ms")
}
//sampleStart
val mutex = Mutex()
var counter = 0
fun main() = runBlocking {
withContext(Dispatchers.Default) {
massiveRun {
// 用锁保护每次自增
mutex.withLock {
counter++
}
}
}
println("Counter = $counter")
}
//sampleEnd可以在这里获取完整代码。
此示例中锁是细粒度的,因此会付出一些代价。但是对于某些必须定期修改共享状态的场景,它是一个不错的选择,但是没有自然线程可以限制此状态。
5.6 上下文的继承和切换
5.6.1 上下文的继承
嵌套协程(在示例中由 launch 启动)可以被视为外部协程(由 runBlocking 启动)的子协程。这种“父子”关系通过范围起作用; 子协程从与父协程对应的作用域开始。 所有嵌套协程都会自动使用继承的上下文启动。调度程序是此上下文的一部分。这就是为什么所有由 async 启动的协程都是在默认调度程序的上下文下启动的:
suspend fun loadContributorsConcurrent(
service: GitHubService, req: RequestData
): List<User> = coroutineScope {
// this scope inherits the context from the outer scope
// ...
async { // nested coroutine started with the inherited context
// ...
}
// ...
}- 当一个协程被其它协程在 CoroutineScope 中启动的时候, 它将通过 CoroutineScope.coroutineContext 来承袭上下文,并且这个新协程的 Job 将会成为父协程作业的 子 作业。当一个父协程被取消的时候,所有它的子协程也会被递归的取消。
-
- 这种父子关系可以通过以下两种方式之一显式重写:
-
-
- 如果在启动协程时显式指定了不同的作用域(例如,GlobalScope.launch),则它不会从父作用域继承Job。
- 当传递不同的Job对象作为新协程的上下文时(如下面的示例所示),它将覆盖父作用域的Job。
-
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
//sampleStart
// 启动一个协程来处理某种传入请求(request)
val request = launch {
// 生成了两个子作业
launch(Job()) {
println("job1: I run in my own Job and execute independently!")
delay(1000)
println("job1: I am not affected by cancellation of the request")
}
// 另一个则承袭了父协程的上下文
launch {
delay(100)
println("job2: I am a child of the request coroutine")
delay(1000)
println("job2: I will not execute this line if my parent request is cancelled")
}
}
delay(500)
request.cancel() // 取消请求(request)的执行
println("main: Who has survived request cancellation?")
delay(1000) // 主线程延迟一秒钟来看看发生了什么
//sampleEnd
}这段代码的输出如下:
job1: I run in my own Job and execute independently!
job2: I am a child of the request coroutine
main: Who has survived request cancellation?
job1: I am not affected by cancellation of the request- 一个父协程总是等待所有的子协程执行结束。父协程并不显式的跟踪所有子协程的启动,并且不必使用 Job.join 在最后的时候等待它们:
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
//sampleStart
// 启动一个协程来处理某种传入请求(request)
val request = launch {
repeat(3) { i -> // 启动少量的子作业
launch {
delay((i + 1) * 200L) // 延迟 200 毫秒、400 毫秒、600 毫秒的时间
println("Coroutine $i is done")
}
}
println("request: I'm done and I don't explicitly join my children that are still active")
}
request.join() // 等待请求的完成,包括其所有子协程
println("Now processing of the request is complete")
//sampleEnd
}结果如下所示:
request: I'm done and I don't explicitly join my children that are still active
Coroutine 0 is done
Coroutine 1 is done
Coroutine 2 is done
Now processing of the request is complete
runBlocking 启动一个协程
runBlocking : I'm working in thread main @coroutine#2
runBlockingJob 41
launch 启动一个协程
launch: I'm working in thread DefaultDispatcher-worker-1 @coroutine#3
launchJob "coroutine#3":StandaloneCoroutine{Completed}@357246de
asyncJob "coroutine#4":DeferredCoroutine{Active}@1b40d5f05.6.2 上下文的切换withContext 切换后立即执行,本身也是个挂起函数
withContext:同步挂起当前协程,立即执行代码块并返回结果withContext切换线程后,目标代码块会立即执行。
我们好像只有在启动协程的时候,才能指定具体使用那个Dispatchers调度器。如果我要是想中途切换线程怎么办,比如:现在我们需要通过网络请求获取到数据的时候填充到我们的布局当中,但是网络处理在IO线程上,而刷新UI是在主线程上,那我们应该怎么办。
withContext这个东西好像很符合我们的需求嘛,我们可以先使用launch(Dispatchers.Main)启动协程,然后再通过withContext(Dispatchers.IO)调度到IO线程上去做网络请求,把得到的结果返回,这样我们就解决了我们上面的问题了。
GlobalScope.launch(Dispatchers.Main) {
val result = withContext(Dispatchers.IO) {
//网络请求...
"请求结果"
}
btn.text = result
}六、协程的挂起-->启动并发
使用suspend关键字修饰的函数叫作挂起函数,挂起函数只能在协程体内,或着在其他挂起函数内调用
在编译期,Kotlin将suspend标记的方法转化成接口回调的方式,本质上还是基于回调实现的。
6.1 挂起
首先一个挂起函数既然要挂起,那么他必定得有一个挂起点,不然我们怎么知道函数是否挂起,从哪挂起呢。 我们定义一个空实现的suspend方法,然后通过AS的工具栏中Tools->kotlin->show kotlin ByteCode解析成字节码
private suspend fun test(){
}
final synthetic test(Lkotlin/coroutines/Continuation;)Ljava/lang/Object;
我们看到挂起函数test方法需要的是一个Continuation接口,官方给的介绍是用于挂起点之后,返回类型为T的值用的。
public interface Continuation<in T> {
public val context: CoroutineContext
public fun resumeWith(result: Result<T>)
}
那我们又是怎么拿到的这个Continuation呢
# 我们看到在通过launch启动一个协程的时候,他通过coroutine的start方法启动协程
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job {
val newContext = newCoroutineContext(context)
val coroutine = if (start.isLazy)
LazyStandaloneCoroutine(newContext, block) else
StandaloneCoroutine(newContext, active = true)
coroutine.start(start, coroutine, block)
return coroutine
}
#AbstractCoroutine
public fun <R> start(start: CoroutineStart, receiver: R, block: suspend R.() -> T) {
initParentJob()
start(block, receiver, this)
}
#CoroutineStart
# block就是我们构建的协程体,启动协程时,会把协程自身传入
public operator fun <R, T> invoke(block: suspend R.() -> T, receiver: R, completion: Continuation<T>): Unit =
when (this) {
DEFAULT -> block.startCoroutineCancellable(receiver, completion)
ATOMIC -> block.startCoroutine(receiver, completion)
UNDISPATCHED -> block.startCoroutineUndispatched(receiver, completion)
LAZY -> Unit // will start lazily
}
public fun <T> (suspend () -> T).startCoroutineCancellable(completion: Continuation<T>): Unit = runSafely(completion) {
createCoroutineUnintercepted(completion).intercepted().resumeCancellableWith(Result.success(Unit))
}在协程内部挂起函数的调用处就是挂起点,如果挂起点出现异步调用,那么当前协程就被挂起,直到对应的Continuation通过调用resumeWith函数才会恢复协程的执行,同时返回Result<T>类型的成功或者失败的结果。
6.2 异步流Flow
七、协程的取消
7.1 取消协程的执行
在一个长时间运行的应用程序中,你也许需要对你的后台协程进行细粒度的控制。 比如说,一个用户也许关闭了一个启动了协程的界面,那么现在协程的执行结果已经不再被需要了,这时,它应该是可以被取消的。 该 launch 函数返回了一个可以被用来取消运行中的协程的 Job:
import kotlinx.coroutines.*
fun main() = runBlocking {
//sampleStart
val job = launch {
repeat(1000) { i ->
println("job: I'm sleeping $i ...")
delay(500L)
}
}
delay(1300L) // 延迟一段时间
println("main: I'm tired of waiting!")
job.cancel() // 取消该作业
job.join() // 等待作业执行结束
println("main: Now I can quit.")
//sampleEnd
}程序执行后的输出如下:
job: I'm sleeping 0 ...
job: I'm sleeping 1 ...
job: I'm sleeping 2 ...
main: I'm tired of waiting!
main: Now I can quit.一旦 main 函数调用了 job.cancel,我们在其它的协程中就看不到任何输出,因为它被取消了。 这里也有一个可以使 Job 挂起的函数 cancelAndJoin 它合并了对 cancel 以及 join 的调用。
7.2 取消是协作的
协程的取消是 协作 的。一段协程代码必须协作才能被取消。 所有 kotlinx.coroutines 中的挂起函数都是 可被取消的 。它们检查协程的取消, 并在取消时抛出 CancellationException。 然而,如果协程正在执行计算任务,并且没有检查取消的话,那么它是不能被取消的,就如如下示例代码所示:
import kotlinx.coroutines.*
fun main() = runBlocking {
//sampleStart
val startTime = System.currentTimeMillis()
val job = launch(Dispatchers.Default) {
var nextPrintTime = startTime
var i = 0
while (i < 5) { // 一个执行计算的循环,只是为了占用 CPU
// 每秒打印消息两次
if (System.currentTimeMillis() >= nextPrintTime) {
println("job: I'm sleeping ${i++} ...")
nextPrintTime += 500L
}
}
}
delay(1300L) // 等待一段时间
println("main: I'm tired of waiting!")
job.cancelAndJoin() // 取消一个作业并且等待它结束
println("main: Now I can quit.")
//sampleEnd
}运行示例代码,并且我们可以看到它连续打印出了“I'm sleeping”,甚至在调用取消后, 作业仍然执行了五次循环迭代并运行到了它结束为止。
The same problem can be observed by catching a CancellationException and not rethrowing it:
import kotlinx.coroutines.*
fun main() = runBlocking {
//sampleStart
val job = launch(Dispatchers.Default) {
repeat(5) { i ->
try {
// print a message twice a second
println("job: I'm sleeping $i ...")
delay(500)
} catch (e: Exception) {
// log the exception
println(e)
}
}
}
delay(1300L) // delay a bit
println("main: I'm tired of waiting!")
job.cancelAndJoin() // cancels the job and waits for its completion
println("main: Now I can quit.")
//sampleEnd
}While catching Exception is an anti-pattern, this issue may surface in more subtle ways, like when using the runCatching function, which does not rethrow CancellationException.
7.3 使计算中的代码可取消
- 我们有两种方法来使执行计算的代码可以被取消。第一种方法是定期调用挂起函数来检查取消。对于这种目的 yield 是一个好的选择。 另一种方法是显式的检查取消状态。让我们试试第二种方法。
while (isActive)
将前一个示例中的 while (i < 5) 替换为 while (isActive) 并重新运行它。
import kotlinx.coroutines.*
fun main() = runBlocking {
//sampleStart
val startTime = System.currentTimeMillis()
val job = launch(Dispatchers.Default) {
var nextPrintTime = startTime
var i = 0
while (isActive) { // 可以被取消的计算循环
// 每秒打印消息两次
if (System.currentTimeMillis() >= nextPrintTime) {
println("job: I'm sleeping ${i++} ...")
nextPrintTime += 500L
}
}
}
delay(1300L) // 等待一段时间
println("main: I'm tired of waiting!")
job.cancelAndJoin() // 取消该作业并等待它结束
println("main: Now I can quit.")
//sampleEnd
}你可以看到,现在循环被取消了。isActive 是一个可以被使用在 CoroutineScope 中的扩展属性。
CancellationException
- 在
finally中释放资源
我们通常使用如下的方法处理在被取消时抛出 CancellationException 的可被取消的挂起函数。比如说,try {……} finally {……} 表达式以及 Kotlin 的 use 函数一般在协程被取消的时候执行它们的终结动作:
import kotlinx.coroutines.*
fun main() = runBlocking {
//sampleStart
val job = launch {
try {
repeat(1000) { i ->
println("job: I'm sleeping $i ...")
delay(500L)
}
} finally {
println("job: I'm running finally")
}
}
delay(1300L) // 延迟一段时间
println("main: I'm tired of waiting!")
job.cancelAndJoin() // 取消该作业并且等待它结束
println("main: Now I can quit.")
//sampleEnd
}可以在这里获取完整代码。
join 和 cancelAndJoin 等待了所有的终结动作执行完毕, 所以运行示例得到了下面的输出:
job: I'm sleeping 0 ...
job: I'm sleeping 1 ...
job: I'm sleeping 2 ...
main: I'm tired of waiting!
job: I'm running finally
main: Now I can quit.7.4 运行不能取消的代码块
在前一个例子中任何尝试在 finally 块中调用挂起函数的行为都会抛出 CancellationException,因为这里持续运行的代码是可以被取消的。通常,这并不是一个问题,所有良好的关闭操作(关闭一个文件、取消一个作业、或是关闭任何一种通信通道)通常都是非阻塞的,并且不会调用任何挂起函数。然而,在真实的案例中,当你需要挂起一个被取消的协程,你可以将相应的代码包装在 withContext(NonCancellable) {……} 中,并使用 withContext 函数以及 NonCancellable 上下文,见如下示例所示:
import kotlinx.coroutines.*
fun main() = runBlocking {
//sampleStart
val job = launch {
try {
repeat(1000) { i ->
println("job: I'm sleeping $i ...")
delay(500L)
}
} finally {
withContext(NonCancellable) {
println("job: I'm running finally")
delay(1000L)
println("job: And I've just delayed for 1 sec because I'm non-cancellable")
}
}
}
delay(1300L) // 延迟一段时间
println("main: I'm tired of waiting!")
job.cancelAndJoin() // 取消该作业并等待它结束
println("main: Now I can quit.")
//sampleEnd
}八、协程的异常
协程是一段顺序执行的代码,但是常规的try..catch很难捕获所有异常,因为期间的部分协程域代码可能跨线程执行不能catch到。这其中涉及到了很多方面,包括 异常的传递 ,结构化并发下的异常处理 ,异常的传播方式 ,不同的Job 等,所以常常让很多(特别是刚使用协程的,也不乏老手)同学摸不着头脑。
常见有如下两种处理方式:但这两种方式(特别是第二种)到底该什么时候用,用在哪里,却是一个问题?
try catchCoroutineExceptionHandler
try catch 虽然直接,一定程度上也帮我们规避了很多使用方面的问题,但同时也埋下了很多坑,也就是说,并不是所有协程的异常都可以 try 住(取决于使用位置),其也不是任何场景的最优解
8.1 异常传播形式
在协程中,异常的传播形式有两种:
- 一种是自动传播( 对应
launch或actor),异常传递过程是层层向上传递(如果异常没有被捕获) - 一种是向用户暴漏该异常(
async或produce),异常将不会向上传递,会在调用处直接暴漏,依赖用户来最终消费异常,例如通过 await 或 receive
可以通过一个使用 GlobalScope 创建根协程的简单示例来进行演示:
GlobalScope is a delicate API that can backfire in non-trivial ways. Creating a root coroutine for the whole application is one of the rare legitimate uses for GlobalScope, so you must explicitly opt-in into using GlobalScope with @OptIn(DelicateCoroutinesApi::class).
import kotlinx.coroutines.*
//sampleStart
@OptIn(DelicateCoroutinesApi::class)
fun main() = runBlocking {
val job = GlobalScope.launch { // launch 根协程
println("Throwing exception from launch")
throw IndexOutOfBoundsException() // 我们将在控制台打印 Thread.defaultUncaughtExceptionHandler
}
try {
job.join()
}catch (e: ArithmeticException) {
println("Caught IndexOutOfBoundsException")//没有打印, 没用
}
println("Joined failed job")
val deferred = GlobalScope.async { // async 根协程
println("Throwing exception from async")
throw ArithmeticException() // 没有打印任何东西,依赖用户去调用等待
}
try {
deferred.await()
println("Unreached")
} catch (e: ArithmeticException) {
println("Caught ArithmeticException")
}
}
//sampleEnd这段代码的输出如下(调试):
Throwing exception from launch
Exception in thread "DefaultDispatcher-worker-1 @coroutine#2" java.lang.IndexOutOfBoundsException
Joined failed job
Throwing exception from async
Caught ArithmeticException8.2 异常传播流程
|
类型 |
产生方式 |
异常传播特征 |
|
顶级作用域 |
1.根协程之间。 2.GlobalScope嵌套GlobalScope彼此独立互不影响。 3.A和B是两个作用域对象,A开启的作用域中B开启了作用域,两个作用域彼此独立互不影响。4.supervisorScope() 或 supervisorJob 由于使用了新的 Job,相当于是一个独立的根协程,与外部互不影响。 |
异常不向外传播。异常到达顶级作用域后,如果还没有被处理,会抛给当前的exceptionHandler,如果没有则给当前线程的uncaughtExceptionHandler |
|
协同作用域 |
Job嵌套、coroutineScope创建 |
异常双传播。异常会向上向下双向传播。 |
|
主从作用域 |
可通过supervisorScope创建,另外MainScope和lifecycleScope内部设置了 |
异自上而下单项传播。父协程不去受理子协程产生的异常。但是一旦父布局出现了异常,则会直接取消子协程。 |
协同作用域的异常传播流程
默认情况下,任意一个协程发生异常时都会影响到整个协程树。当协程因出现异常失败时,它会将异常传播到它的父级,父级会取消其余的子协程,同时取消自身的执行。最后将异常在传播给它的父级。当异常到达当前层次结构的根,在当前协程作用域启动的所有协程都将被取消。Parent的处理整体流程如下:
- 先 cancel 子协程
- 取消自己
- 将异常传递给父协程
- (重复上述过程,直到根协程关闭)

举个例子,比如下面这段代码:在上图中,我们创建了 两个子协程A,B,并在 A中 抛出异常,查看结果所示, 当子协程A异常被终止时,我们的子协程B与父协程都受到影响被终止。
import kotlinx.coroutines.*
fun main() =runBlocking<Unit> {
launch(Dispatchers.Default){
println("协程开始 in thread ${Thread.currentThread().name}")
val jobA = launch{
println("子协程A开始 in thread ${Thread.currentThread().name}")
delay(10)
println("子协程A抛出异常 in thread ${Thread.currentThread().name}")
throw NullPointerException("异常测试")
}
val jobB =launch{
println("子协程B始 in thread ${Thread.currentThread().name}")
delay(30)
println("子协程B结束in thread ${Thread.currentThread().name}")
}
jobA.join()
jobB.join()
println("父协程: 我还没打印呢...")
}
}
协程开始 in thread main @coroutine#1
子协程A开始 in thread main @coroutine#2
子协程B始 in thread main @coroutine#3
子协程A抛出异常 in thread main @coroutine#2
Exception in thread "main" java.lang.NullPointerException: 异常测试
at FileKt$main$1$1.invokeSuspend (File.kt:11)
at kotlin.coroutines.jvm.internal.BaseContinuationImpl.resumeWith (ContinuationImpl.kt:33)
at kotlinx.coroutines.DispatchedTaskKt.resume (DispatchedTask.kt:235) 主从作用域的传播流程
supervisorJob 是一个特殊的Job,其会改变异常的传递方式,当使用它时,我们子协程的失败不会影响到其他子协程与父协程,通俗点理解就是:子协程会自己处理异常,并不会影响其兄弟协程或者父协程,如下图所示:

8.3 异常处理方式
tryCatch
一般而言, tryCath 是我们最常见的处理异常方式,如下所示:
kotlin
代码解读
复制代码fun main() = runBlocking {
launch {
try {
throw NullPointerException()
} catch (e: Exception) {
e.printStackTrace()
}
}
println("嘿害哈")
}当异常发生时,我们底部的输出依然能正常打印,这也不难理解,就像我们在 Android 或者 Java 中的使用一样。但有些时候这种方式并不一定能有效,我们在下面中会专门提到。但大多数情况下,tryCatch 依然如万金油一般,稳定且可靠。
协程异常捕获器 CoroutineExceptionHandler
其是用于在协程中全局捕获异常行为的最后一种机制,你可以理解为,类似 Thread.uncaughtExceptionHandler 一样。你无法从 CoroutineExceptionHandler 的异常中恢复。当调用处理者的时候,协程已经完成并带有相应的异常。通常,该处理者用于记录异常,显示某种错误消息,终止和(或)重新启动应用程序。
public interface CoroutineExceptionHandler : CoroutineContext.Element {
public companion object Key : CoroutineContext.Key<CoroutineExceptionHandler>
public fun handleException(context: CoroutineContext, exception: Throwable)
}
譬如
import kotlinx.coroutines.*
@OptIn(DelicateCoroutinesApi::class)
fun main() {
val exceptionHandler = CoroutineExceptionHandler { coroutineContext, throwable ->
println("exceptionHandler ${coroutineContext[CoroutineName]} :$throwable")
}
GlobalScope.launch(CoroutineName("异常处理") + exceptionHandler){
val job = launch{
println("${Thread.currentThread().name} 我要开始抛异常了" )
throw NullPointerException("异常测试")
}
println("${Thread.currentThread().name} end")
}
}
DefaultDispatcher-worker-1 @异常处理#1 end
DefaultDispatcher-worker-2 @异常处理#2 我要开始抛异常了
exceptionHandler CoroutineName(异常处理) :java.lang.NullPointerException: 异常测试
再譬如子协程Ajob的异常被父协程处理了,无论我下面开启多少个子协程产生异常,最终都是被父协程处理。但是有个问题是:因为异常会导致父协程被取消执行,同时导致后续的所有子协程都没有执行完成(可能偶尔有个别会执行完)
import kotlinx.coroutines.*
fun main() {
val exceptionHandler = CoroutineExceptionHandler { coroutineContext, throwable ->
println("exceptionHandler ${coroutineContext[CoroutineName]} 处理异常 :$throwable")
}
GlobalScope.launch(CoroutineName("父协程") + exceptionHandler){
val job = launch(CoroutineName("子协程A")) {
println("${Thread.currentThread().name} 我要开始抛异常了" )
for (index in 0..10){
launch(CoroutineName("孙子协程$index")) {
println("${Thread.currentThread().name} ${coroutineContext[CoroutineName]}" )
}
}
throw NullPointerException("空指针异常")
}
for (index in 0..10){
launch(CoroutineName("子协程$index")) {
println("${Thread.currentThread().name} ${coroutineContext[CoroutineName]}" )
}
}
try {
job.join()
} catch (e: Exception) {
e.printStackTrace()
}
println("${Thread.currentThread().name} end")
}
}
DefaultDispatcher-worker-2 @子协程A#2 我要开始抛异常了
DefaultDispatcher-worker-1 @子协程10#13 CoroutineName(子协程10)
DefaultDispatcher-worker-1 @子协程0#3 CoroutineName(子协程0)
DefaultDispatcher-worker-1 @子协程1#4 CoroutineName(子协程1)
DefaultDispatcher-worker-1 @子协程2#5 CoroutineName(子协程2)
DefaultDispatcher-worker-1 @子协程3#6 CoroutineName(子协程3)
DefaultDispatcher-worker-1 @子协程4#7 CoroutineName(子协程4)
DefaultDispatcher-worker-2 @父协程#1 end exceptionHandler CoroutineName(父协程) 处理异常 :java.lang.NullPointerException: 空指针异常如果有一个页面,它最终展示的数据,是通过请求多个服务器接口的数据拼接而成的,而其中某一个接口出问题都将不进行数据展示,而是提示加载失败。那么你就可以使用上面的方案去做,都不用管它们是谁报的错,反正都是统一处理,一劳永逸。类似这样的例子我们在开发中应该经常遇到。
异常捕获遵循异常传播形式和传播流程
- 【遵循传播形式的差异】
- 【遵循传播流程的差异】
-
- 针对顶层作用域,异常不向外传播。异常到达顶级作用域后,如果还没有被处理,会抛给当前的exceptionHandler,如果没有则给当前线程的uncaughtExceptionHandler
- 针对协同作用域的传播流程,当子协程发生异常时,它会优先将异常委托给父协程区处理,以此类推
直到根协程作用域或者顶级协程。因此其永远不会使用我们子协程CoroutineContext传递的CoroutineExceptionHandler(SupervisorJob除外) - 在监督作用域内运行的协程不会将异常传播到其父协程,并且会从此规则中排除。本文档的另一个小节——监督提供了更多细节。
import kotlinx.coroutines.*
@OptIn(DelicateCoroutinesApi::class)
fun main() = runBlocking {
//sampleStart
val handler = CoroutineExceptionHandler { _, exception ->
println("CoroutineExceptionHandler got $exception")
}
val job = GlobalScope.launch(handler) { // 根协程,运行在 GlobalScope 中
throw AssertionError()
}
val deferred = GlobalScope.async(handler) { // 同样是根协程,但使用 async 代替了 launch
throw ArithmeticException() // 没有打印任何东西,依赖用户去调用 deferred.await()
}
joinAll(job, deferred)
//sampleEnd
}
输出
CoroutineExceptionHandler got java.lang.AssertionError8.4 超时异常
withTimeout( ) 创建新协程
- 异常:会连锁取消子协程、兄弟协程和父协程。
- 上下文:继承上下文
- 使用场景:超时未执行完会抛异常,并返回一个值。超时抛出的TimeoutCancellationException是CancellationException子类,因此不会影响其他协程。
withTimeoutOrNull( ) 创建新协程
- 异常:子协程异常会连锁取消其它子协程和自己。
- 上下文:继承上下文
- 使用场景:超时未执行完不抛异常,返回null。用来包装那些出现异常后会一直等待的操作,例如网络操作等待结果超过5s后不太可能会收到结果了
在实践中绝大多数取消一个协程的理由是它有可能超时。 当你手动追踪一个相关 Job 的引用并启动了一个单独的协程在延迟后取消追踪,这里已经准备好使用 withTimeout 函数来做这件事。 来看看示例代码:
import kotlinx.coroutines.*
fun main() = runBlocking {
//sampleStart
withTimeout(1300L) {
repeat(1000) { i ->
println("I'm sleeping $i ...")
delay(500L)
}
}
//sampleEnd
}运行后得到如下输出:
I'm sleeping 0 ...
I'm sleeping 1 ...
I'm sleeping 2 ...
Exception in thread "main" kotlinx.coroutines.TimeoutCancellationException: Timed out waiting for 1300 mswithTimeout 抛出了 TimeoutCancellationException,它是 CancellationException 的子类。 我们之前没有在控制台上看到堆栈跟踪信息的打印。这是因为在被取消的协程中 CancellationException 被认为是协程执行结束的正常原因。 然而,在这个示例中我们在 main 函数中正确地使用了 withTimeout。
由于取消只是一个例外,所有的资源都使用常用的方法来关闭。 如果你需要做一些各类使用超时的特别的额外操作,可以使用类似 withTimeout 的 withTimeoutOrNull 函数,并把这些会超时的代码包装在 try {...} catch (e: TimeoutCancellationException) {...} 代码块中,而 withTimeoutOrNull 通过返回 null 来进行超时操作,从而替代抛出一个异常:
import kotlinx.coroutines.*
fun main() = runBlocking {
//sampleStart
val result = withTimeoutOrNull(1300L) {
repeat(1000) { i ->
println("I'm sleeping $i ...")
delay(500L)
}
"Done" // 在它运行得到结果之前取消它
}
println("Result is $result")
//sampleEnd
}运行这段代码时不再抛出异常:
I'm sleeping 0 ...
I'm sleeping 1 ...
I'm sleeping 2 ...
Result is null九、通道Channel
一个 Channel 是一个和 BlockingQueue 非常相似的概念。其中一个不同是它代替了阻塞的 put 操作并提供了挂起的 send,还替代了阻塞的 take 操作并提供了挂起的 receive。
import kotlinx.coroutines.*
import kotlinx.coroutines.channels.*
fun main() = runBlocking {
//sampleStart
val channel = Channel<Int>()
launch {
// 这里可能是消耗大量 CPU 运算的异步逻辑,
// 我们将仅仅做 5 次整数的平方并发送
for (x in 1..5) channel.send(x * x)
}
// 这里我们打印了 5 次被接收的整数:
repeat(5) { println(channel.receive()) }
println("Done!")
//sampleEnd
}可以在这里获取完整代码。
这段代码的输出如下:
1
4
9
16
25
Done!9.1 关闭与迭代通道
和队列不同,一个通道可以通过被关闭来表明没有更多的元素将会进入通道。 在接收者中可以定期的使用 for 循环来从通道中接收元素。
从概念上来说,一个 close 操作就像向通道发送了一个特殊的关闭指令。 这个迭代停止就说明关闭指令已经被接收了。所以这里保证所有先前发送出去的元素都在通道关闭前被接收到。
import kotlinx.coroutines.*
import kotlinx.coroutines.channels.*
fun main() = runBlocking {
//sampleStart
val channel = Channel<Int>()
launch {
for (x in 1..5) channel.send(x * x)
channel.close() // 我们结束发送
}
// 这里我们使用 `for` 循环来打印所有被接收到的元素(直到通道被关闭)
for (y in channel) println(y)
println("Done!")
//sampleEnd
}9.2 构建通道生产者
协程生成一系列元素的模式很常见。 这是 生产者——消费者 模式的一部分,并且经常能在并发的代码中看到它。 你可以将生产者抽象成一个函数,并且使通道作为它的参数,但这与必须从函数中返回结果的常识相违悖。
这里有一个名为 produce 的便捷的协程构建器,可以很容易的在生产者端正确工作, 并且我们使用扩展函数 consumeEach 在消费者端替代 for 循环:
import kotlinx.coroutines.*
import kotlinx.coroutines.channels.*
//sampleStart
fun CoroutineScope.produceSquares(): ReceiveChannel<Int> = produce {
for (x in 1..5) send(x * x)
}
fun main() = runBlocking {
val squares = produceSquares()
squares.consumeEach { println(it) }
println("Done!")
//sampleEnd
}十、Android中的协程
10.1 UI线程下的麻烦调用
private fun start() {
GlobalScope.launch{
launch {
//网络请求1...
throw NullPointerException("空指针")
}
val result = withContext(Dispatchers.IO) {
//网络请求2...
requestData()
"请求结果"
}
btn.text = result
launch {
//网络请求3...
}
}
}
- 因为我们的
GlobalScope默认使用的是Dispatchers.Default,这会导致我们在非主线程上刷新UI。 - 子协程产生异常会产生相互干扰。子协程异常取消会导致父协程取消,同时其他子协程也将会被取消。
- 如果我们这个时候
activity或者framgent退出,因为协程是在GlobalScope中运行,所以即使activity或者framgent退出,这个协程还是在运行,这个时候会产生各种泄露问题。同时此协程当执行到刷新操作时,因为我们的界面已经销毁,这个时候执行UI刷新将会产生崩溃。
如果我们要解决上面的问题。我们得这么做:
- 我们先需要通过
launch启动时加入Dispatchers.Main来保证我们是在主线程刷新UI - 同时还需要再
GlobalScope.launch的协程上下文中加入SupervisorJob来避免子协程的异常取消会导致整个协程树被终结。 - 最后我们还得把
每次通过GlobalScope启动的Job保存下来,在activity或者framgent退出时调用job.cancel取消整个协程树
var job:Job? = null
private fun start() {
job = GlobalScope.launch(Dispatchers.Main + SupervisorJob()) {
launch {
throw NullPointerException("空指针")
}
val result = withContext(Dispatchers.IO) {
//网络请求...
"请求结果"
}
launch {
//网络请求3...
}
btn.text = result
}
}
override fun onDestroy() {
super.onDestroy()
job?.cancel()
}或者
MainScope的创建默认就使用了SupervisorJob和Dispatchers.Main。说明我们可以通过MainScope来处理UI组件刷新。同时由于MainScope采用的是SupervisorJob,所以我们各个子协程中的异常导致的取消操作并不会导致MainScope的取消- 但是还需要及时的取消
private val mainScope = MainScope()
private fun start() {
mainScope.launch {
launch {
throw NullPointerException("空指针")
}
val result = withContext(Dispatchers.IO) {
//网络请求...
"请求结果"
}
launch {
//网络请求3...
}
btn.text = result
}
}
override fun onDestroy() {
super.onDestroy()
mainScope.cancel()
}
10.2 在Activity与Framgent中使用协程
implementation "androidx.lifecycle:lifecycle-runtime-ktx:2.3.1"
- 这个时候我们就可以在
activity或者framgent直接使用lifecycleScope进行启动协程
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
lifecycleScope.launch {
delay(2000)
Toast.makeText(this@MainActivity,"haha",Toast.LENGTH_SHORT).show()
}
}
}
- 同时我们也可以通过
launchWhenCreated、launchWhenStarted、launchWhenResumed来启动协程,等到lifecycle处于对应状态时自动触发此处创建的协程。
比如我们可以这么操作:
class MainTestActivity : AppCompatActivity() {
init {
lifecycleScope.launchWhenResumed {
Log.d("init", "在类初始化位置启动协程")
}
}
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
}
}
D/onResume: onResume
D/init: 在类初始化位置启动协程lifecycleScope原理
#lifecycleScope它是通过lifecycle得到一个coroutineScope
#,是一个LifecycleCoroutineScope对象
public val LifecycleOwner.lifecycleScope: LifecycleCoroutineScope
get() = lifecycle.coroutineScope
#lifecycleScope采用的和MainScope一样的创建CoroutineScope
#它又通过结合lifecycle来实现当lifecycle状态处于DESTROYED状态的时候自动关闭所有的协程。
public val Lifecycle.coroutineScope: LifecycleCoroutineScope
get() {
while (true) {
val existing = mInternalScopeRef.get() as LifecycleCoroutineScopeImpl?
if (existing != null) {
return existing
}
val newScope = LifecycleCoroutineScopeImpl(
this,
SupervisorJob() + Dispatchers.Main.immediate
)
if (mInternalScopeRef.compareAndSet(null, newScope)) {
newScope.register()
return newScope
}
}
}
public abstract class LifecycleCoroutineScope internal constructor() : CoroutineScope {
internal abstract val lifecycle: Lifecycle
public fun launchWhenCreated(block: suspend CoroutineScope.() -> Unit): Job = launch {
lifecycle.whenCreated(block)
}
public fun launchWhenStarted(block: suspend CoroutineScope.() -> Unit): Job = launch {
lifecycle.whenStarted(block)
}
public fun launchWhenResumed(block: suspend CoroutineScope.() -> Unit): Job = launch {
lifecycle.whenResumed(block)
}
}
internal class LifecycleCoroutineScopeImpl(
override val lifecycle: Lifecycle,
override val coroutineContext: CoroutineContext
) : LifecycleCoroutineScope(), LifecycleEventObserver {
init {
if (lifecycle.currentState == Lifecycle.State.DESTROYED) {
coroutineContext.cancel()
}
}
fun register() {
launch(Dispatchers.Main.immediate) {
if (lifecycle.currentState >= Lifecycle.State.INITIALIZED) {
lifecycle.addObserver(this@LifecycleCoroutineScopeImpl)
} else {
coroutineContext.cancel()
}
}
}
override fun onStateChanged(source: LifecycleOwner, event: Lifecycle.Event) {
if (lifecycle.currentState <= Lifecycle.State.DESTROYED) {
lifecycle.removeObserver(this)
coroutineContext.cancel()
}
}
}
launchWhenResumed的实现
实际上是调用了whenStateAtLeast,同时使用了withContext进行了一个同步操作。然后在LifecycleController中通过添加LifecycleObserver来监听状态,通过lifecycle当前状态来对比我们设定的触发状态,最终决定是否恢复执行
public suspend fun <T> Lifecycle.whenResumed(block: suspend CoroutineScope.() -> T): T {
return whenStateAtLeast(Lifecycle.State.RESUMED, block)
}
public suspend fun <T> Lifecycle.whenStateAtLeast(
minState: Lifecycle.State,
block: suspend CoroutineScope.() -> T
): T = withContext(Dispatchers.Main.immediate) {
val job = coroutineContext[Job] ?: error("when[State] methods should have a parent job")
val dispatcher = PausingDispatcher()
val controller =
LifecycleController(this@whenStateAtLeast, minState, dispatcher.dispatchQueue, job)
try {
withContext(dispatcher, block)
} finally {
controller.finish()
}
}
@MainThread
internal class LifecycleController(
private val lifecycle: Lifecycle,
private val minState: Lifecycle.State,
private val dispatchQueue: DispatchQueue,
parentJob: Job
) {
private val observer = LifecycleEventObserver { source, _ ->
if (source.lifecycle.currentState == Lifecycle.State.DESTROYED) {
handleDestroy(parentJob)
} else if (source.lifecycle.currentState < minState) {
dispatchQueue.pause()
} else {
dispatchQueue.resume()
}
}
init {
if (lifecycle.currentState == Lifecycle.State.DESTROYED) {
handleDestroy(parentJob)
} else {
lifecycle.addObserver(observer)
}
}
private inline fun handleDestroy(parentJob: Job) {
parentJob.cancel()
finish()
}
@MainThread
fun finish() {
lifecycle.removeObserver(observer)
dispatchQueue.finish()
}
}
十一、协程调试
11.1 命名协程以用于调试
当协程经常打印日志并且你只需要关联来自同一个协程的日志记录时, 则自动分配的 id 是非常好的。然而,当一个协程与特定请求的处理相关联时或做一些特定的后台任务,最好将其明确命名以用于调试目的。 CoroutineName 上下文元素与线程名具有相同的目的。当调试模式开启时,它被包含在正在执行此协程的线程名中。
下面的例子演示了这一概念:
import kotlinx.coroutines.*
fun log(msg: String) = println("[${Thread.currentThread().name}] $msg")
fun main() = runBlocking(CoroutineName("main")) {
//sampleStart
log("Started main coroutine")
// 运行两个后台值计算
val v1 = async(CoroutineName("v1coroutine")) {
delay(500)
log("Computing v1")
6
}
val v2 = async(CoroutineName("v2coroutine")) {
delay(1000)
log("Computing v2")
7
}
log("The answer for v1 * v2 = ${v1.await() * v2.await()}")
//sampleEnd
}可以在这里获取完整代码。
程序执行使用了 -Dkotlinx.coroutines.debug JVM 参数,输出如下所示:
[main @main#1] Started main coroutine
[main @v1coroutine#2] Computing v1
[main @v2coroutine#3] Computing v2
[main @main#1] The answer for v1 * v2 = 4211.2 组合上下文中的元素
有时我们需要在协程上下文中定义多个元素。我们可以使用 + 操作符来实现。 比如说,我们可以显式指定一个调度器来启动协程并且同时显式指定一个命名:
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
//sampleStart
launch(Dispatchers.Default + CoroutineName("test")) {
println("I'm working in thread ${Thread.currentThread().name}")
}
//sampleEnd
}
十二、其他
12.1 suspendCoroutine
suspendCoroutine 是 Kotlin 协程中用于将回调式 API 转换为 suspend 函数的工具。它允许我们将基于回调的代码转换为协程风格的代码。
基本使用示例:
kotlin
// 1. 基本用法
suspend fun simpleExample(): String = suspendCoroutine { continuation ->
// 在这里执行异步操作
continuation.resume("结果") // 成功时调用
// 或者
continuation.resumeWithException(Exception("错误")) // 失败时调用
}
// 2. 将回调转换为 suspend 函数
suspend fun callbackToSuspend(): Result = suspendCoroutine { continuation ->
traditionalCallback { result, error ->
if (error != null) {
continuation.resumeWithException(error)
} else {
continuation.resume(result)
}
}
}
// 3. 实际应用示例 - 将Android点击事件转换为挂起函数
suspend fun View.awaitClick() = suspendCoroutine<Unit> { continuation ->
setOnClickListener {
continuation.resume(Unit)
}
}
开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐

 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)