kmp openharmony 直方图分桶与热度带分析
本文介绍了一个基于Kotlin Multiplatform(KMP)与OpenHarmony实现的直方图分桶分析工具,用于性能指标分析。该工具支持输入数值样本和桶数量,自动计算桶宽并统计各区间的样本数量与占比,最终生成包含文本条模拟"热度带"的可视化报告。文章详细阐述了直方图在接口耗时、请求体大小等场景的应用价值,并提供了Kotlin核心算法实现,包括数据解析、分桶计算和结果展
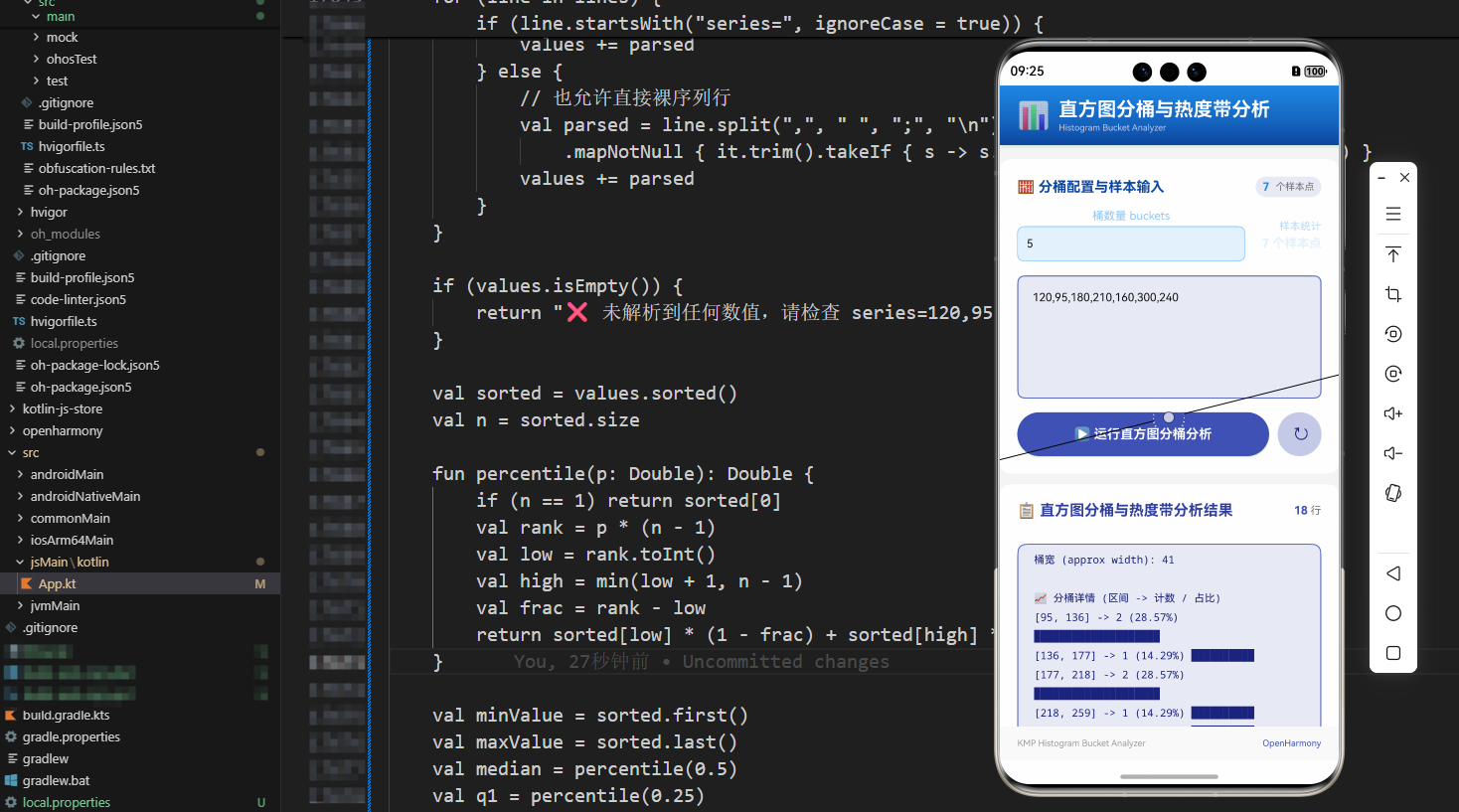
在接口耗时、请求体大小、数据库响应时间等指标分析中,除了看平均值和分位数,我们还常常需要一个更“形象”的工具——直方图:
指标值主要集中在哪个区间?
是否存在明显的“长尾区间”?
中间的“热区”大概覆盖了多少请求?
本案例基于 Kotlin Multiplatform(KMP)与 OpenHarmony,实现了一个直方图分桶与热度带分析器:
- 输入一串数值样本和桶数量
buckets; - 根据整体最小值 / 最大值自动计算桶宽;
- 统计每个区间的样本个数与占比;
- 使用文本条模拟“热度带”,在 ArkTS 终端上直观展示分布形态。
一、问题背景与典型场景
在 AIOps 与性能分析场景中,直方图非常适合回答“分布型”问题:
-
接口耗时直方图
希望知道大部分请求的耗时集中在哪个区间(例如 50~150ms),以及是否存在 500ms 以上的明显长尾。 -
请求体 / 响应体大小分布
分析 API 的请求/响应大小是否集中在合理范围,还是存在大量超大包体影响链路性能。 -
数据库查询耗时分布
将 SQL 查询耗时做直方图分桶,看是否存在某个时长段(例如 800~1000ms)集中爆发。 -
任务执行时间分布
对批处理任务的执行耗时做分桶,一眼看出“多数任务很快完成,少数任务严重拖后腿”。
这些问题可以统一抽象为:
给定数值样本集合 \( x_0, x_1, \dots, x_{n-1} \) 与桶数量 \( k \),
将区间 \([\min x, \max x]\) 均分为 \( k \) 个子区间,统计每个子区间内的样本数量与占比。
二、Kotlin 直方图分桶分析引擎
1. 输入格式设计
为与现有案例保持一致,本案例使用如下文本格式:
buckets=5
series=120,95,180,210,160,300,240
buckets:桶数量,例如 5 表示将整个取值范围均分为 5 个区间;series:一串以,/ 空格 /;/ 换行分隔的数值样本。
也支持直接裸写一行数值,例如:
120,95,180,210,160,300,240
解析逻辑会尝试从每行提取所有可转换为 Double 的值。
2. Kotlin 分析主入口
在 App.kt 中,我们定义了对外暴露的直方图分析函数,并通过 @JsExport 让 OpenHarmony 端可以直接调用:
@JsExport
fun histogramBucketAnalyzer(inputData: String): String {
val sanitized = inputData.trim()
if (sanitized.isEmpty()) {
return "❌ 输入为空,请按 buckets=5\\nseries=120,95,180,... 形式提供数据"
}
val lines = sanitized.lines()
.map { it.trim() }
.filter { it.isNotEmpty() }
var bucketCount: Int? = null
val values = mutableListOf<Double>()
for (line in lines) {
when {
line.startsWith("buckets=", ignoreCase = true) -> {
bucketCount = line.substringAfter("=").trim().toIntOrNull()
}
line.startsWith("series=", ignoreCase = true) -> {
val parsed = line.substringAfter("=")
.split(",", " ", ";", "\n")
.mapNotNull { it.trim().takeIf { s -> s.isNotEmpty() }?.toDoubleOrNull() }
values += parsed
}
else -> {
val parsed = line.split(",", " ", ";", "\n")
.mapNotNull { it.trim().takeIf { s -> s.isNotEmpty() }?.toDoubleOrNull() }
values += parsed
}
}
}
if (values.isEmpty()) {
return "❌ 未解析到任何数值,请检查 series=120,95,180,... 的格式是否正确"
}
if (bucketCount == null || bucketCount!! <= 0) {
return "❌ 未找到合法的 buckets=... 配置,请提供大于 0 的桶数量"
}
val n = values.size
val sorted = values.sorted()
val minValue = sorted.first()
val maxValue = sorted.last()
if (minValue == maxValue) {
return "ℹ️ 所有样本值相同 ($minValue),直方图无法有效分桶,可直接视为单点分布"
}
val k = bucketCount!!
val width = (maxValue - minValue) / k
val counts = IntArray(k)
for (v in values) {
var idx = ((v - minValue) / width).toInt()
if (idx >= k) idx = k - 1 // 将最大值归入最后一个桶
if (idx < 0) idx = 0
counts[idx]++
}
val builder = StringBuilder()
builder.appendLine("📊 直方图分桶与热度带分析报告")
builder.appendLine("━━━━━━━━━━━━━━━━━━━━━━━━━━━━")
builder.appendLine("样本数量: $n")
builder.appendLine("桶数量 (buckets): $k")
builder.appendLine("最小值 / 最大值: $minValue / $maxValue")
builder.appendLine("桶宽 (approx width): ${round2(width)}")
builder.appendLine()
// 构建每个桶的区间和占比
builder.appendLine("📈 分桶详情 (区间 -> 计数 / 占比)")
var maxBucketCount = 0
counts.forEach { if (it > maxBucketCount) maxBucketCount = it }
for (i in 0 until k) {
val start = minValue + i * width
val end = if (i == k - 1) maxValue else minValue + (i + 1) * width
val count = counts[i]
val ratio = if (n > 0) count.toDouble() / n * 100 else 0.0
// 用简单的文本条模拟热度条(最多 20 个块)
val barLength = if (maxBucketCount == 0) 0 else (count * 20 / maxBucketCount)
val bar = "█".repeat(barLength)
builder.appendLine("[${round2(start)}, ${round2(end)}] -> $count (${round2(ratio)}%) $bar")
}
builder.appendLine()
builder.appendLine("🧠 工程化解读")
builder.appendLine("- 直方图可以帮助快速识别“主要集中区间”和“长尾区间”;")
builder.appendLine("- 桶数量过小会导致细节丢失,过大又会导致噪声增加,建议在 5~20 之间调整;")
builder.appendLine("- 可以将高热度区间与 P95/P99 等分位数结合,构建更直观的耗时画像。")
return builder.toString().trim()
}
这里采用了最常见的“等宽直方图”实现方案:
- 先对样本排序,得到整体最小值
minValue与最大值maxValue; - 桶宽
width = (maxValue - minValue) / k; - 对每个样本,根据 \( \lfloor (x - \min)/width \rfloor \) 计算桶索引,并做边界保护(最大值归入最后一桶);
- 统计每个桶的数量与占比,并额外构造一个简单的“文本热度条”。
三、OpenHarmony 侧调用与 UI 展示思路
在 ArkTS 页面中,可以像之前案例一样导入该分析函数:
import { histogramBucketAnalyzer } from './hellokjs'
页面状态设计建议:
bucketCount: 桶数量(推荐默认5或10);seriesInput: 样本数据输入,多行TextArea支持series=或裸值两种形式。
调用时拼接 payload:
const seriesLine = this.seriesInput.includes('series=') ? this.seriesInput : `series=${this.seriesInput}`
const payload = `buckets=${this.bucketCount}\n${seriesLine}`
this.result = histogramBucketAnalyzer(payload)
展示区域可以:
- 使用等宽字体显示报告;
- 对“📈 分桶详情”部分做适当缩进;
- 利用
█条形的长度体现每个桶的热度,在终端上形成类似“文字版热度图”的效果。
如果后续需要更强的可视化能力,可以在 ArkTS 中根据每个桶的占比绘制水平条形图或简单的柱状图。
四、复杂度与工程实践建议
当前直方图实现的复杂度主要包括:
- 排序:\( O(n \log n) \);
- 分桶统计:\( O(n) \);
- 输出构造:\( O(k) \)。
整体复杂度约为 \( O(n \log n) \),对终端侧常见数据规模来说是可以接受的。
在实际工程中,可以考虑进一步的扩展和优化:
-
动态桶宽或自适应分桶
针对分布极不均匀的场景,可以尝试等频分桶(每个桶样本数接近)或基于分位数的自适应分桶。 -
与分位数/箱线图联动
将本案例与“分位数与箱线图”案例组合:在直方图上标记 P50 / P90 / P95 / P99 所落入的桶,帮助快速定位“关键分位数所在热区”。 -
多维分桶分析
在服务端先按接口 / 服务 / 区域等维度聚合,再在终端侧对每个维度生成自己的直方图,构建多维分布画像。 -
端侧轻量分析
对于轻量版监控与边缘节点,可以直接在 OpenHarmony 端依赖本直方图算法做快速分布分析,而不必将原始样本全部上传到云端。
通过这个直方图分桶与热度带分析案例,你可以把“教科书上的直方图概念”真正落地到接口耗时、流量大小与任务耗时等工程场景中,
在资源有限的终端上也能以极低成本获得高可读性的分布洞察。
欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net

开源鸿蒙跨平台开发社区汇聚开发者与厂商,共建“一次开发,多端部署”的开源生态,致力于降低跨端开发门槛,推动万物智联创新。
更多推荐
 25
25 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)